
在人工智能音频生成领域,阿里语音AI团队近期开源的ThinkSound模型无疑是一项引人瞩目的创新。该模型是全球首个支持链式推理的音频生成模型,它通过引入思维链(Chain-of-Thought)技术,克服了传统视频转音频技术在捕捉画面动态方面的局限性,实现了高保真和强同步的空间音频生成,标志着AI音频技术从简单的“看图配音”向更高级的“结构化理解画面”的重大飞跃。
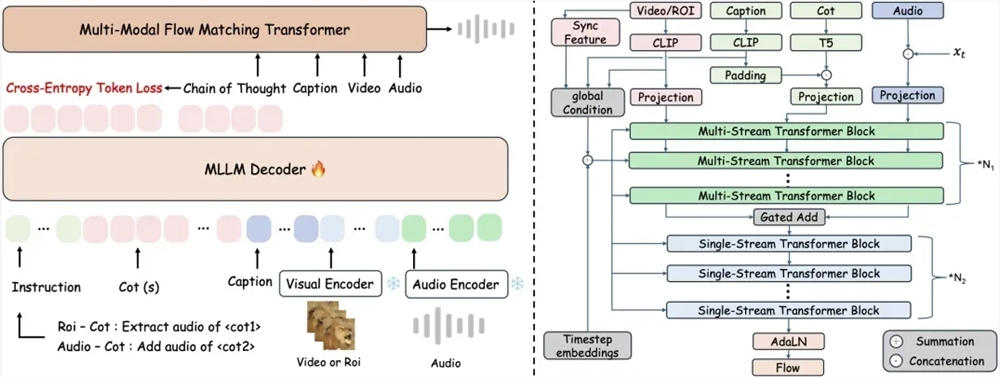
传统端到端视频转音频技术往往忽略了画面细节与声音之间存在的时空关联,导致生成的音频与视觉事件出现错位,影响了用户体验。为了解决这一问题,ThinkSound创新性地将多模态大语言模型与统一音频生成架构相结合。该模型采用三阶段推理机制,从而实现精准的音频合成。首先,系统会对画面整体运动和场景语义进行深入解析,生成结构化的推理链;然后,模型会聚焦于具体的物体声源区域,并结合语义描述来细化声音特征;最后,ThinkSound还支持用户通过自然语言指令进行实时交互编辑,例如“在鸟鸣后添加树叶沙沙声”或“移除背景噪声”等操作,为用户提供了极大的灵活性和控制力。
为了支持模型的结构化推理能力,阿里语音AI团队构建了一个包含2531.8小时高质量样本的AudioCoT多模态数据集。该数据集整合了VGGSound、AudioSet等多个来源的音频数据,涵盖了动物鸣叫、机械运转等各种真实场景的音频。为了确保数据集的质量,研究团队采用了多阶段自动化过滤和人工抽样校验相结合的方法,并特别设计了对象级和指令级样本,使模型能够处理诸如“提取猫头鹰鸣叫时避免风声干扰”等复杂的指令。
实验数据表明,ThinkSound在VGGSound测试集的核心指标上,相较于主流方法提升超过15%。同时,在MovieGen Audio Bench测试集中,ThinkSound的表现也大幅领先于Meta的同类模型。目前,ThinkSound的代码和预训练权重已在GitHub、HuggingFace以及魔搭社区开源,开发者可以免费获取并使用。
阿里语音AI团队表示,未来他们将重点提升模型对复杂声学环境的理解能力,并计划将ThinkSound拓展至游戏开发、虚拟现实等沉浸式场景。该技术不仅能够为影视音效制作、音频后期处理提供新的工具,还有可能重新定义人机交互中的声音体验边界。业内专家指出,ThinkSound的开源将加速音频生成领域的技术普及,推动创作者经济向更加智能化的方向发展。
ThinkSound的技术原理
ThinkSound模型的核心在于其创新的三阶段推理机制,这种机制使其能够更精确地理解和模拟真实世界的音频场景。以下是对这三个阶段的详细解析:
场景理解与推理链生成
- 多模态输入:ThinkSound模型并非简单地处理视频帧,而是同时接收视觉信息和文本描述。这种多模态输入为模型提供了更丰富的上下文信息。
- 场景解析:模型利用多模态大语言模型对输入视频进行深度分析,识别出场景中的主要元素、物体以及它们之间的关系。例如,模型可以识别出画面中有一只鸟停在树枝上,周围环境是森林。
- 推理链生成:基于场景解析的结果,模型生成一个结构化的推理链,该推理链描述了场景中各个元素的行为和交互。例如,推理链可能包括“鸟鸣叫”、“树叶被风吹动发出沙沙声”等事件。
声源定位与特征细化
- 声源定位:模型根据推理链中的事件,确定画面中潜在的声源区域。例如,如果推理链中包含“鸟鸣叫”事件,模型会将鸟所在的位置标记为声源区域。
- 特征细化:模型会进一步分析声源区域的视觉特征,并结合语义描述来细化声音特征。例如,模型会根据鸟的种类、大小以及周围环境,生成具有特定音调、音色和音量的鸟鸣声。
交互式编辑与优化
