大模型高考再战:从一本跃升985,AI智商大考炼金
人工智能(AI)技术狂飙突进,大模型的能力日新月异,但如何精准衡量AI的真实水平?或许没有比“高考”更能触动国人神经的方式了。本文复盘了极客公园最新AI高考模拟测评,通过对比国内外主流大模型在高考中的表现,揭示AI在知识掌握、逻辑推理、多模态理解等方面的最新进展与局限,并探讨AI在教育领域的潜在价值与挑战。

AI考生的高考成绩单
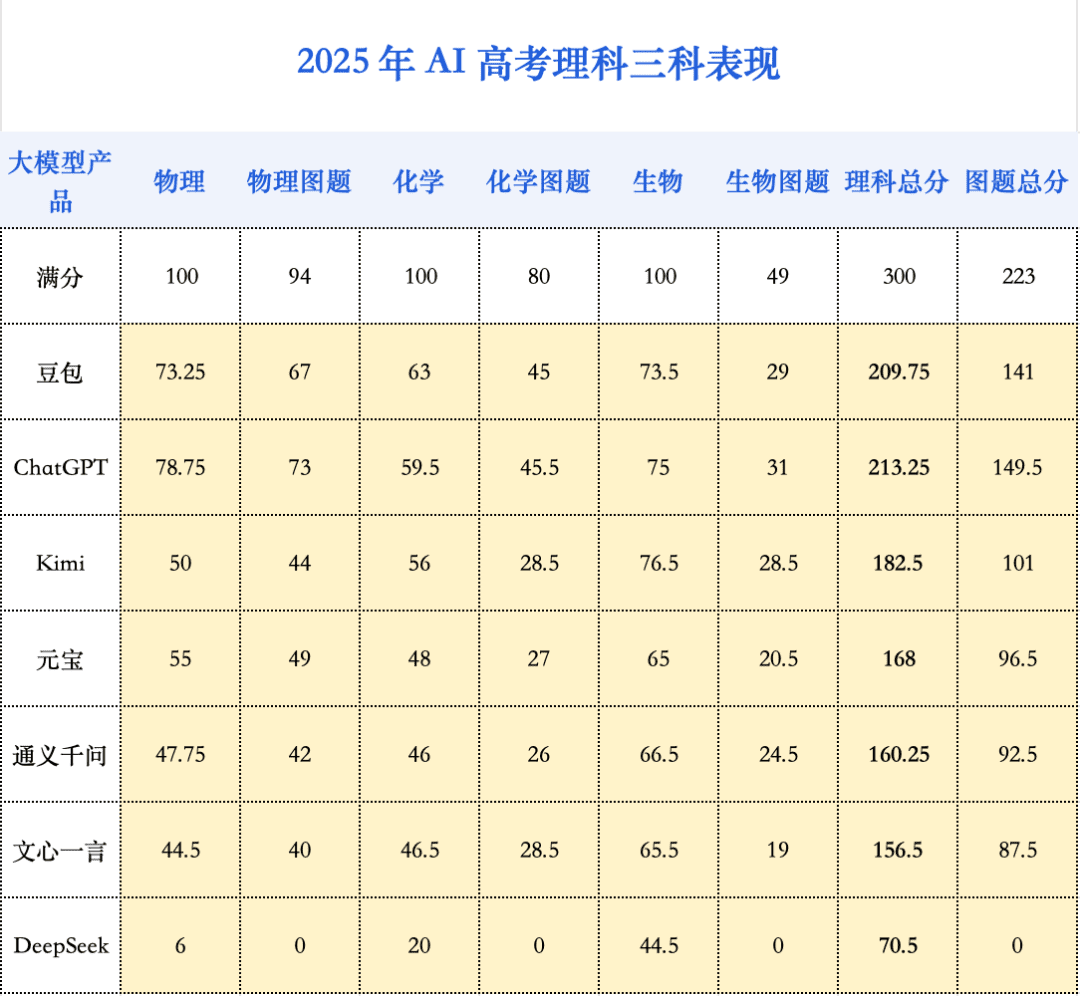
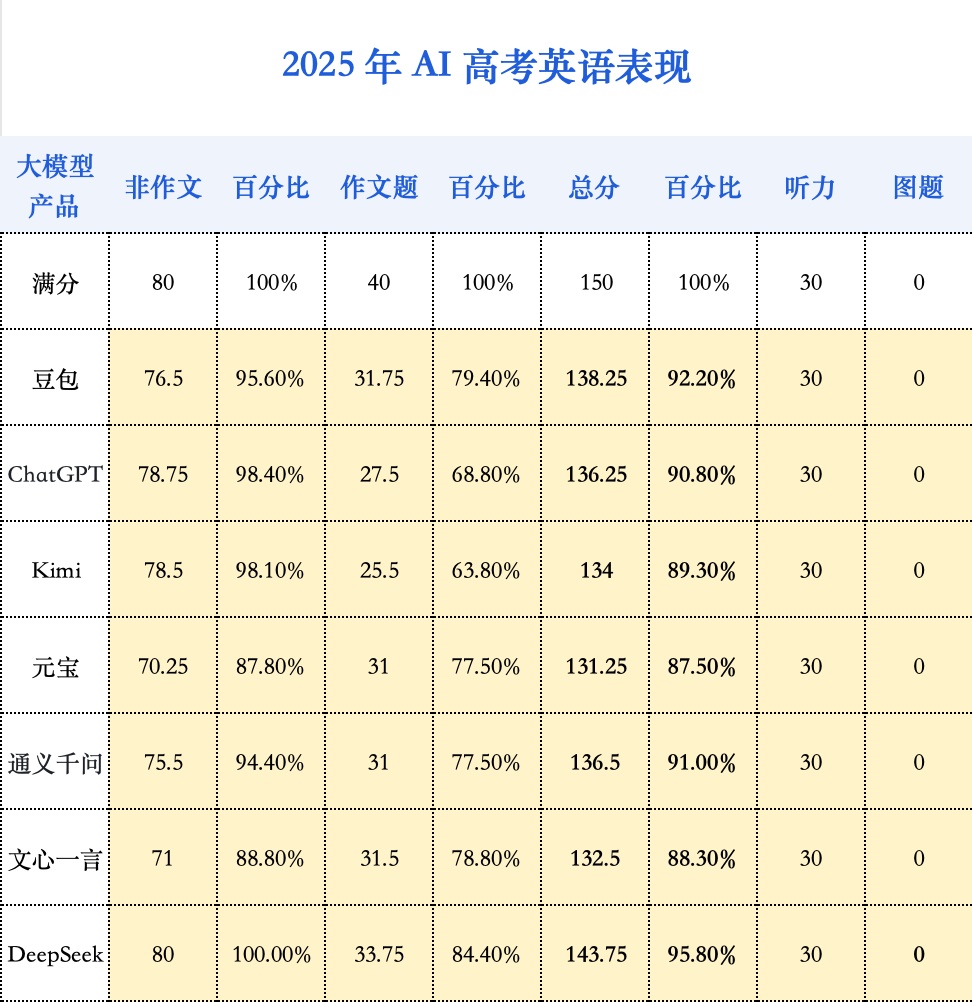
本次AI高考模拟测评,选取了2025年山东高考卷,汇集了豆包、DeepSeek、ChatGPT、元宝、Kimi、文心一言、通义千问等明星AI模型。测评直接采用图像识别作答方式,模拟真实考试场景,旨在考察AI的综合能力和应试水平。
