
在AI技术飞速发展的今天,内容创作领域正经历一场前所未有的变革。大型AI模型如雨后春笋般涌现,它们依赖海量数据进行训练,而这些数据的来源,正是互联网上浩如烟海的内容。然而,长期以来,AI公司以“免费午餐”的方式,肆意抓取网络内容,却鲜少向内容创作者支付报酬,这种不公平的现象正逐渐引发行业内的反思与抵制。
内容创作的困境:AI时代的“失血”
过去,网站通过搜索引擎获取流量,再通过广告或订阅等方式实现变现,这是一种长期存在的隐形契约。然而,随着AI搜索和ChatGPT等应用的普及,用户可以直接从AI聊天机器人获取答案,无需点击链接访问网站,这导致网站流量大幅下降,内容创作者的收入也随之锐减。
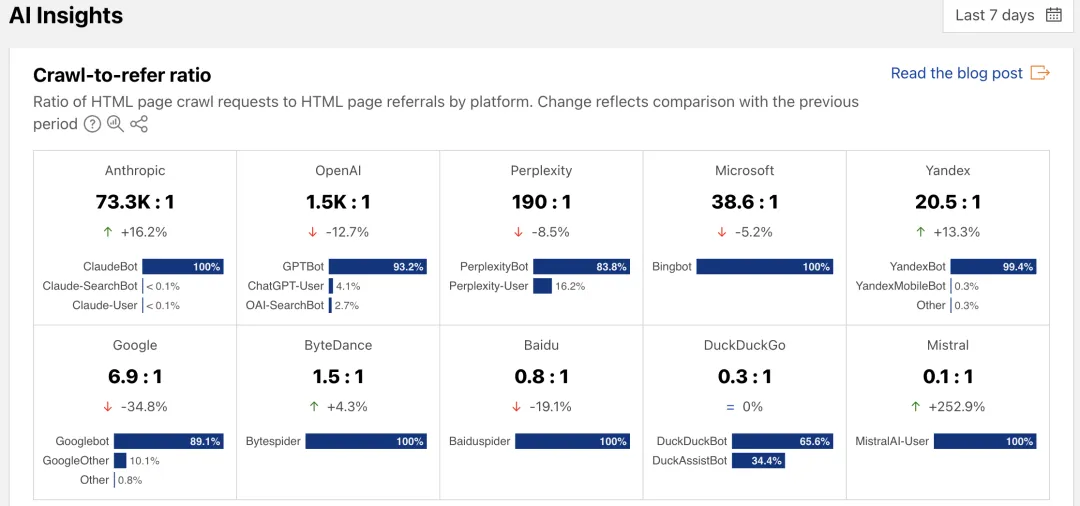
更令人担忧的是,AI巨头们的“AI爬虫”行为。这些爬虫不顾网站的爬虫协议,以高频率抓取网站数据,进一步加剧了内容创作者的“失血”状况。Cloudflare公司的数据显示,OpenAI的爬虫平均1500次抓取才能为网站带来一次点击,Anthropic的比例更是高达73300次换1次,与传统搜索引擎相比,AI爬虫的导流效果微乎其微。
Cloudflare的“赛博菩萨”行动:内容付费时代的曙光
面对AI巨头们的“掠夺”行为,互联网基础设施巨头Cloudflare站了出来,推出了名为“Pay Per Crawl”的实验性产品和交易市场,旨在为内容创作者争取应有的权益。该功能的核心在于,允许网站内容创作者自主选择是否允许AI爬虫访问,并设定相应的费用。
简单来说,网站可以选择允许AI爬虫自由访问、按次爬取收费或直接封锁访问。Cloudflare创始人表示,内容是驱动AI引擎的燃料,内容创作者理应获得报酬。这一举措无疑给内容创作者带来了新的希望,让他们在与AI巨头的博弈中拥有了更多的话语权。
对AI公司而言,“Pay Per Crawl”的实施意味着“免费午餐”时代的终结。它们需要为获取网络内容支付费用,但这并非完全是坏事。通过明码标价付费,AI公司可以避免潜在的版权纠纷,从而更加安心地进行模型训练。
“Pay Per Crawl”的技术实现:构建AI时代的“收费站”
Cloudflare之所以能够推出“Pay Per Crawl”,得益于其在全球互联网基础设施领域的领先地位。该公司在全球300多个城市部署了节点,承载了约20%的网络流量,这使其能够在访问请求到达源站之前识别和处理AI爬虫。
“Pay Per Crawl”建立在Cloudflare的全球CDN网络中间层。站长可以在Cloudflare后台设定三种模式:允许、收费、封锁。所有新加入Cloudflare的网站默认封锁AI爬虫,除非站长主动允许。只有与Cloudflare建立合作关系的AI公司才能参与支付机制,否则将被封锁。
如果AI爬虫向付费URL发起请求,尚未付费,Cloudflare就会返回HTTP 402 Payment Required状态码,这是一个专门为“网络支付”预留的状态码。AI爬虫可以在请求里带上支付信息,以表示同意支付配置的价格,一旦匹配价格就放行返回 200 OK,并自动结算。Cloudflare本身则是这个交易的“收银台”,负责聚合账单和分发收益。
