
大模型高考再「战」:从一本到985的跃升
人工智能(AI)技术在过去一年里取得了显著的进展,特别是在大型语言模型(LLM)方面。这些模型的能力已经从简单的文本生成扩展到复杂的视频创作和科学发现。为了更精确地评估AI的能力,极客公园再次组织了一场“AI高考”,让国内外的主流大模型参与测试,以此来衡量它们在模拟高考环境下的表现。

今年的测试结果显示,AI在多个方面都取得了显著的进步。最引人注目的是,AI的综合能力首次达到了可以考入顶尖学府的水平。与2024年的测试相比,所有参与测试的大模型在文科和理科的成绩都有了显著的提高。根据估算,本次高考的状元“豆包”模型,如果放在实际的高考环境中,有望进入全省前500-900名,这意味着它可以考入如中国人民大学、复旦大学、上海交通大学和浙江大学等名校的人文社科类专业。
AI表现的关键发现
不再严重偏科:各大模型的文科总分平均增长了115.6分,理科总分平均增长了147.4分。虽然理科的增速更快,但文科的平均总分仍然高于理科。这意味着AI在不同学科之间的均衡性得到了显著提升。
数学能力大幅增强:数学是今年进步最显著的科目,平均分较去年提升了84.25分。AI在数学上的表现甚至超过了语文和英语,预示着未来AI可能更擅长处理逻辑性强和有标准化解题路径的题目。
多模态能力的重要性:从去年到今年,模型在视觉理解能力方面有了显著提升,这在包含大量图像题的学科中尤为突出。物理和地理的平均分提升了约20分,生物提升了15分。化学科目的整体表现稍弱,但平均分也比去年提高了12.6分。
视频流中答题:今年的测试还包括让AI在视频流中答题的尝试,这是一个新的探索方向。
从一本到顶尖大学的飞跃
如果说去年的AI还只是一个刚达到一本线的学生,那么今年它们已经成长为有潜力进入中国顶尖学府的学霸。为了更深入地了解这些变化,本次参与考试的模型包括豆包、DeepSeek(R1-0528版)、ChatGPT(o3)、元宝(Hunyuan t1)、Kimi(k1.5)、文心一言和通义千问。