总体成绩:
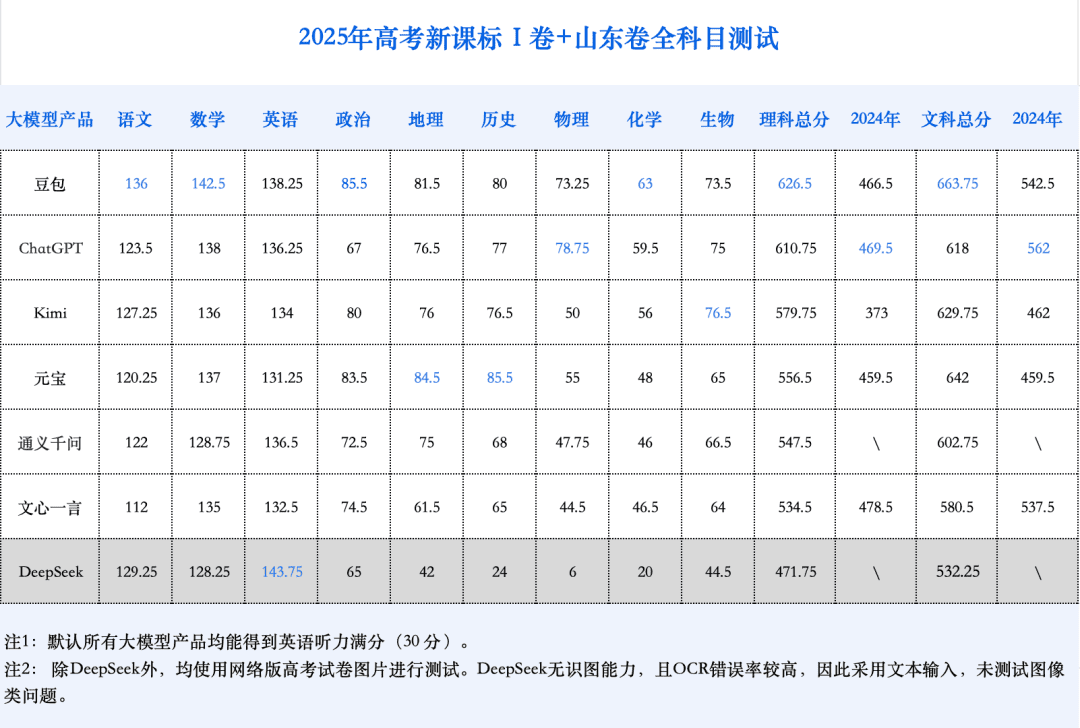
AI模型的综合能力显著提升,文理科成绩均实现飞跃。其中,表现最佳的“状元豆包”有望跻身山东省前500-900名,具备了考入人大、复旦、上海交大、浙大等顶尖学府人文社科专业的实力。
科目表现:
- 文理不再偏科: 各大模型文科总分平均增长115.6分,理科总分平均增长147.4分。尽管理科增速更快,但文科平均总分仍高于理科,AI不再严重偏科。
- 数学突飞猛进: 数学是进步最显著的科目,平均分较去年提升84.25分,甚至超越了语文和英语。这表明AI更擅长处理逻辑性强、有标准化解题路径的题目。
- 多模态能力成关键: 模型的视觉理解能力显著提升,在包含大量图像题的学科中尤为突出。物理、地理平均分提升约20分,生物提升15分,化学平均分也提高了12.6分。
从一本到顶尖大学:AI如何实现跃升?
大模型深度思考能力的提升,是AI能力进步的关键因素。模型不再直接输出答案,而是逐步分析、分解问题、检查中间结果,甚至自我修正,这使得AI在数理考试中的表现大幅提升。在总分150分的数学考试中,即便表现最差的AI模型也能拿下128.75分的高分,这在人类考生中也属于优秀水平。
多模态能力是决定AI能力表现差别的另一个关键因素。主流模型已普遍具备多模态能力,尤其是在图像问题上,豆包、ChatGPT等模型展现出明显优势。然而,即便图像问题得分最高的模型,其得分率也仅为70%,相比文本问题90%的最高得分率仍有较大差距,表明AI在多模态理解和推理上仍有很大的提升空间。
数学逼近满分的AI,为何败于基础题?
