
在人工智能领域,Agent模式的出现标志着一个全新的发展阶段。过去,我们主要依赖AI的语言能力,而现在,AI开始具备实际操作能力,能够独立完成任务。OpenAI发布的Agent模式,与之前的Manus模式有诸多相似之处,但同时也带来了新的可能性。
OpenAI的Agent模式
2025年7月18日,OpenAI的研究人员介绍了他们即将推出的Agent模式。通过Agent模式,用户可以直接向ChatGPT提出具体需求,例如购买婚礼所需的鞋子、设计宠物周边产品并下单打印,或者查找信息并生成PPT。ChatGPT会在虚拟环境中自主操作,逐步完成任务。
在演示中,完成一个复杂任务大约需要10分钟,但完成度非常高。ChatGPT可以在虚拟环境中调用文本浏览器、可视化浏览器和终端。通过终端,还可以进一步调用云服务API、图片生成器和运行代码。
更重要的是,这次OpenAI将Agent模式开放给更多的用户,Plus和Team用户每月可以使用40次。
Sam Altman表示,这是一种全新的范式,就像我们学会上网并学会甄别诈骗信息一样,整个社会需要学习如何与Agent安全地交互和共存。
Agent模式的功能
OpenAI的Agent模式与Manus模式类似,用户提出需求后,系统会自动开启一个虚拟机,开始自动执行任务。在执行过程中,Agent会反复请求用户确认,并允许随时手动接管。用户还可以在任务中途植入新需求,进行实时交互。
Agent模式可以调用三种工具:文本浏览器、可视化浏览器和终端。模型可以自主选择切换各种工具。
- 文本浏览器:负责大量浏览文字,搜寻信息。
- 可视化浏览器:负责定位信息后直接模拟键鼠交互,或读取图像信息。
- 终端:可以运行代码,生成PPT、Excel等文件,并调用云端API。
案例一:婚礼规划
研究人员提出要规划参加朋友婚礼的事宜,包括挑选符合着装要求的礼服、预订酒店和提供礼物建议。
ChatGPT首先切换到Agent模式,启动虚拟电脑并加载环境。然后,ChatGPT使用文本浏览器打开用户提供的网页,搜索婚礼信息、着装要求和天气等。在需要进一步确认婚礼日期时,模型会提出澄清请求,用户也可以选择让它自己继续推理。
在找到天气和场地信息后,AI开始推荐合适的礼服,并切换到可视化浏览器检查礼服效果。完成任务后,继续搜索酒店和礼物。