本次评测在各模型的公开PC端进行,采取采样两次取平均分的形式,旨在考察模型的综合能力。为了评估模型处理图像的能力,测试直接让模型识别图像作答。DeepSeek-R1由于不支持图片识别作答,因此只测试了纯文字题目。
测试细节:
- 试卷选择:选用2025年新高考山东卷作为测试卷,因为它既能保证评测的时效性,又具有较高的难度,更能探知当前大模型能力的上限。
- 联网限制:为了保证公平,关闭了可以关闭联网能力的模型的联网功能,以避免“搜题”行为。对于无法关闭联网的模型,如o3和文心一言,虽然o3有少量搜题行为,但没有明显收益。
- 评分标准:非选择题由两位专业人士打分,如存在较大差异,则引入第三人讨论定分,并邀请高中老师抽检,以统一标准。作文由资深教师进行匿名评审,英语听力部分则设定所有模型均为满分。
过去一年,大模型的深度思考能力带来了显著的进步。模型不再是直接给出答案,而是逐步分析、分解问题、检查中间结果,甚至进行自我修正,这使得模型在数理考试中的表现大幅提升。在总分为150分的数学考试中,即使是表现最差的AI模型也拿下了128.75分的高分,这在人类考生中也属于优秀水平。相比之下,去年表现最好的模型也只达到了70分,连及格线都未达到。
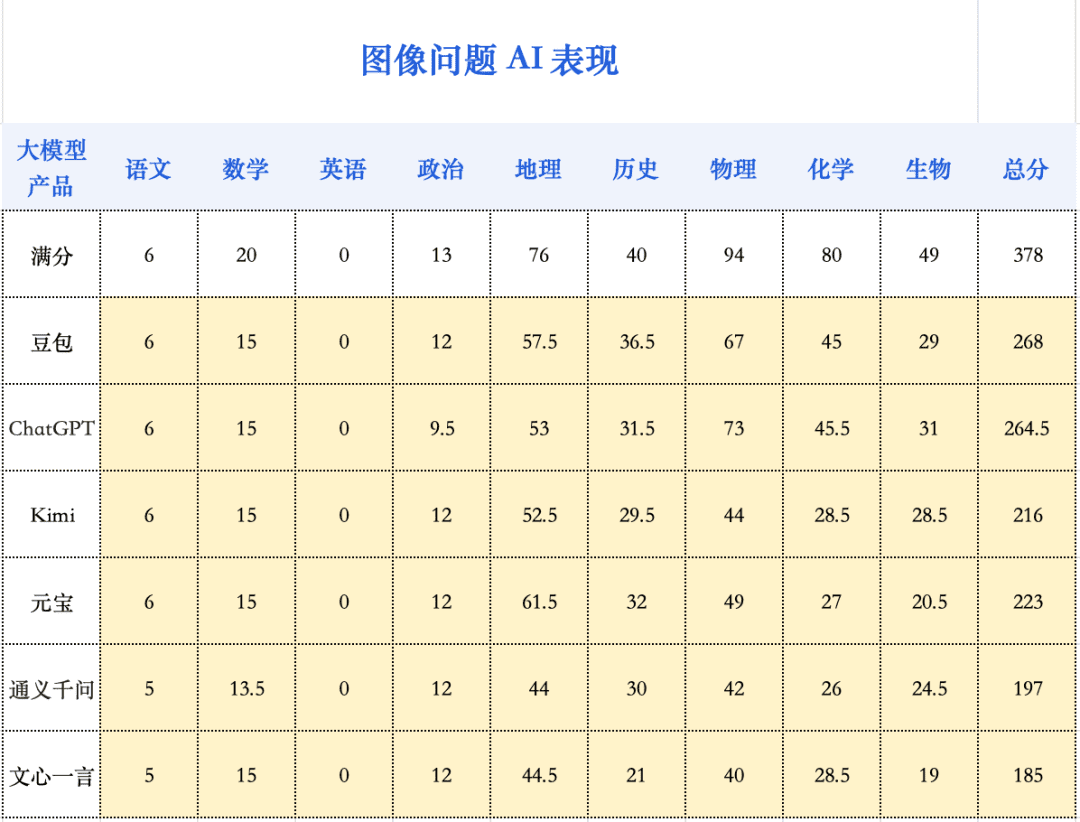
数学能力的进步直接带动了今年大模型整体高考成绩的提升。多模态能力也成为决定大模型能力表现差别的另一个关键因素。在去年的高考测试中,不少模型还不具备成熟的图片识别能力。今年,多模态能力已成为主流模型的标配功能,因此,本次测试首次采用纯图片题目测试(DeepSeek除外)。
在多个模型中,豆包和ChatGPT等最先进的模型都是多模态版本,在图像问题上体现出明显优势。Qwen3和文心X1等语言模型在处理图像问题时,可能是通过OCR识别文字后回答,或调用视觉模型,因此在图像类问题上表现较弱。
尽管如此,即使是图像问题得分最高的豆包和ChatGPT,其图像问题的得分率也仅为70%,相比文本问题90%的最高得分率有较大差距,这表明大模型在多模态理解和推理上仍有很大的提升空间。
数学逼近满分的AI天才们,败在一道基础题上
