
在人工智能领域,创新浪潮一波接着一波,技术突破层出不穷。今天,我们为您深度解读最新的AI前沿动态,聚焦那些正在重塑行业格局的关键技术与应用。从阿里通义实验室的音频生成模型,到谷歌的视频创作工具Veo3,再到昆仑万维的跨模态推理模型,每一次创新都为我们打开了通往未来世界的一扇窗。
阿里通义ThinkSound:链式推理赋能音频生成
阿里语音AI团队开源的ThinkSound模型,是全球首个支持链式推理的音频生成模型。这一创新摆脱了传统视频转音频技术的束缚,实现了高保真、强同步的空间音频生成。ThinkSound的独特之处在于其引入的思维链技术,让AI不仅仅是“看图配音”,而是能够“结构化理解画面”,从而生成更加自然、逼真的音频内容。
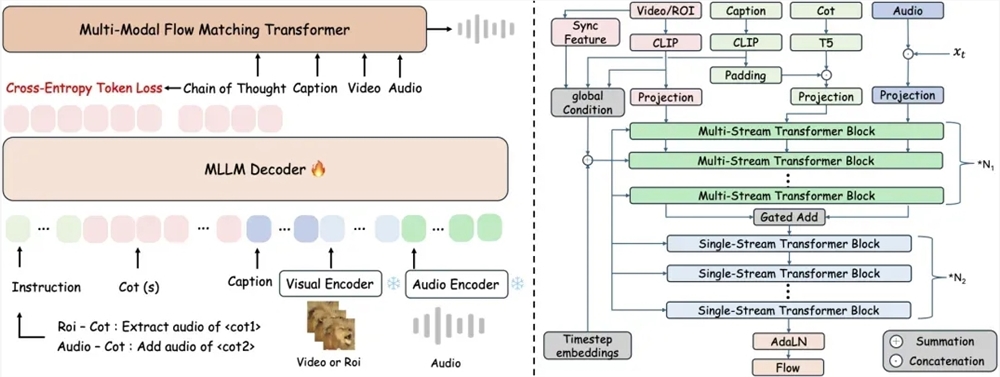
ThinkSound模型的核心在于将多模态大语言模型与统一音频生成架构相结合。这种结合使得模型能够更精准地合成音频,更好地理解和模拟真实世界的声音场景。为了训练出更强大的模型,阿里团队构建了一个包含2531.8小时高质量样本的AudioCoT数据集,这大大提升了模型处理复杂指令的能力。
目前,ThinkSound的代码和预训练权重已经开源,开发者可以免费获取并应用于自己的项目中。在多个测试集中,ThinkSound的表现均优于主流方法,这证明了其在音频生成领域的领先地位。这一技术的开源,无疑将加速AI音频技术的发展和应用。
谷歌Veo3:静态图片焕发生机
谷歌的Veo3视频生成工具迎来了重大升级,现在用户只需上传一张静态照片,即可生成高质量的动态视频内容。这一功能的实现,极大地降低了视频创作的门槛,让更多人能够轻松创作出引人入胜的视频作品。Veo3的核心功能包括保持角色在多个镜头下的一致性,并提供丰富的运镜功能,例如推镜头(Dolly in),这使得生成的视频更具专业感和艺术感。

用户可以根据自己的需求选择不同质量的生成模型,但需要消耗相应的credits。这意味着,更高质量的视频生成需要更多的计算资源。Veo3的升级,展示了AI在创作领域的巨大潜力,预示着未来的视频创作将更加智能化、个性化。
Hugging Face SmolLM3:小参数,大能量
Hugging Face发布了SmolLM3,这是一款具有30亿参数的小型开源模型。尽管参数规模不大,但SmolLM3的性能却超越了Llama-3.2-3B和Qwen2.5-3B等同类模型。SmolLM3支持多种语言处理,并具备双模式推理功能,同时公开了架构细节,这为研究者和开发者提供了更多的探索和优化空间。
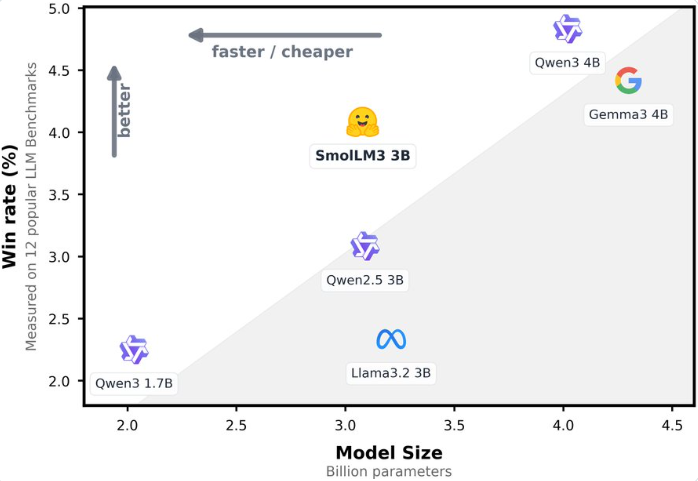
SmolLM3的一大亮点是其提供的两种推理模式:深度思考和非思考。这使得模型能够灵活应对不同的需求,在需要深入分析的场景下采用深度思考模式,而在对实时性要求较高的场景下则采用非思考模式。SmolLM3采用了先进的transformer解码器架构,并通过三阶段混合训练提升了自身的能力。这一模型的发布,为小型AI模型的发展注入了新的活力。
阿里WebSailor:网络智能体的崛起
阿里通义开源了网络智能体WebSailor,该智能体在中文和英文任务的BrowseComp评测集中表现出色,超越了DeepSeek R1和Grok-3等闭源模型,展现了强大的推理和检索能力。WebSailor的出现,标志着AI在网络信息处理方面取得了新的突破。银河证券指出,AI Agent经济已全面开启,并建议关注布局领先的SAAS企业。焦点科技和中科金财等相关上市公司已在AI Agent技术应用上有所布局,这进一步推动了智能体技术的发展。

