
AI音频概述:搜索结果的新形态
在人工智能技术日新月异的今天,Google再次走在了创新的前沿,推出了一个名为“音频概述”(Audio Overviews)的全新功能。这项功能利用AI技术,将搜索结果转化为类似于播客的音频形式,让用户在不方便阅读文字的情况下,也能轻松获取信息。这是否意味着我们正在迎来一个“听”的时代?
音频概述的功能与特点
音频概述并非简单的语音朗读,而是由AI对搜索结果进行总结和提炼,再由两个虚拟的声音以对话的形式呈现出来。这种形式更加生动有趣,也更接近于人们日常交流的习惯。用户可以通过调整播放速度来适应自己的节奏,同时还可以查看音频内容的来源,确保信息的准确性。
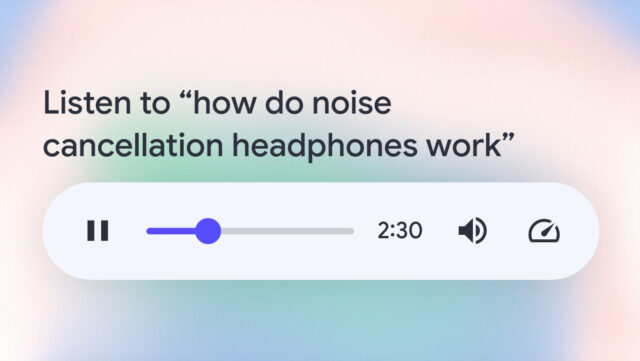
目前,这项功能还处于测试阶段,用户需要手动开启“搜索实验室”才能体验。开启后,在搜索结果中,用户可以在前几个搜索结果下方,“大家也在问”知识图谱部分找到嵌入式播放器。但与AI生成的文字概述不同,音频概述不会自动生成,用户需要点击“生成”按钮才能开始。
音频概述的应用场景
Google建议用户以“降噪耳机的工作原理”为例体验音频概述。但实际上,这项功能的应用范围非常广泛。例如,当你在开车、做饭或者进行其他不方便阅读文字的活动时,就可以通过音频概述来了解最新的资讯。此外,对于那些有阅读障碍或者视力不佳的人来说,音频概述无疑是一个福音。
音频概述的潜在问题
当然,任何新技术在发展初期都难免存在一些问题。音频概述的准确性就是一个潜在的挑战。与NotebookLM不同,音频概述的信息来源更加广泛,AI在总结和提炼的过程中,可能会出现偏差甚至错误。此前,Google的文本AI概述就曾多次被曝出错误信息。此外,音频概述的对话形式也可能会引入一些主观色彩,影响信息的客观性。
音频概述的未来发展
尽管存在一些问题,但音频概述的潜力不容忽视。随着AI技术的不断进步,我们可以期待音频概述在准确性、客观性和智能化方面得到进一步提升。未来,音频概述可能会与更多的应用场景相结合,例如智能家居、车载系统等,为用户提供更加便捷的信息服务。
此外,音频概述的商业价值也值得关注。未来,广告商可能会通过音频概述来推广产品,或者通过赞助音频概述内容来提升品牌知名度。当然,这需要在保护用户体验的前提下进行。
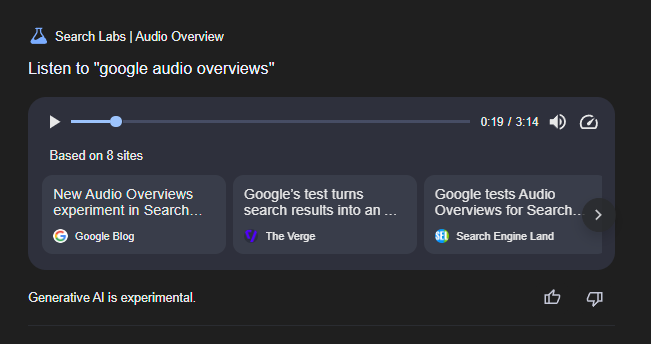
AI音频内容生成:技术原理与挑战
要理解Google的“音频概述”功能,我们首先需要了解AI音频内容生成背后的技术原理。简单来说,AI音频内容生成是指利用人工智能技术,将文本或其他形式的数据转化为自然流畅的音频。
1. 文本转语音(TTS)技术
文本转语音(Text-to-Speech,TTS)是AI音频内容生成的核心技术之一。TTS技术的目标是将书面文本转化为人类可以理解的语音。早期的TTS系统主要依赖于预先录制的声音片段,然后将这些片段拼接起来形成完整的句子。这种方法虽然简单,但生成的语音听起来非常机械,缺乏自然感。
随着深度学习技术的兴起,基于神经网络的TTS系统取得了显著进展。这些系统可以通过学习大量的语音数据,自动生成逼真自然的语音。目前,主流的TTS技术包括:
- WaveNet: 由Google DeepMind提出的WaveNet是一种深度生成模型,可以直接生成原始音频波形。WaveNet生成的语音在自然度和逼真度方面都达到了很高的水平,但计算复杂度也比较高。