在整场AI高考的测评中,“AI考生”复读一年后,在数学科目上的进步尤为显著。在2024年的测评中,当时的AI考生们在填空题和解答题上表现惨淡,得分普遍在0至2分之间徘徊,最终9款参评模型的数学成绩平均分仅为47分。而今年则完全不同。
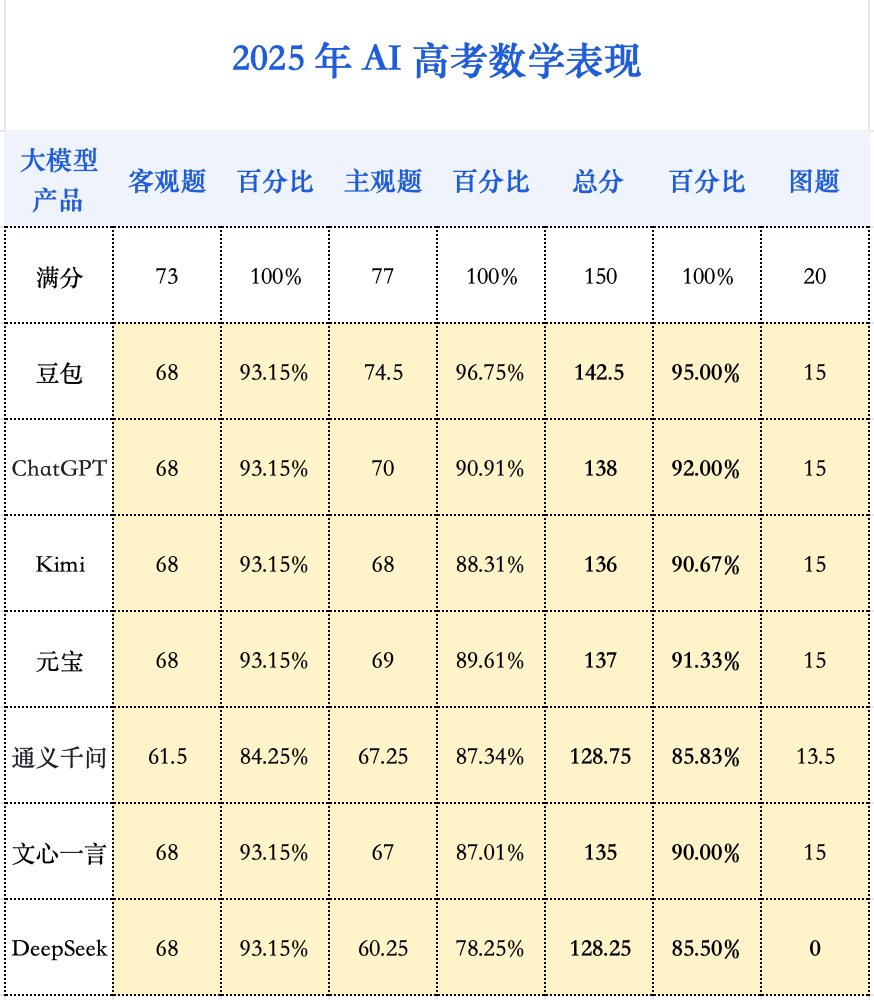
可以看出,无论是客观选择题,还是复杂的主观解答题,新一代大模型的正确率都显著提高。这清晰地表明,大模型自身的能力,尤其是核心的推理能力,已经取得了根本性的突破。如果说去年的模型还只是一个能勉强套用求导、三角函数等基础公式的“初学者”,那么今年的模型则已经进化成一个能够从容应对复杂推导和证明的“解题高手”。
自从AI进入推理模型时代,数理能力的大幅提升就是一个标志性进展。当模型拥有了自我思考与自我纠错的能力,它就像一个从前张口就回答问题的孩子,成长为一个会先深度思考再给出答案的大人,逻辑能力实现了质的飞跃。
然而,面对这样一份高难度试卷,顶尖的大模型们依旧表现得游刃有余。这些整体都考了130分以上的大模型,在同一道选择题上出现了错误。难住它们的是一道基础的向量加减法题。
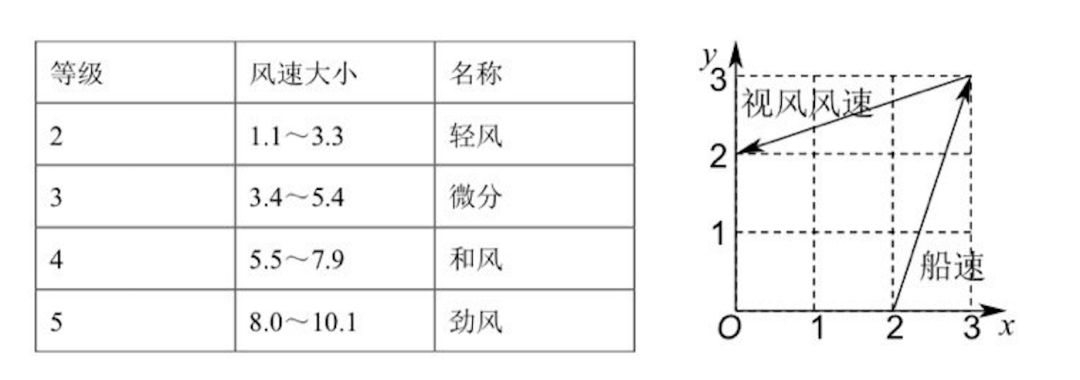
这道题的数学原理非常简单,只需在图上连接(0,2)与(2,0)两点,即可得到目标向量,模长2倍根号2。然而,就是这样一道题,难住了所有数学学霸AI。核心矛盾在于题目不难,但图难。对于大模型而言,这张图的视觉信息极其混乱:虚线、实线、坐标轴、数字、文字相互交织,甚至文字与关键线段存在多处重叠。这种视觉上的“脏数据”成为了AI精准识别的噩梦。
以本次数学表现最佳的豆包为例,它的解题过程暴露了问题的根源:它从最开始读取题目信息时,就已经出错了。

AI写作文:擅长举例子,但不擅长思辨性地升华
作为所谓的大语言模型,语文和英语一向是AI的传统强项。不过有趣的是,在大模型的数理逻辑大幅进步后,大模型的语文和英语能力反而显得有点不够看了。这与现实世界也是一致的:一名顶尖考生或许能在数学上拿到满分,却极难在语文科目上获得同等分数。AI似乎也触碰到了同样的瓶颈。