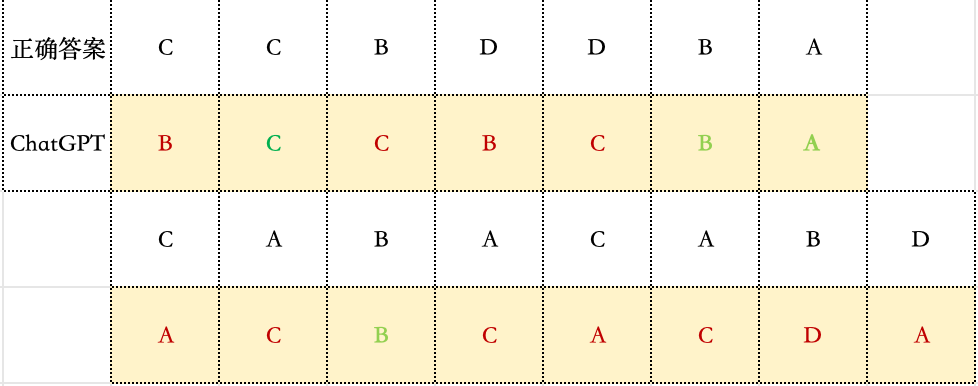
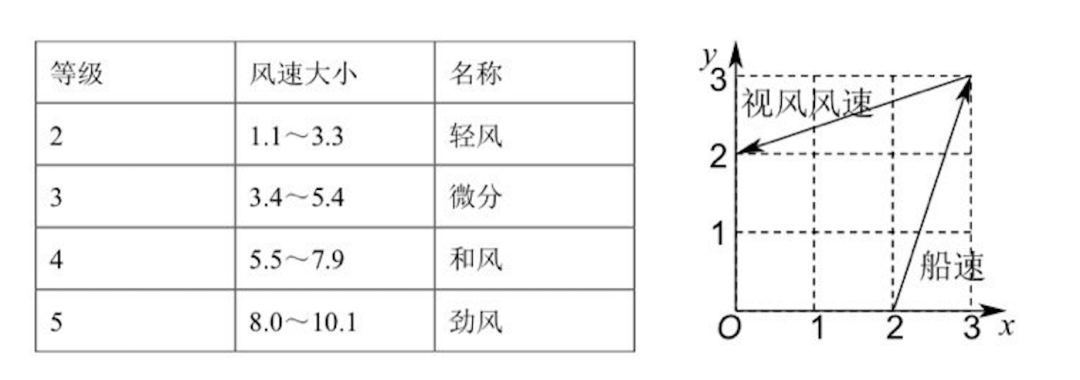
AI在数学科目上的进步令人瞩目,正确率今非昔比。然而,在本次AI高考测评中,数学尖子生们却在同一道选择题上栽了跟头。这道题的数学原理非常简单,是一道基础的向量加减法题。问题在于,这张图的视觉信息极其混乱:虚线、实线、坐标轴、数字、文字相互交织,甚至文字与关键线段存在多处重叠。这种视觉上的“脏数据”成为了AI精准识别的噩梦。

AI写作文:擅长举例,但不擅长思辨升华
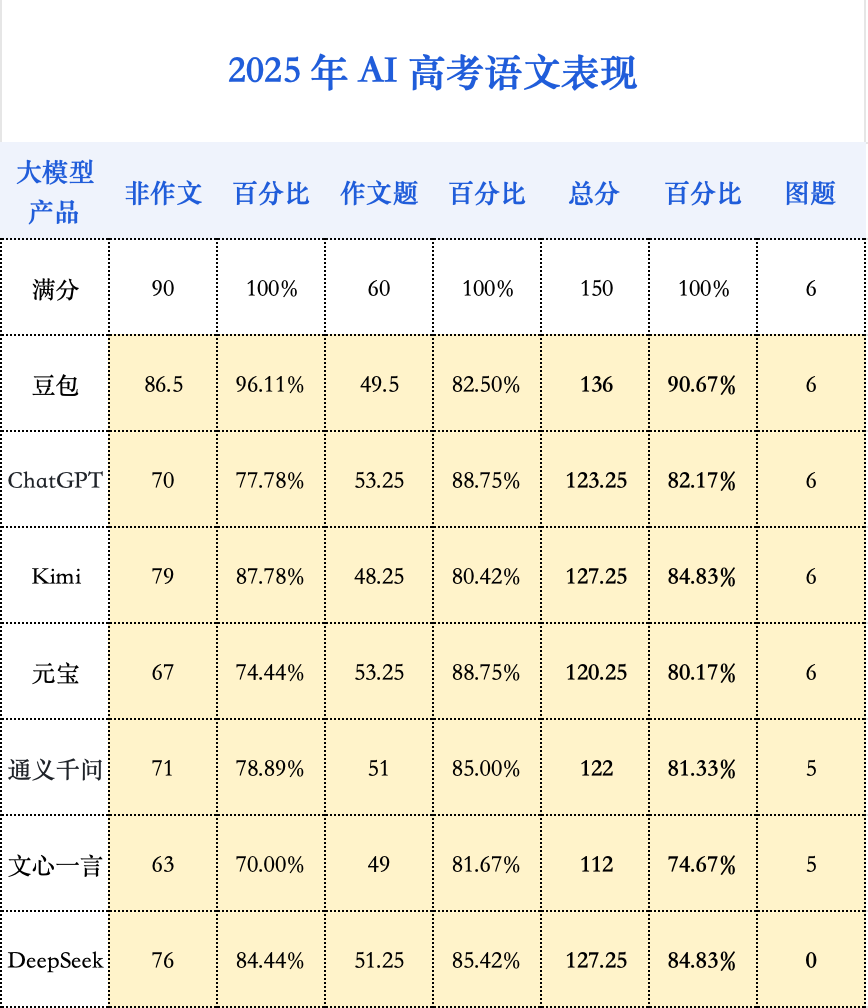
作为大语言模型,语文和英语一向是AI的传统强项。但有趣的是,在大模型的数理逻辑大幅进步后,语文和英语能力反而显得有点不够看了。AI作文平均分高于人类,但难有真正的佳作。AI作文大多属于稳妥的“二类文”,很少偏题,但因其深刻性、丰富性、创造性不足,难以产生动人心弦的“一类文”,其结尾部分的升华更是套路化明显。

