在人工智能领域,模型的迭代速度已经快到让人应接不暇。几乎每周,我们都能见证新的技术突破和模型发布,尤其是在国内大模型厂商之间,一场贴身肉搏式的“军备竞赛”正愈演愈烈。然而,当“最强”、“SOTA”这些词汇频繁轰炸我们的感官时,从业者和爱好者们也逐渐产生了一丝“审美疲劳”。但就在最近,智谱AI毫无预告地开源了一款名为 GLM-4.1V-Thinking 的新模型,它似乎正在用实力证明,这一次,真的“不一样”。
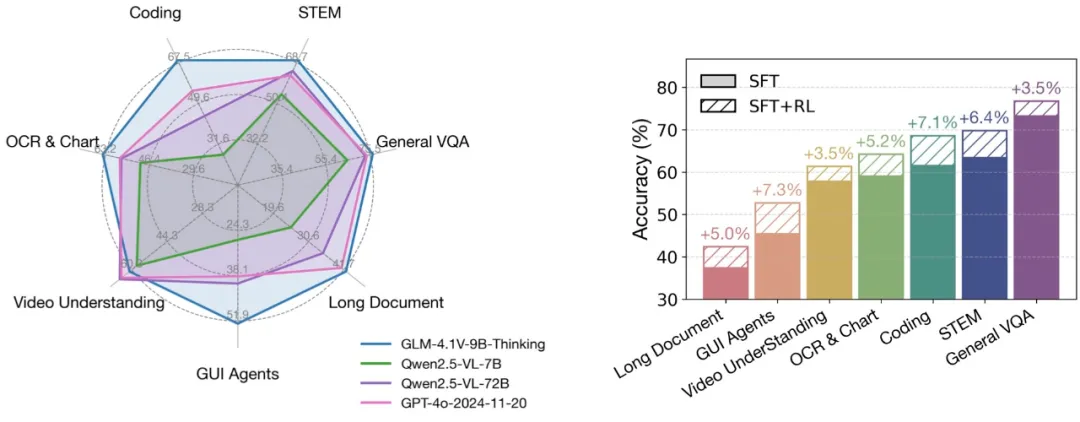
这款模型最引人注目的标签是:首个9B级别的通用多模态语言模型(VLM)。在动辄千亿参数的时代,9B的体量听起来似乎并不起眼。但令人震惊的是,它的性能表现却足以让许多“重量级选手”黯然失色。智谱官方数据显示,GLM-4.1V-Thinking在多达28项公开评测中,有23项登顶10B级别模型最佳,其中更有18项任务的表现媲美甚至超越了参数量为其8倍的Qwen-2.5-VL-72B。
这不禁让人心生疑问:这究竟是又一次的“参数竞赛”宣传,还是一场真正的技术革命?它“以小博大”的底气从何而来?带着这些问题,我们对GLM-4.1V-Thinking进行了深入的实测和技术探究,而结果,或许预示着一个新时代的到来——一个属于高效、低成本、本地化视觉Agent的时代。
颠覆性表现:不止是“以小博大”
衡量一个模型能力的,从来不应只有参数量。GLM-4.1V-Thinking最令人兴奋的突破,体现在其作为“视觉Agent”的惊人潜力上。
在业界公认的GUI Agents基准测试 WebVoyageSom 中,模型的任务是像人类一样,通过理解网页界面并执行点击、输入等一系列操作来完成特定任务。这项测试极度考验模型对人类意图的理解和将其转化为具体界面操作的能力。
在这个赛场上,GLM-4.1V-Thinking取得了 69.0 的高分,将包括GPT-4o(35.0分)在内的所有其他模型远远甩在身后。这不仅仅是一个数字的胜利,它标志着AI在与数字世界交互的层面上取得了重大进展。这意味着,我们距离开发出能够真正在本地电脑上自主操作浏览器、完成预订、数据整理、信息抓取等复杂任务的智能助理,又近了一大步。
此外,在视频理解领域,如图文并茂的 VideoMME、综合性的 MMVU 以及动态场景理解的 MVBench 等多项评测中,GLM-4.1V-Thinking同样实现了全面领先。相比静态图片,视频理解要求模型具备时序洞察力,能够捕捉和分析动态变化。一个仅有9B参数的模型能在这一领域取得如此成就,让我们看到了在终端设备上实现实时视觉分析的曙光。
真实场景下的“硬核”实测