最终,AI给出的婚礼出行建议报告非常详细,涵盖了服装、酒店和礼物,甚至附上了在线预订网站的截图。完成这份报告仅花费了10分钟。

案例二:定制贴纸
研究人员要求为团队的吉祥物(一只狗狗)制作一批笔记本贴纸,并下单500张。
Agent直接利用终端功能,调用图像生成工具(Image Gen API)来生成一张动漫风格的狗狗插画,作为贴纸的设计图案。
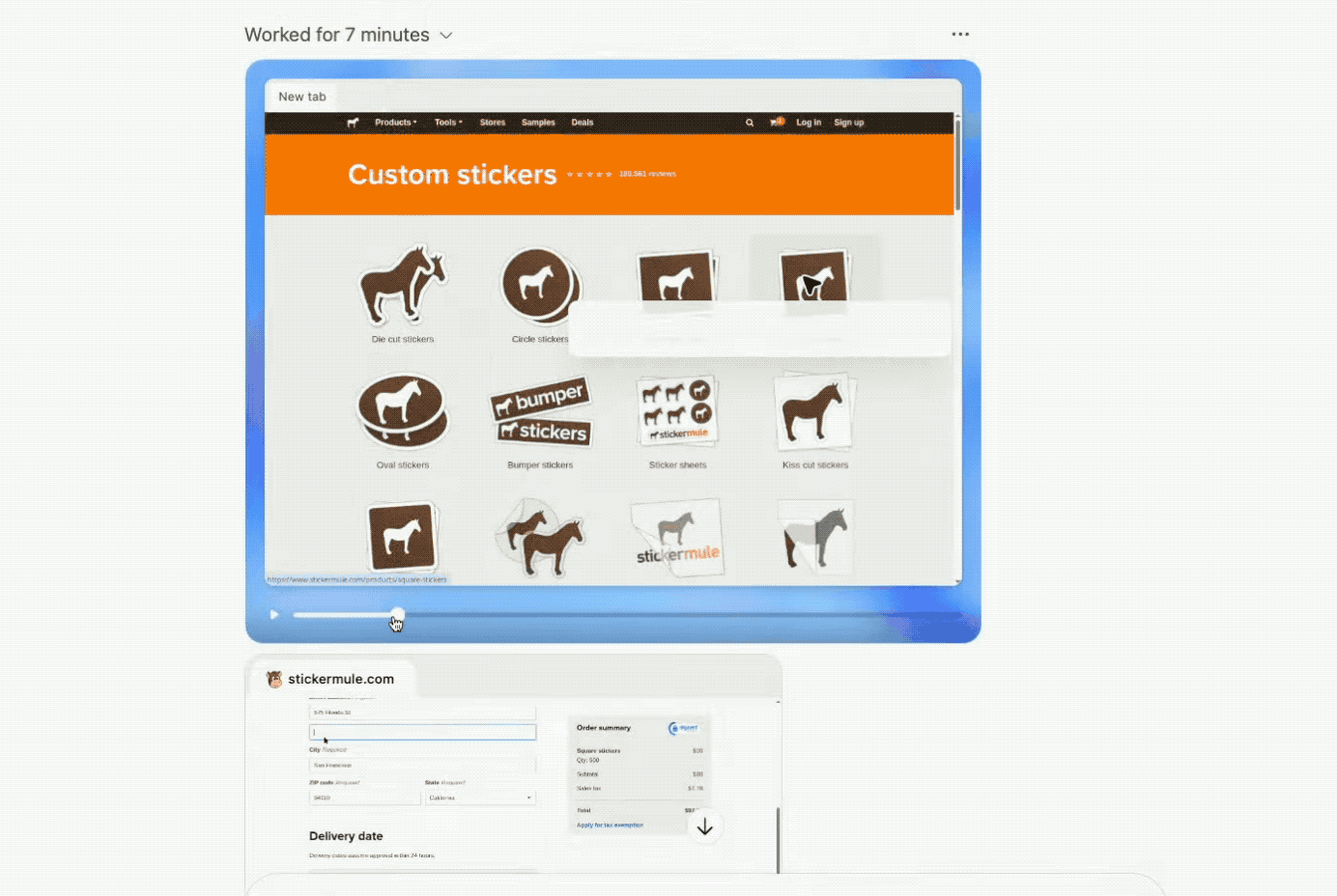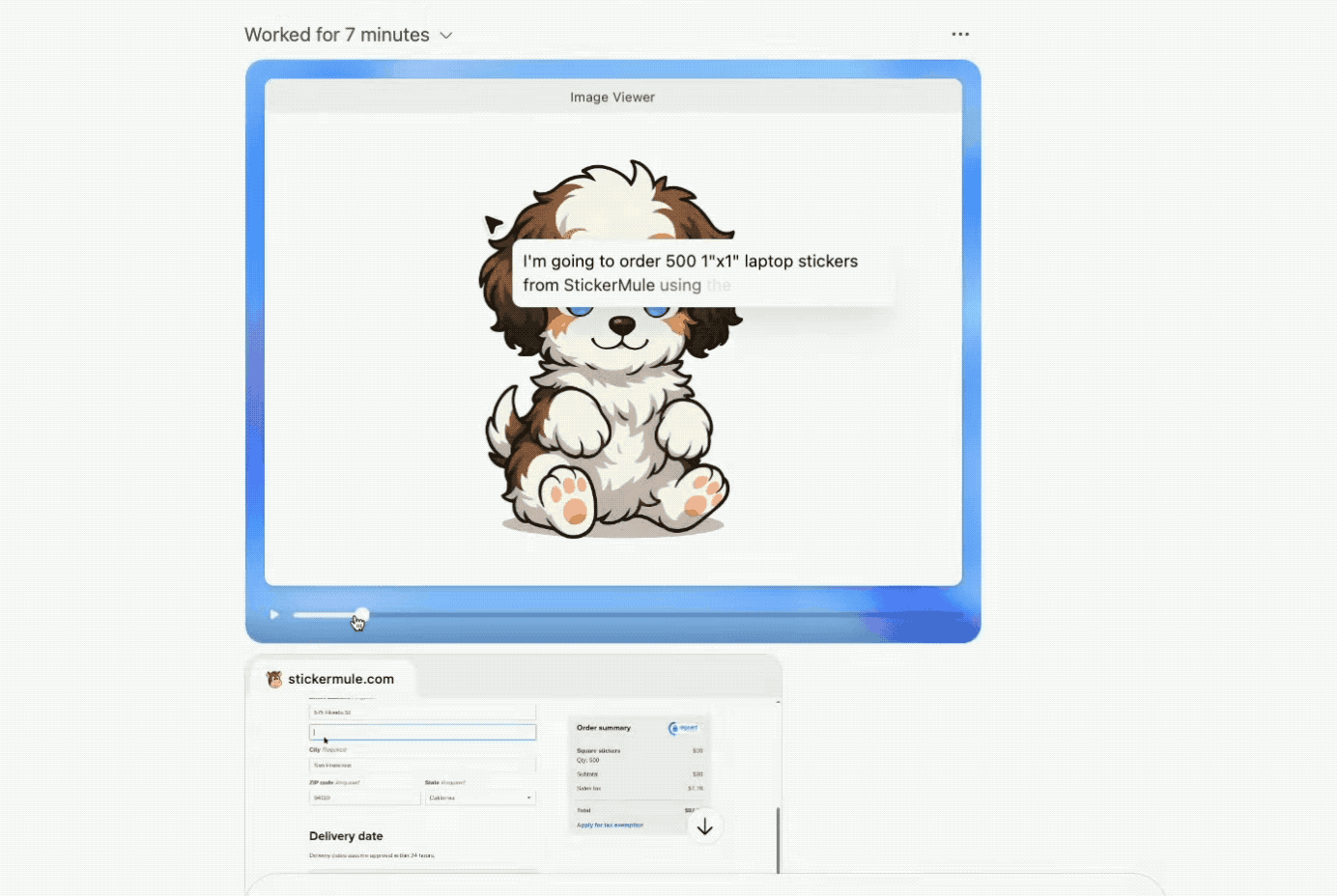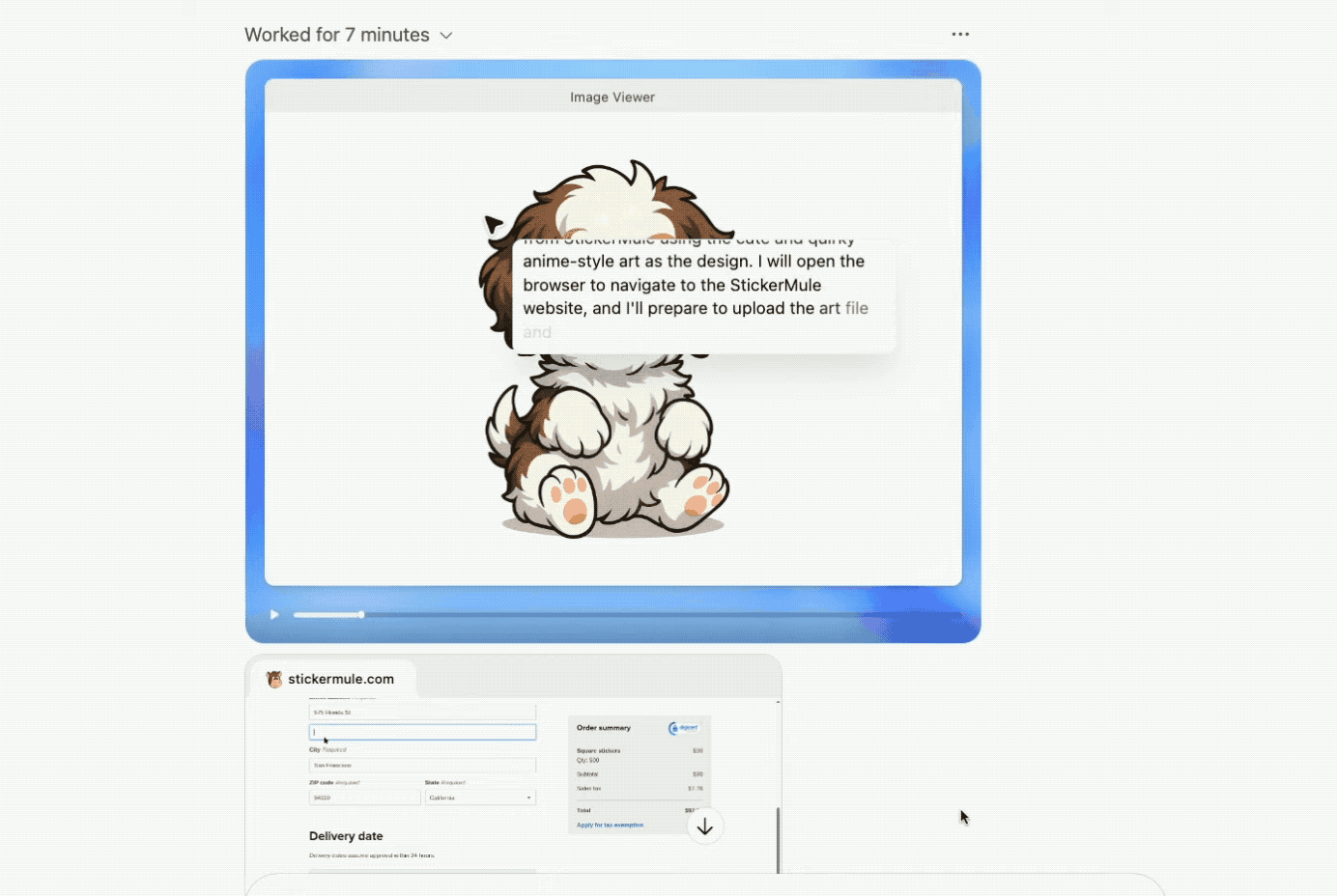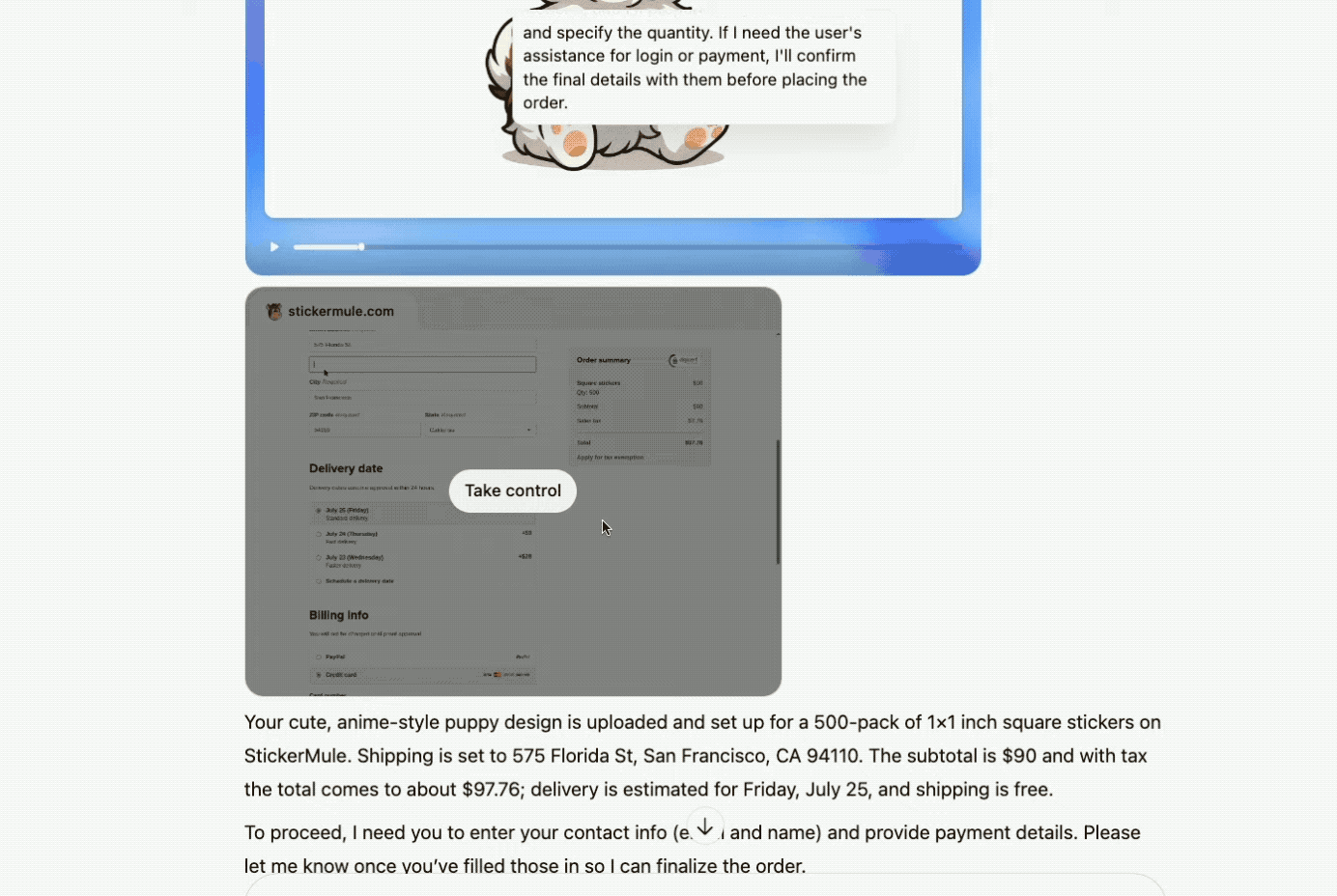
接着,Agent打开浏览器访问Sticker Mule网站,将设计好的图上传到网站,填写贴纸数量和尺寸等,并将商品加入购物车。
最后,它主动向用户确认是否使用这张插画、是否继续下单,以及是否需要用户自己输入信用卡付款,或让它继续完成。
任务停留在让用户接管输入信用卡环节,花费了7分钟。