以元宝生成的AI作文为例,其在人类阅卷老师处获得了53.5分的高分,是AI作品中的佼佼者。然而,细究其文,AI“模板化”的问题依旧暴露无遗。比如,中间几段先是提出观点,随即并列引用三到四位历史人物;接着,引出论点,再列举三到四位经历苦难的人物;最后,论及当代精神,再次列举三到四个当代人物。AI作文的语言华丽,引经据典丰富,但逻辑上像极了家长式的说教。
英语:主要被作文分数拖累
与语文相似,AI在传统强项——英语上的表现也进入了一个平台期。各家AI的英语成绩已然不错,今年的模型能力并未产生飞跃。事实上,所有参评模型的平均分仅比去年提高了3.2分,进步幅度远小于数学。
作文题可能是一大拖累。这背后有两个可能的原因:一是苛刻的字数限制。二是缺乏应试智慧。在有限的篇幅内,人类考生会有意识地使用更高级句式、时态来“炫技”以博取高分。而AI的目标通常是清晰、完整地传达信息,它不会刻意为了得分而优化句式复杂度,因此在评分细则上可能吃了暗亏。
理综三科:有进步,但仍不算优秀
如果说AI在数学上的进步是“一飞冲天”,那么在理综三科上的表现,则更像是一次“破冰启航”。相较于去年,理综三科有一定进步,所有模型都提分10-20分,但整体成绩依旧挣扎在及格线附近,清晰地标示出AI与顶尖人类考生之间的能力鸿沟。
相比于数学,理综三科既考验逻辑能力,又考验多模态能力。而今年,读图能力的解锁,加上模型推理能力的增强,共同带动了理综能力的进步。不过正如绊住AI的数学题所展现的一样,能“看见”不代表AI能“看懂”。

文综是舒适区
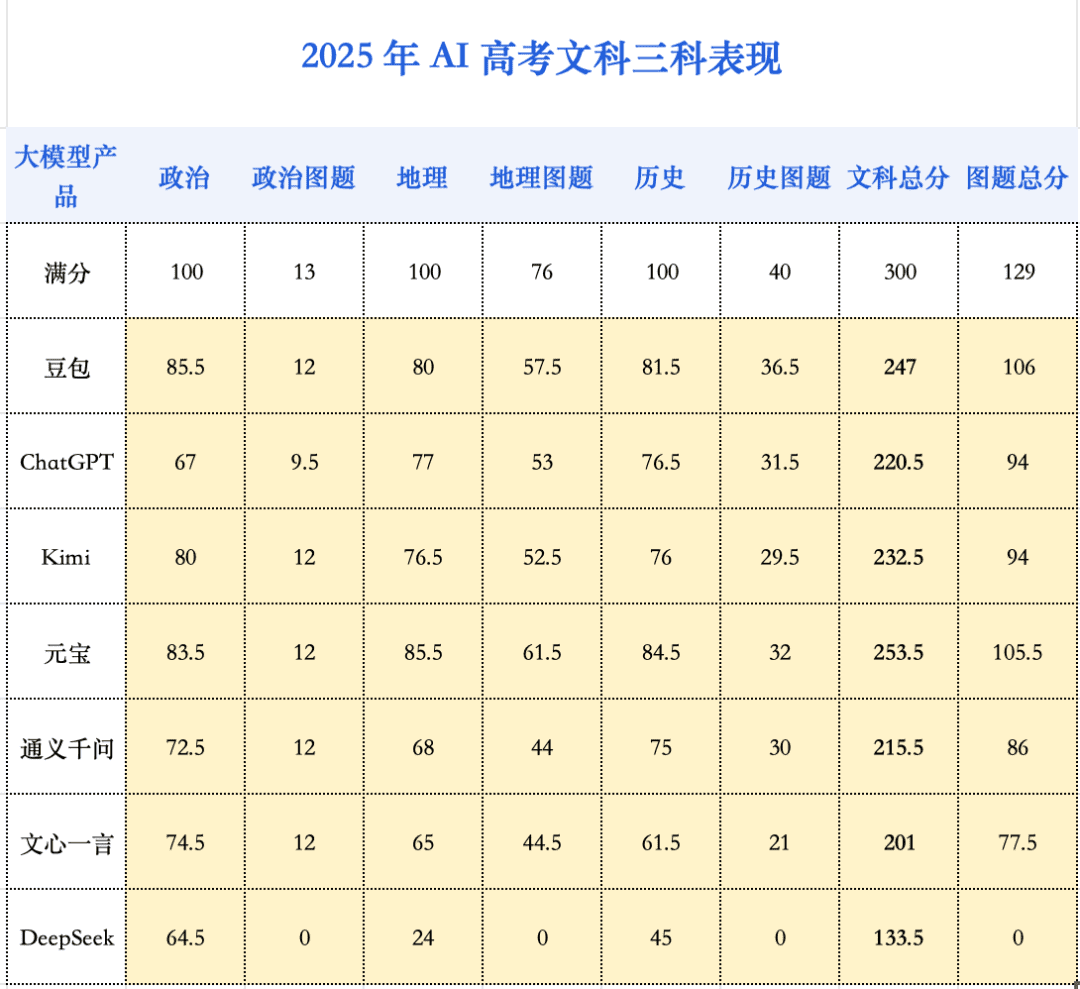
在今年的AI高考评测中,文科综合依然是AI的高分舒适区。元宝更是将文综最高分推升至253.5分,这一成绩与理科综合最高分(213.25分)形成了鲜明对比。相比去年,文强理弱的偏科问题虽有缓解,但基本格局并未改变,这与人类考生相反。在人类考生中,理综最高分往往比文综最高分高出不少。

今年的分数增长主要由地理科目贡献。得益于多模态能力的飞跃,AI在地理图题上的理解力显著增强,使得该科目平均分激增了20.3分,成为进步的火车头。与之相对,政治和历史科目的分数则基本处于高位平台期,并未呈现显著进步。
AI眼镜能用来作弊吗?