基准测试的分数固然重要,但真实世界应用的表现才是检验模型价值的最终标准。为此,我们设计了几个贴近日常和专业场景的测试,来一探GLM-4.1V-Thinking的虚实。
测试一:复杂真实世界图像解读
我们首先向模型输入了一张在旅途中随手拍下的、包含外国车牌的汽车照片。这类图像的难点在于,它不仅包含主体(汽车),还混合了特定文化符号(车牌)、背景环境等复杂信息。
模型的反馈相当出色。它不仅准确识别出车辆品牌,更关键的是,它正确地指出了车牌属于泰国,并对车牌的样式和颜色进行了描述。虽然对于车牌背后的“含金量”分析尚有提升空间,但其精准的跨国知识与图像细节捕捉能力,足以应对绝大多数生活中的图像识别需求。
接着,我们又提供了一张从飞机上拍摄的、地貌急剧变化的照片——从平原到拔地而起的山脉。模型迅速分析后推断,这很可能是从华北平原或黄土高原飞往西南地区时常见的地貌分界线,如太行山脉。这种基于地理空间知识的推理能力,展示了它不仅仅是在“看图说话”,而是在进行深层次的理解与联想。
测试二:专业文档识别与分析
为了考验其在专业领域的应用潜力,我们使用了一张清晰度欠佳的体检报告单照片。在实际应用中,处理这类扫描质量不一、格式复杂的文档是一大痛点。
GLM-4.1V-Thinking的表现堪称惊艳。它不仅以极高的准确率识别出了报告单上的所有项目和数值,甚至超越了许多更大模型在类似任务上的表现。更具价值的是,它并未止步于数据提取,而是基于识别出的异常指标,给出了一些中肯的营养摄入和生活方式建议。对于一个9B的小模型而言,能做到如此程度的精准识别和初步解读,其在医疗、金融、法律等文档处理领域的应用潜力不言而喻。
测试三:高难度动态视频理解
最后,我们进行了难度最高的测试:将前段时间在技术圈广为流传的谷歌Gemini CLI演示视频片段交给模型进行分析。这个视频的特点是:完全静音、操作节奏极快、信息密度极高。对于人类观众来说,不暂停、不回放,都很难完全跟上并理解其内容。
而GLM-4.1V-Thinking在没有声音辅助的情况下,对这段视频给出了逻辑清晰、内容详尽的分析和总结。它准确地描述了视频中演示的各项命令行操作,并理解了这些操作背后的目的。这充分证明了其强大的时序信息捕捉和动态事件理解能力,也让我们对它在视频内容摘要、监控分析、教学演示解读等方面的应用充满了期待。
揭秘背后:9B模型如何实现性能飞跃?
如此强大的性能,必然源于底层技术的革新。通过查阅其技术报告,我们发现GLM-4.1V-Thinking的“以小博大”,得益于智谱在模型架构和训练流程上的双重突破。
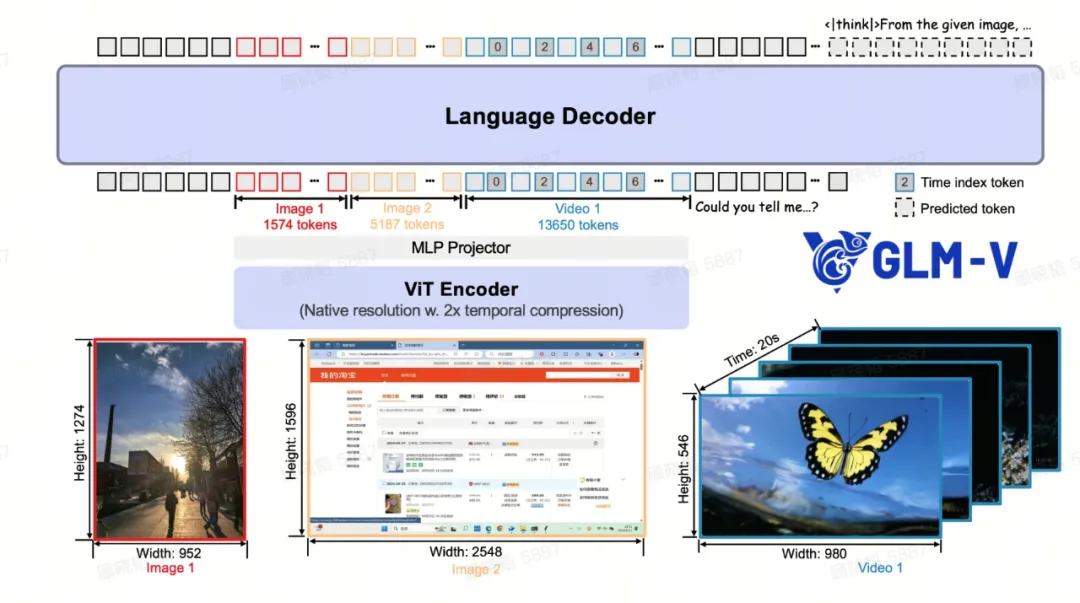
其核心架构由视觉编码器(ViT Encoder)、多层感知机适配器(MLP Projector)和语言解码器(Language Decoder)构成,并在多个关键环节进行了巧妙优化。