案例三:生成PPT和旅行攻略
Agent还可以连接Google Drive API,读取文件后生成PPT。此外,它还可以查询赛季日程,生成详细的旅行电子表格和带标注地图的旅行攻略。这个任务比较复杂,Agent大约花费了25分钟完成。
AI能力的提升
OpenAI此次推出的Agent模式,实际上是Operator和Deep Research两项工具的组合。
- Operator:原本只开放给Pro用户的浏览器Agent工具,能够分析图形操作界面并做出一定的操作。
- Deep Research:一个深入研究的分析工具,可以阅读大量的网页,直接生成一份调研报告。
OpenAI发现,很多用户用Operator写的提示词更像Deep Research的任务,而Deep Research用户则希望增加登录网站和访问受保护资源的能力,这正是Operator的功能。因此,团队决定将两个产品融合起来。
此次Operator和Deep Research的融合非常成功,避开了只使用浏览器的图形界面去阅读文字材料的低效,让最后能形成深度报告的时长变得不高。
OpenAI还提到了在为模型提供多种工具后,如何训练模型。
他们仍然使用强化学习。一开始,模型会尝试用所有工具解决一个相对简单的问题,即它刚开始不会判断哪个工具更合适。
通过奖励那些解决问题更高效、更合理的行为,模型能逐渐学会如何使用这些工具,以及在什么情况下使用哪个工具最合适。
例如,如果是做创意作品,它会先搜索公开资源,然后用终端写代码、编译作品,最后用可视化浏览器验证结果。
基准测试成绩
OpenAI在Humanities Last Exam(人类的最后一场大考)中,能够使用浏览器、电脑和终端的Agent模式模型,已经能够达到42%的高分,相比于完全不使用工具的o3,有一倍的提升。
在世界范围内也是领先的——Grok宣布带工具的Grok 4 Heavy在测试中取得45%的成绩。
使用工具后的高级数学推理能力也有了进一步的提升。
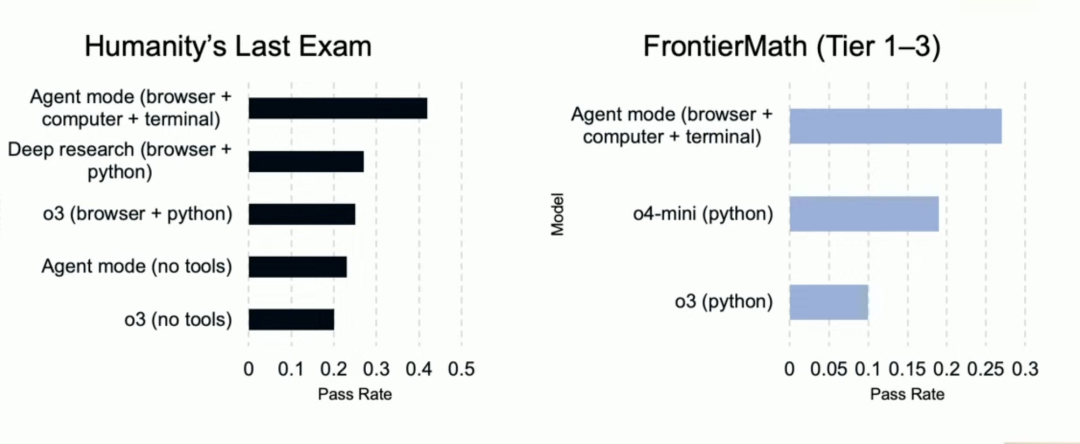
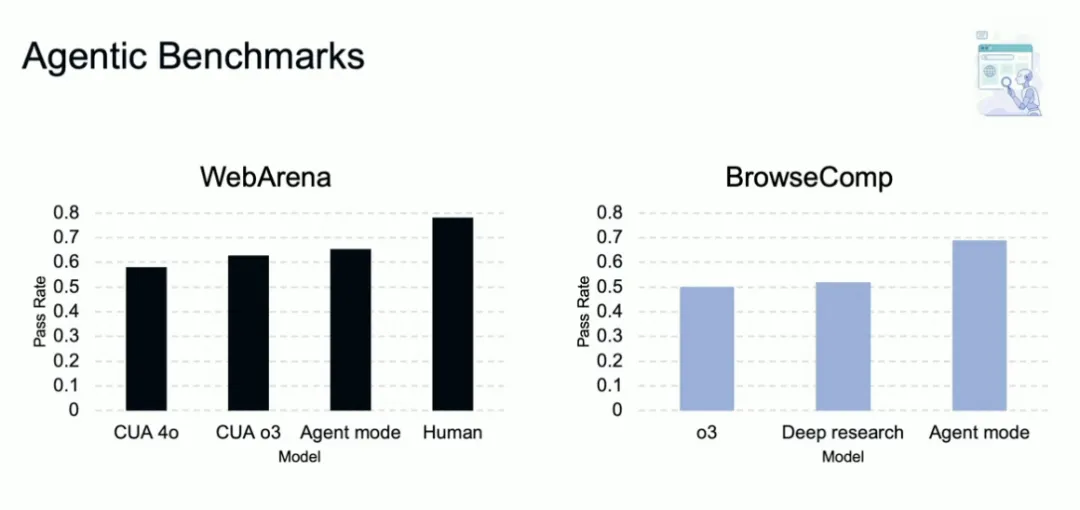
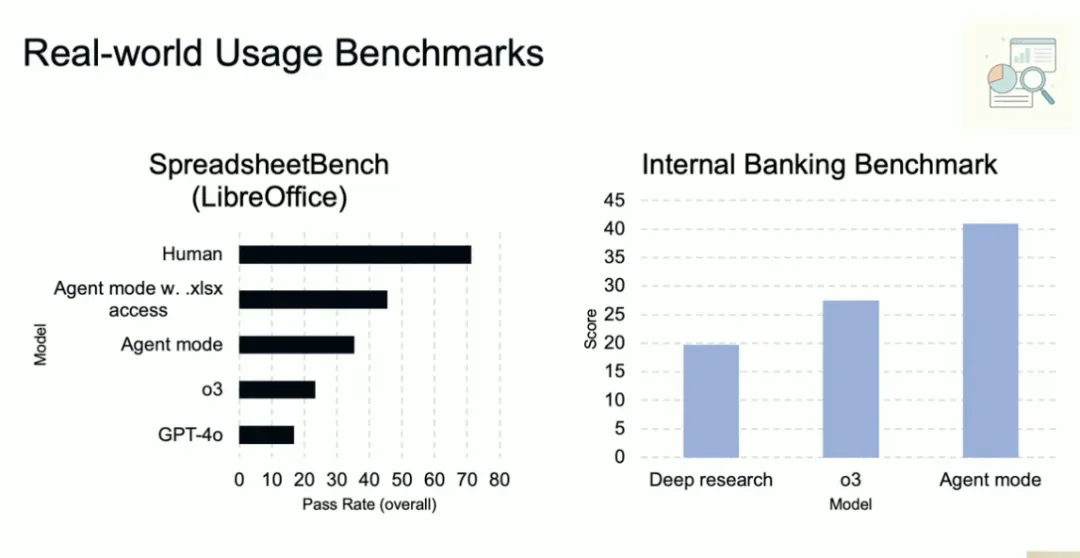