- Tacotron: Tacotron是Google提出的另一种基于神经网络的TTS系统。Tacotron将文本转化为梅尔频谱图,然后再将梅尔频谱图转化为音频。Tacotron的优点是结构简单,易于训练,但生成的语音质量相对WaveNet略逊一筹。
- FastSpeech: 为了解决WaveNet和Tacotron计算复杂度高的问题,研究人员提出了FastSpeech。FastSpeech通过引入变分自编码器(VAE)来预测语音的持续时间,从而大大提高了生成速度。
2. 自然语言处理(NLP)技术
除了TTS技术,自然语言处理(Natural Language Processing,NLP)在AI音频内容生成中也扮演着重要的角色。NLP技术可以帮助AI理解文本的含义,从而生成更加准确和自然的音频。
在“音频概述”功能中,NLP技术主要用于以下几个方面:
- 文本摘要: NLP技术可以将大量的搜索结果进行摘要,提取出关键信息,为后续的音频生成提供素材。
- 情感分析: NLP技术可以分析文本的情感倾向,使生成的音频带有相应的情感色彩。
- 语义理解: NLP技术可以理解文本的语义关系,从而生成更加连贯和自然的音频。
3. AI音频内容生成的挑战
尽管AI音频内容生成技术取得了显著进展,但仍然面临着一些挑战:
- 语音质量: 虽然目前的TTS系统可以生成逼真自然的语音,但在某些情况下,仍然存在音调不自然、发音不清晰等问题。
- 情感表达: 如何让AI生成的音频带有丰富的情感,仍然是一个难题。目前,AI在情感表达方面还无法与人类相媲美。
- 多语言支持: 目前,主流的TTS系统主要支持英语和中文等少数几种语言。如何扩展到更多的语言,仍然是一个挑战。
- 个性化定制: 如何根据用户的偏好,生成个性化的音频内容,也是一个重要的研究方向。
音频信息聚合:搜索的未来趋势?
Google的“音频概述”功能并非孤例。事实上,将信息聚合为音频形式,已经成为一种趋势。随着智能音箱、无线耳机等智能设备的普及,人们越来越习惯于通过语音来获取信息。
1. 播客的兴起
播客(Podcast)是一种以音频形式传播的节目。近年来,播客在全球范围内迅速兴起。越来越多的人选择通过播客来获取新闻、学习知识、娱乐休闲。
播客的兴起,反映了人们对音频内容的需求。与文字相比,音频具有以下优势:
- 便捷性: 用户可以在任何时间、任何地点收听音频内容,无需占用视觉注意力。
- 高效性: 用户可以在碎片化时间里获取信息,提高效率。
- 个性化: 播客内容丰富多样,用户可以根据自己的兴趣选择收听。
2. 音频搜索的出现
随着语音识别技术的不断进步,音频搜索也逐渐成为可能。用户可以通过语音指令来搜索信息、控制设备。例如,用户可以通过语音助手来搜索天气预报、播放音乐、设置闹钟。
音频搜索的出现,进一步推动了音频信息聚合的发展。未来,我们可以期待更多的应用场景:
- 智能家居: 用户可以通过语音控制家里的各种设备,例如开关灯、调节温度、播放音乐。
- 车载系统: 用户可以通过语音控制导航、播放音乐、拨打电话。
- 智能客服: 用户可以通过语音与客服人员交流,解决问题。
3. 音频信息聚合的挑战
尽管音频信息聚合具有巨大的潜力,但也面临着一些挑战:
- 信息质量: 如何确保音频信息的质量,避免虚假信息、低俗内容等问题。
- 版权保护: 如何保护音频内容的版权,防止盗版行为。
- 隐私保护: 如何保护用户的语音数据,防止隐私泄露。
总的来说,Google的“音频概述”功能是AI技术在搜索领域的一次创新尝试。它能否真正改变人们获取信息的方式,还有待时间的检验。但可以肯定的是,随着AI技术的不断进步,音频将在我们的生活中扮演越来越重要的角色。