仔细研究语文卷面可以发现,AI的失分点颇为有趣。在选择题部分,除豆包和DeepSeek-R1以外,其余模型的错误率均在20%以上。对于人类考生,组织语言、阐述观点时,可能更容易因疏漏而失分;但对于AI,要读一段长材料,在一组高度迷惑性的选项中,精准辨析每一个细微的语义差别和逻辑陷阱,难度可能反而更高。
在备受瞩目的作文题上,AI的表现则延续了去年的趋势:平均分高于人类,但难有真正的佳作。AI作文大多属于稳妥的“二类文”,很少偏题,但因其深刻性、丰富性、创造性不足,难以产生动人心弦的“一类文”,其结尾部分的升华更是套路化明显。
今年的新课标卷的语文作文考题为:全国一卷作文「民族魂」。
这是在一次采样中,元宝生成的AI作文。它在人类阅卷老师处获得了53.5分的高分,是AI作品中的佼佼者。
然而,细究其文,AI“模板化”的问题依旧暴露无遗。AI作文的语言不可谓不华丽,引经据典也自然十分丰富充满细节,但逻辑上像不像你的家长对你说,你看看谁谁谁都怎么样了,你是不是也该怎么样?
英语:主要被作文分数拖累
与语文相似,AI在传统强项——英语上的表现也进入了一个平台期。事实上,所有参评模型的平均分仅比去年提高了3.2分,进步幅度远小于数学。而模型的整体分数,也落在了130-140分的区间,并未到达人类学霸的水平。

AI的英文水平是有目共睹的,或许比不少英文专业的学生讲出的英语更正宗。而高考英语这张试卷,本身远未触及母语者的语言天花板,且相较于包含古文的语文,其客观题占比更高、作文要求更简(仅80词),也并不追求立意高远,理论上是AI更容易获得绝对优势的战场。然而,AI考生并未在此表现出更强的统治力。
那么,瓶颈究竟出在哪里?作文题可能是一大拖累。这背后有两个可能的原因:苛刻的字数限制和缺乏应试智慧。本次评测最有趣的一点,莫过于中外模型在作文上呈现的“主客场反转”现象。在中文作文这一“客场”,以ChatGPT为代表的“洋考生”拔得头筹;然而在本应是其“主场”的英文科目上,它却不敌“中国考生”——DeepSeek在选择题上甚至拿了满分,而最终总成绩上,DeepSeek也与豆包一同超越了ChatGPT。