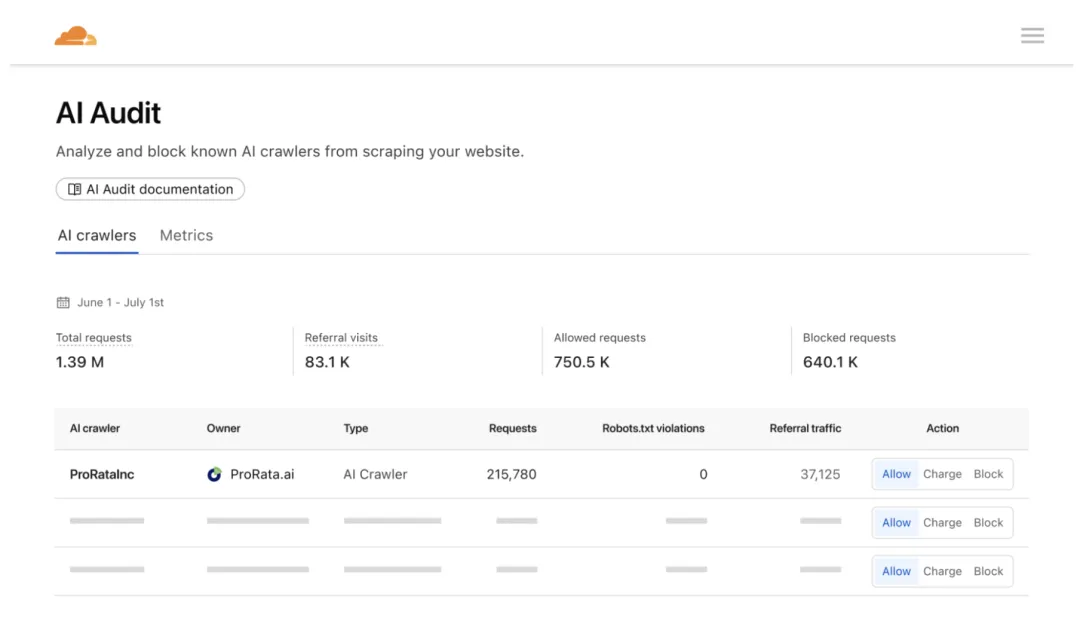
为了防止“山寨爬虫”冒充合规者逃避支付,Cloudflare要求AI公司注册密钥,用数字签名保证身份。这种方式改变了过去robots.txt的“软约束”,将其变成了“硬闸门”。
“Pay Per Crawl”的意义与挑战:重塑AI时代的内容生态
“Pay Per Crawl”的推出,无疑是AI和广大内容创作者“重新谈判分账”的开端。它将议价能力普及到更广泛的网站,让无论是大媒体还是冷门小博客,都能在AI时代拥有议价权,被AI付费使用。
Cloudflare CEO Matthew Prince将“Pay Per Crawl”推出的这一天称为“内容的独立日”,可见其对这一举措的重视。他认为,流量一直以来都无法准确衡量内容的价值,如果能够开始对内容进行评分和评估,不是根据它产生了多少流量,而是根据它对知识的促进程度,那么就有可能促进高价值内容创作的新黄金时代。
然而,“Pay Per Crawl”也面临着一些挑战。数字权利倡导者可能会担心,小型AI创业团队、研究者、开源社区能否承担这样的数据成本?学术研究、公益存档这些“良性爬虫”会不会寸步难行,只能访问有限、低价值的数据源?
在一个广告收益下滑、流量成本高涨的现实里,会有多少网站愿意无偿开放给AI爬虫吸血?这会不会成为“封闭化”的开始,让互联网失去它的自由与共享精神?如果全网都默认封锁收费,这会不会无意中加剧“大厂垄断”?
“Pay Per Crawl”的未来:Agent智能代理的新机遇
尽管面临诸多挑战,Cloudflare对“Pay Per Crawl”的未来充满信心。他们认为,按次付费爬虫的真正潜力或许会在Agent智能代理的世界中显现。
Cloudflare设想,如果智能代理付费墙能够完全以程序化的方式运作,用户就可以请深度研究助手整理最新的癌症研究、法律简报,或者找最好的餐厅,然后给这位智能代理一笔预算,用于获取最有用、最相关的内容。这种模式将开启一个智能代理能够以程序化方式协商访问数字资源的未来。
结语:互联网发展的新分岔口
Cloudflare的“Pay Per Crawl”不仅仅是一个CDN产品的新功能,更像是一个互联网发展新分岔口的信号。它标志着内容价值衡量方式的转变,以及内容创作者与AI公司之间关系的新定位。

在AI时代,用户可能不再点击网站,所有答案都在聊天机器人里总结生成。那么,是继续让AI大模型免费挖掘网络内容,还是在数据获取上回归“互惠”原则,让创作者获得应有的补偿?补偿又能有多少?
Cloudflare的早期实验可能在为一个新的AI时代数据经济形态铺路。无论成败如何,它的立场很明显:AI不能无限透支创作者的耐心,并在“开放”的名义下把人的劳动变成免费的燃料。
正如Cloudflare CEO所说,“网络正在发生变革,它的商业模式也将随之改变。在这个过程中,我们有机会从过去的30年里学到好的地方,让它在未来变得更好。”
至于事情是不是能真的变好,正如Cloudflare自己承认的那样:“这仅仅是个开始。”