时序建模:让视频理解“活”起来 传统的VLM在处理视频时,往往像快速翻阅幻灯片,缺乏对“时间”的真正理解。GLM-4.1V在视觉编码器中,创新性地用 3D卷积 替换了2D卷积。这一改变带来了质的飞跃,模型不再孤立地看待每一帧,而是能捕捉帧与帧之间的动态关联,实现了2倍的时间压缩,显著提升了处理效率。同时,通过为每一帧画面精心设计并插入 “时间戳标记”,模型真正拥有了连贯的时间概念,从而能够理解长达2小时的视频内容。
打破限制:驾驭任意尺寸与分辨率 处理超长网页截图或4K高清大图时,普通模型常常会“水土不服”。GLM-4.1V通过两项关键技术攻克了这一难题:
- 2D-RoPE位置编码: 使其能够稳定处理超过200:1这种极端宽高比的图像,无论是横向长图还是纵向截屏,都能轻松应对。
- 动态位置嵌入插值: 无论输入图像被切割成多少个图块(patches),该技术都能通过“双三次插值”算法,为每个图块动态、平滑地分配精准的位置信息。这既保留了原始ViT预训练的强大能力,又赋予了模型处理任意分辨率图像的灵活性。
“智能私教”式训练:高效炼就超强能力 卓越的性能离不开高效的训练策略。GLM-4.1V-Thinking的训练分为预训练(Pretraining)、监督微调(SFT)和强化学习(RL)三个阶段。特别是在强化学习阶段,它采用了一种名为 “课程采样强化学习(RLCS)” 的先进方法。
这套方法就像是为模型聘请了一位经验丰富的智能私教。它不会一股脑地堆砌难题,而是遵循“循序渐进”的原则:先从简单的任务入手,让模型建立基础能力和“信心”;待模型掌握后,再逐步增加任务难度和复杂度,进行针对性的强化训练。这种“因材施教”的训练方式,使得模型能够在准确性和稳定性上获得最大化的提升,最终在各项任务中表现出色。
结论:震撼与务实,开启本地AI视觉新纪元
在深度体验和剖析了GLM-4.1V-Thinking之后,我们最大的感受是 震撼与务实。
- 震撼 在于,它以区区9B的参数量,实现了超乎想象的视觉理解和Agent能力,这背后是更“聪明”的算法和架构设计,是对算力与智能效率平衡的极致追求。
- 务实 在于,它所强化的视频理解、GUI Agent、精准图文识别等能力,无一不是指向真实世界中的复杂应用场景。这让大模型不再仅仅是云端的“聊天玩具”,而是有望成为深入各行各业、解决具体问题的强大生产力工具。
更重要的是,智谱AI再次选择了 全面开源。这意味着,从现在起,任何开发者、中小型企业或AI爱好者,都能够以较低的算力成本,在本地部署这个强大的多模态模型。他们可以在此基础上进行二次开发和微调,打造出属于自己的、适配特定业务场景的垂类应用。