在公布的基准中,有两个是和人类的对比:在网页中操作的能力(WebArena)和操作电子表格的能力(SpreadsheetBench)。可以看到,两项基准中,Agent模式仍然不如人类,但是网页操作已经追近了人类水平。
这意味着,即便只是整合这些本身尚不如人类的工具,大模型也能获得显著的能力提升。Agent时代,大模型能力的提升还有更高的天花板。
与Agent共处的时代
毫无疑问,Agent是2025年AI领域的绝对风口。
但风口之下,用户的真实体感往往并不完美:任务运行时间过长,稍复杂的任务就频频出错。一位早期Operator用户评论道“每次点击和滚动,都像在炎热夏日中游泳。”
此次OpenAI将Operator与Deep Research融合,或许正是为了缓解这种“粘滞感”,让Agent真正跑起来。
当OpenAI自己下场,一个更直接的问题摆在了所有类似Manus的第三方开发者面前:这究竟是会催生一个繁荣的Agent应用生态,还是会直接碾压所有创业公司?答案尚不明朗。
而对于用户而言,一个更切身的挑战随之而来:隐私和安全。
当AI在我们看不见的虚拟机里,点开一个网页、输入我们的个人信息时,谁来保证安全?
如果它被钓鱼网站骗走了我们的信用卡号,责任谁负?
OpenAI对此的回应是,他们会采取极其严格的审查和安全措施,但它也希望整个社会都能花时间去适应和建立规范。
Agent时代,确实是继Chat时代之后,一个截然不同的新阶段。
在Chat时代,我们学会了适应AI的“嘴”——我们慢慢习惯了它的幻觉,并学会在它的花言巧语中甄别真伪。这是一个关于“信息可信度”的挑战。
而在Agent时代,挑战则完全转向了AI的“手”。我们需要回答一系列全新的问题:我们究竟愿意多信任AI?我们又愿意把多大的权限交出去,让它代替我们完成多少现实世界的事情?
而我们与AI的关系,也将因此被重新定义。
从更宏观的视角看,Agent的爆发也将再次将一个老问题以更尖锐的方式推到我们面前:当AI能真正“干活”时,我们的工作会怎样?
当AI能独立完成一份包含数据检索、图像查证的复杂报告,并直接完成在线预订时,白领们的工作究竟是被赋能加速,还是被彻底威胁?
答案尚在风中飘。
但无论我们欢迎、恐惧还是茫然,一个由Agent驱动的、更自动化的新时代,确实正在加速到来。