从去年到今年,AI眼镜等“视觉AI硬件”无疑是科技界最炙手可热的焦点。今年的高考也迎来了一项新变化:考场安检门全面升级,旨在精准防范智能眼镜等新型作弊工具。那么,这些新兴的、能与视频进行实时交互的多模态大模型,真的能用来在考场上“大显神通”吗?
测试结果表明,想在目前阶段,单纯依靠AI眼镜在考场作弊,还需要担负必须不断跟它说话、答案完全不准等巨大风险,基本属于科幻情节。今天的视频大模型仍处于非常早期的阶段。
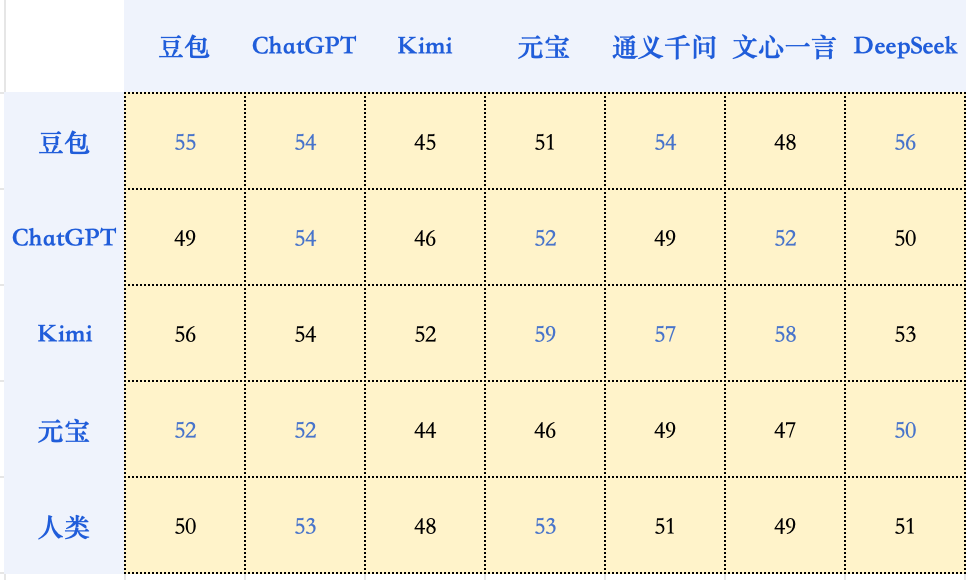
仿生人会爱上自己生成的电子羊吗?
在AI的世界里,大模型是否也存在审美偏好呢?它会因为更欣赏自己的文风,从而在给其他模型打分时产生偏见吗?测试结果表明,模型并没有表现出对自家作品的特殊偏爱,AI与人类判分员的审美大方向仍然是一致的。可能真的只是和我们普通人类一样吧:我知道什么是好的,就是写不出来。
AI高考:一次AI能力进化的快照
今年,或许是高考测试对大模型仍具挑战意义的最后一年。当AI已经能展现出冲击顶尖学府的实力时,这个人类社会的智能筛选器,可能未来不再能成为对AI有区分度的测试了。
高考测试,不仅仅是一场对人类智慧与AI智慧的对比,也是我们观察AI智能发展的一个刻度表。过去一年,我们对AI能力的直观感受和多次验证,正在不断地提醒我们:AI正加速逼近甚至超越普通人的能力边界。
但它的发展并非线性——它能攻克人类眼中的难题,却也会在看似简单的题目上意外失足。正因如此,高考让AI展现出了它最迷人而矛盾的一面:它时而展现出顶尖人类的才华,轻而易举地攻克难题;时而又暴露出孩童般的认知盲区,在基础问题上犯下令人啼笑皆非的错误。
感谢高考。它用一种我们最熟悉的方式,为AI的通用智能水平提供了一张刻度清晰、极具参考价值的“快照”,而这,很可能是最后一张了。
AI的下一站,终将是更复杂、更广阔的现实世界。考试,只是它漫长征途的起点,而非能力边界的终点。