WebSailor的开源,将加速AI Agent技术在各个领域的应用。未来,我们有望看到更多的智能体在网络上自主地完成各种任务,例如信息收集、数据分析、智能推荐等。AI Agent的普及,将极大地提高工作效率,并为人们带来更加便捷的生活体验。
Moonvalley Marey Realism v1.5:零版权风险的AI视频模型
Moonvalley推出的Marey Realism v1.5 AI视频生成模型在画质、创作自由度和法律合规性上实现了全面升级。该模型具备原生1080P视频生成能力,并且基于授权内容进行训练,彻底规避了版权风险。此外,Marey Realism v1.5能够精准解读复杂提示,为影视制作和广告创意提供了更安全、高效的工具。

Marey Realism v1.5不仅支持文本到视频的生成,还支持图像到视频的生成,这大大提升了创作的灵活性。该模型的出现,为AI视频生成领域树立了新的标杆,预示着未来的视频创作将更加注重版权保护和内容质量。
Vidu Q1:多图参考,一致性视频生成
Vidu Q1的“参考转视频”功能允许用户上传最多七张参考图像,生成视觉一致性极高的1080p视频。该技术通过语义融合确保多图像元素在视频中保持一致,解决了传统AI视频生成中的场景断裂或角色失真问题,为创作者提供了强大的工具。Vidu Q1的多图参考功能,使得AI视频生成更加精细化和个性化。通过上传多张参考图像,用户可以更准确地控制视频的内容和风格,从而创作出更符合自己需求的视频作品。语义融合技术的应用,则保证了视频中各个元素之间的高度一致性,避免了出现不协调或突兀的画面。
苹果AI客服助手:提升用户支持体验
苹果公司正在开发一款基于人工智能的“支持助手”,旨在为用户提供更智能和高效的客户服务体验。该功能已在Apple Support应用代码中被发现,未来将允许用户在联系客服前获得AI生成的解决方案,提高服务效率。这款AI客服助手有望大大缩短用户的等待时间,并提供更加个性化的解决方案。此外,该助手还可能支持上传文件,从而更全面地了解用户的问题。
飞书AI新品:企业级“豆包”
飞书发布了多款AI产品,包括知识问答、AI会议、Aily、飞书妙搭等,旨在加速AI在企业级应用中的落地。同时,飞书还推出了业界首个AI应用成熟度模型,帮助企业评估AI产品的实际效果。飞书的多款AI产品,涵盖了企业运营的各个方面,例如知识管理、会议协同、智能助手等。这些产品的推出,将极大地提高企业的工作效率和决策水平。AI应用成熟度模型的发布,则为企业选择和评估AI产品提供了重要的参考依据。
AI赋能教育:微软、OpenAI与Anthropic联合行动
美国教师联合会(AFT)联合微软、OpenAI和Anthropic成立全国人工智能教育学院,旨在为教师提供免费的AI工具培训,帮助他们更好地利用人工智能技术。该项目获得2300万美元资金支持,推动教育领域的技术变革。通过AI培训,教师们将掌握新的教学方法和工具,从而更好地引导学生学习和成长。AI教育学院的成立,将推动教育的民主化,确保技术服务于学生和教师,而不仅仅是少数人的特权。
昆仑万维Skywork-R1V3.0:跨模态推理的巅峰
昆仑万维发布Skywork-R1V3.0,展现出卓越的多模态推理能力,训练样本少但表现出色,达到了人类专家水平。Skywork-R1V3.0在跨模态推理中取得了76.0分,超越了多款闭源模型。该模型仅使用1.2万条微调样本和1.3万条强化学习样本进行训练,但在物理、逻辑和数学推理测试中表现优异,分别获得52.8分、59.7分和77.1分。Skywork-R1V3.0的成功,证明了在AI领域,高质量的数据和先进的算法同样重要。
人工智能的快速发展,正在深刻地改变着我们的生活和工作方式。从音频生成到视频创作,从智能客服到企业运营,AI的身影无处不在。我们有理由相信,在不久的将来,AI将为我们带来更多的惊喜和可能性。