理综三科:有进步,但仍然不算十分优秀
如果说AI在数学上的进步是“一飞冲天”,那么在理综三科上的表现,则更像是一次“破冰启航”。相较于去年,理综三科有一定进步——所有模型都提分10-20分,但整体成绩依旧挣扎在及格线附近,清晰地标示出AI与顶尖人类考生之间的能力鸿沟。
相比于数学,理综三科既考验逻辑能力,又考验多模态能力——物理化学两科的图题占80%以上,生物的图题也占全部题目的一半左右。而今年,读图能力的解锁,加上模型推理能力的增强,共同带动了理综能力的进步。不过正如绊住AI的数学题所展现的一样,能“看见”,不代表AI能“看懂”。这在大模型在化学上的表现不佳上,能清楚地展现出来。化学题目对图片的依赖性强,且化学题目图片的复杂程度更高,此时AI的短板便暴露无遗。
目前,顶尖AI的理综成绩大致相当于中上游的人类考生水平,但远未达到“学霸”级别。正所谓“卷子越难,差距越显”,在综合性与深度并存的理综试卷上,AI尚未具备稳定碾压人类考生的实力。

分科来看这次AI的成绩:
- 物理:此次理综三科中进步最快的“排头兵”,平均分提升了20.25分。
- 化学:成为了拉低理综总分的“重灾区”,整体得分偏低,仅有豆包勉强及格,选择题和填空题的平均得分率均低于60%。
- 生物:短板则精准地暴露在需要严密逻辑推理的遗传题上。
AI仍然偏科,文综是舒适区
在今年的AI高考评测中,一个清晰的趋势得以延续:文科综合依然是AI的高分舒适区。相比去年,文强理弱的偏科问题虽有缓解,但基本格局并未改变,这与人类考生相反。在人类考生中,理综最高分往往比文综最高分高出不少。
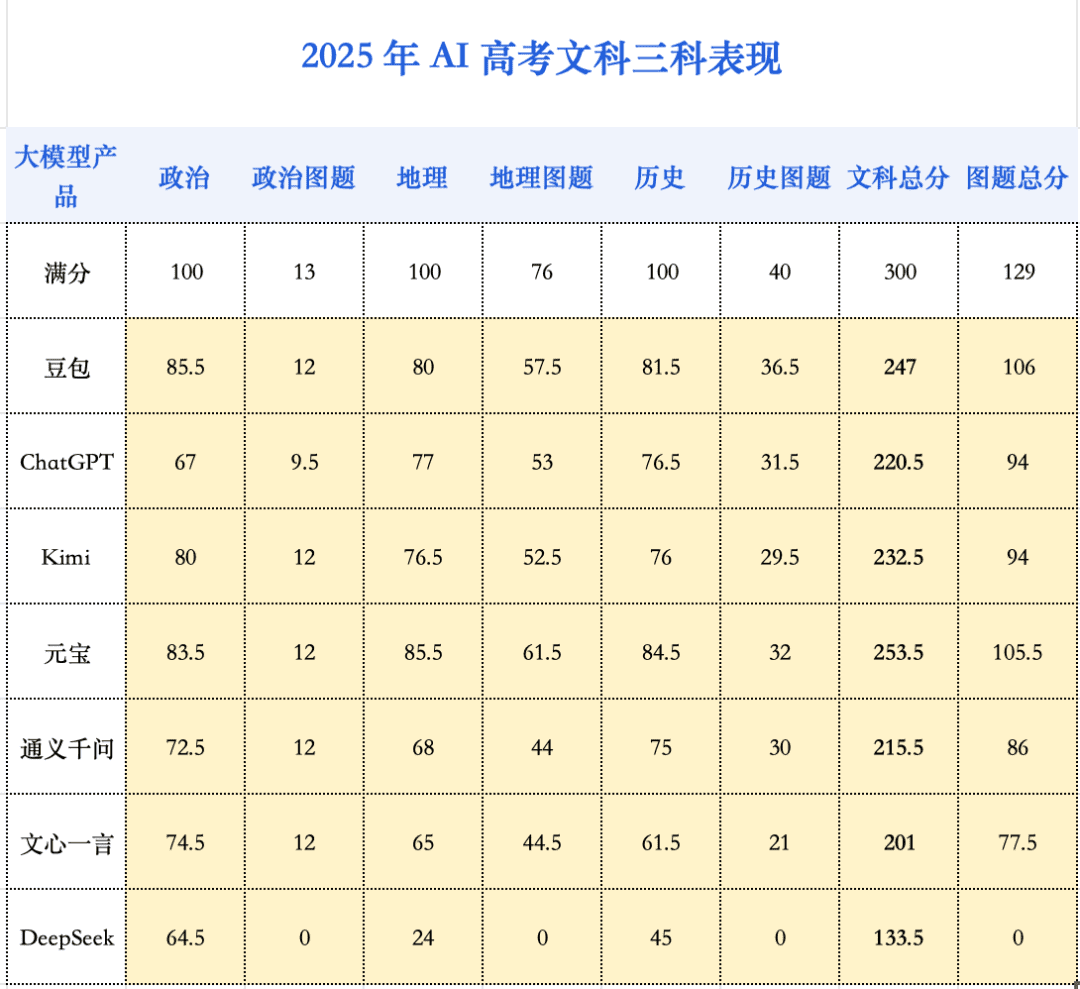
今年的分数增长,主要由地理科目贡献。得益于多模态能力的飞跃,AI在地理图题上的理解力显著增强,使得该科目平均分激增了20.3分,成为进步的火车头。地理题上想更进一步,面对的挑战与理科中的化学如出一辙——对高度专业的复杂图形,AI理解依然吃力。与之相对,政治和历史科目的分数则基本处于高位平台期,并未呈现显著进步。
AI 眼镜能用来作弊吗?