- 自然语言指令:ThinkSound模型支持用户通过自然语言指令对生成的音频进行编辑和优化。这种交互式编辑方式为用户提供了极大的灵活性和控制力。
- 实时反馈:模型可以根据用户的指令实时调整音频,并提供快速反馈。例如,如果用户指示“移除背景噪声”,模型会立即对音频进行处理,并展示处理结果。
AudioCoT多模态数据集的构建
为了支撑ThinkSound模型的结构化推理能力,阿里语音AI团队构建了AudioCoT多模态数据集。这个数据集的构建过程非常复杂,涉及多个阶段的数据采集、清洗、标注和增强。
数据采集
- 多来源整合:AudioCoT数据集整合了VGGSound、AudioSet等多个公开数据集,以及阿里语音AI团队自有的音频数据。
- 场景多样性:数据集涵盖了各种真实场景的音频,包括动物鸣叫、机械运转、自然环境声音、人类活动声音等。
数据清洗
- 自动化过滤:研究团队开发了一套自动化过滤系统,用于去除数据集中的低质量样本。该系统可以检测音频中的噪声、失真等问题,并自动过滤掉不合格的样本。
- 人工抽样校验:为了确保数据集的质量,研究团队还进行了人工抽样校验。他们随机抽取一部分样本,并由专业的音频工程师进行审核,以确保音频的清晰度和准确性。
数据标注
- 对象级标注:研究团队对数据集中的每个音频片段进行了对象级标注,标注了音频中包含的各种声音事件及其对应的物体。
- 指令级标注:为了支持模型的交互式编辑功能,研究团队还特别设计了指令级样本。这些样本包含了自然语言指令以及对应的音频编辑结果。例如,一个指令级样本可能包含“提取猫头鹰鸣叫时避免风声干扰”的指令,以及处理后的音频。
数据增强
- 音频增强:研究团队采用了多种音频增强技术,例如音量调整、噪声添加、混响模拟等,以增加数据集的多样性和泛化能力。
- 视觉增强:对于包含视频的数据,研究团队还采用了视觉增强技术,例如亮度调整、对比度增强、裁剪和缩放等,以提高模型对不同视觉条件的鲁棒性。
ThinkSound的应用前景
ThinkSound模型的开源将为音频生成领域带来深远的影响,并催生出各种创新应用。
影视音效制作
- 自动化音效生成:ThinkSound可以根据视频内容自动生成逼真的音效,从而大大提高影视制作的效率。
- 交互式音效编辑:影视制作人员可以使用自然语言指令对生成的音效进行编辑和调整,以满足特定的创作需求。
音频后期处理
- 噪声消除:ThinkSound可以有效地消除音频中的噪声,提高音频的清晰度和质量。
- 音效增强:ThinkSound可以增强音频中的特定音效,例如突出人声、增强环境氛围等。
游戏开发
- 沉浸式音效设计:ThinkSound可以为游戏场景生成逼真的音效,增强玩家的沉浸感。
- 动态音效生成:ThinkSound可以根据游戏中的事件动态生成音效,例如角色移动、武器发射、爆炸等。
虚拟现实
- 空间音频生成:ThinkSound可以生成具有空间感的音频,为虚拟现实用户提供更真实的听觉体验。
- 交互式音频环境:ThinkSound可以根据用户的交互行为动态生成音频,创造更具沉浸感的虚拟现实环境。
人机交互
- 语音助手:ThinkSound可以用于改善语音助手的语音生成质量,使其声音更自然、更具表现力。
- 无障碍交流:ThinkSound可以用于生成无障碍音频内容,帮助视力障碍人士更好地获取信息。
结论
阿里语音AI团队开源的ThinkSound模型是音频生成领域的一项重大突破。它通过引入思维链技术,实现了对视频内容的结构化理解,从而能够生成更逼真、更具表现力的音频。ThinkSound的开源将加速音频生成领域的技术普及,并为影视音效制作、音频后期处理、游戏开发、虚拟现实以及人机交互等领域带来创新应用。随着技术的不断发展,我们有理由相信,ThinkSound将在未来的人工智能领域扮演越来越重要的角色。