今年的高考也迎来了一项新变化:考场安检门全面升级,旨在精准防范智能眼镜等新型作弊工具。我们选择国外的ChatGPT与国内的元宝,进行了一次非常规的测试。结果表明,视频大模型仍处于非常早期的阶段,想在目前阶段,单纯依靠它在考场作弊,还需要担负必须不断跟它说话、答案完全不准等巨大风险,基本属于科幻情节。

仿生人会爱上自己生成的电子羊吗?
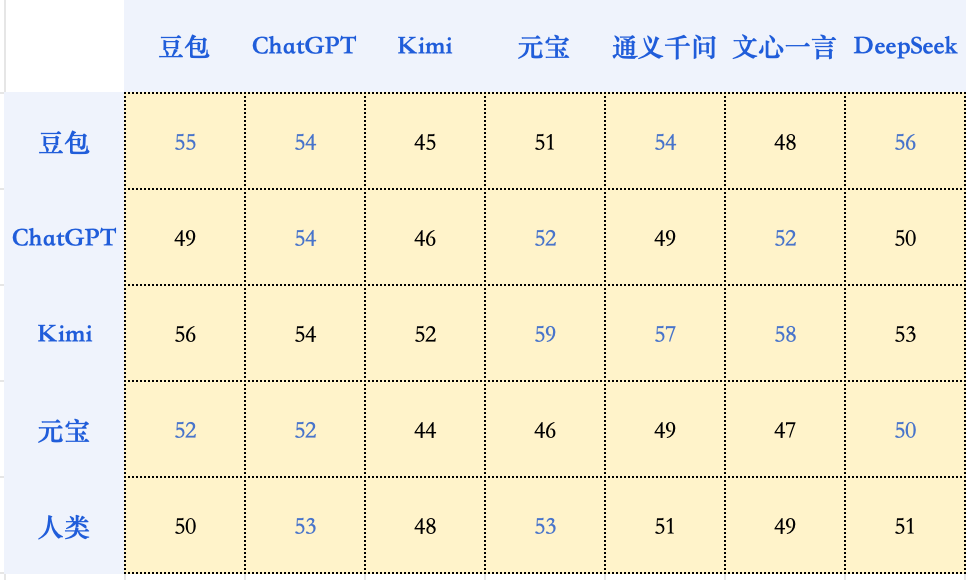
我们让参与本次评测的大模型们,对彼此生成的作文进行交叉打分和排序。结果表明,模型并没有表现出对自家作品的特殊偏爱,有时候反而可能给自己打低分。AI与人类判分员的审美,大方向仍然是一致的。可能真的只是和我们普通人类一样吧:我知道什么是好的,就是写不出来。
总结
当AI已经能展现出冲击顶尖学府的实力时,高考可能未来不再能成为对AI有区分度的测试了。高考测试,不仅仅是一场对人类智慧与AI智慧的对比,也是我们观察AI智能发展的一个刻度表。AI正加速逼近甚至超越普通人的能力边界。但它的发展并非线性——它能攻克人类眼中的难题,却也会在看似简单的题目上意外失足。高考,让AI展现出了它最迷人而矛盾的一面:它时而展现出顶尖人类的才华,轻而易举地攻克难题;时而又暴露出孩童般的认知盲区,在基础问题上犯下令人啼笑皆非的错误。










