
在人工智能领域,特别是大语言模型(LLM)的研究中,如何有效地处理和理解文本数据一直是核心挑战之一。传统方法,例如字节对编码(Byte Pair Encoding, BPE),在文本处理的初期阶段将文本分解成预定义的固定单元,并基于这些单元构建静态词汇表。尽管这种方法被广泛应用,但其固有的局限性也日益显现。一旦完成分词,模型处理文本的方式便缺乏灵活性,尤其是在处理低资源语言或具有复杂字符结构的文本时,效果往往难以达到预期。
为了克服这些限制,Meta 研究团队推出了一种名为 AU-Net 的创新架构。AU-Net 采用自回归的 U-Net 结构,从根本上改变了传统的文本处理模式。它能够直接从原始字节开始学习,灵活地将字节组合成单词、词组,甚至是包含多达四个单词的组合,从而形成多层次的序列表示。
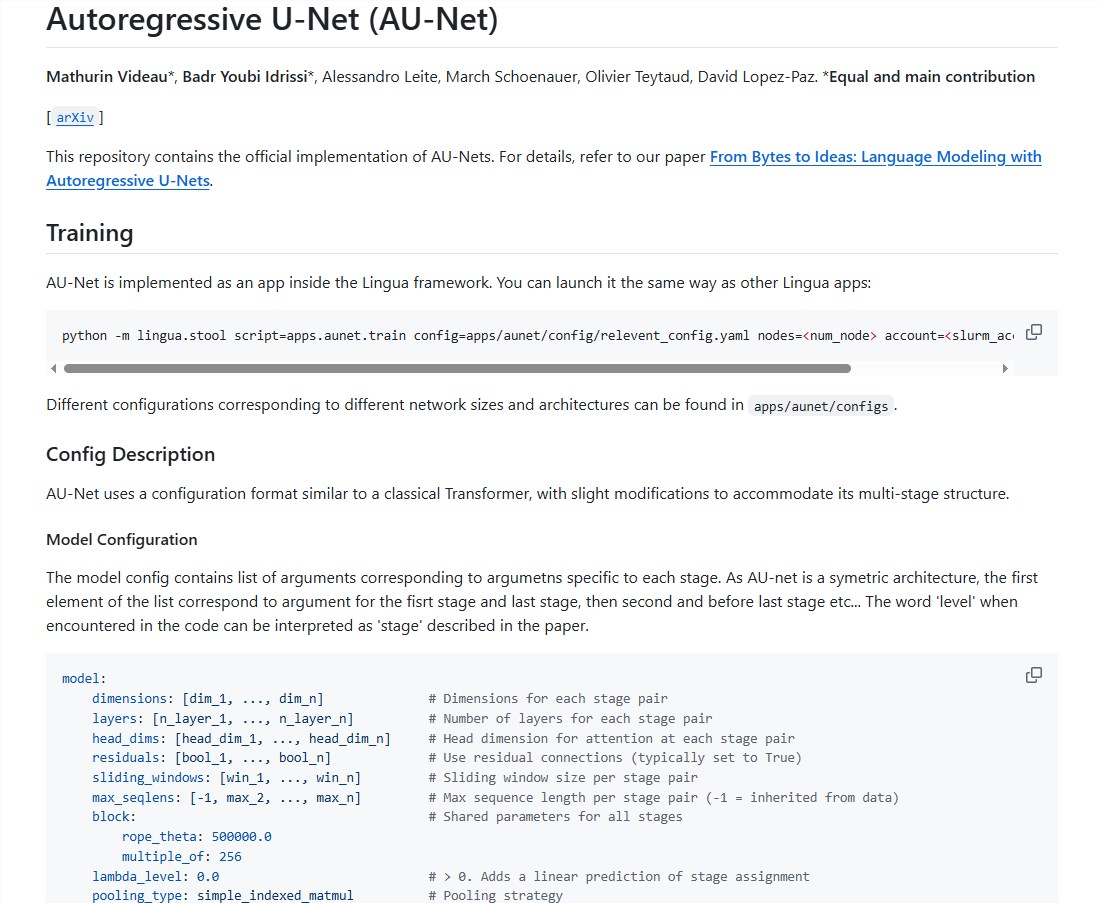
AU-Net 的设计灵感来源于医学图像分割领域的 U-Net 架构。U-Net 架构以其独特的收缩路径和扩张路径而闻名,AU-Net 借鉴了这一结构。收缩路径负责压缩输入的字节序列,将其合并为更高层次的语义单元,从而提取文本的宏观语义。而扩张路径则负责将这些高层次信息逐步还原,恢复到原始序列的长度,同时融合局部细节,使模型能够在不同层次上捕捉文本的关键特征。
AU-Net 的收缩路径包含多个阶段。在第一阶段,模型直接处理原始字节,并采用限制注意力机制来确保计算的可行性。接着,在第二阶段,模型在单词边界处进行池化操作,将字节信息抽象为单词级别的语义信息。在第三阶段,池化操作在每两个单词之间进行,以捕捉更大范围的语义信息,从而增强模型对文本含义的理解。
扩张路径则负责逐步还原压缩后的信息,采用多线性上采样的策略,使得每个位置的向量能够根据序列中的相对位置进行调整,从而优化高层次信息和局部细节的融合。此外,跳跃连接的设计保证了在还原过程中不会丢失重要的局部细节信息,从而提升模型的生成能力和预测准确性。
在推理阶段,AU-Net 采用自回归的生成机制,确保生成的文本既连贯又准确,同时提高了推理效率。这种创新架构为大语言模型的发展提供了新的思路,展现了更强的灵活性和适用性。
AU-Net:文本处理的新范式
AU-Net 的出现,无疑为自然语言处理领域带来了一股清新的空气。它不仅解决了传统分词方法在处理复杂文本时的局限性,还在模型架构上进行了创新,为未来的研究提供了新的方向。
传统分词技术的挑战
传统的分词技术,如 BPE,虽然在很多场景下表现良好,但其固有的静态词汇表和固定的分词方式,使其在面对以下挑战时显得力不从心:
- 低资源语言:对于缺乏大量标注数据的低资源语言,构建有效的词汇表非常困难。BPE 算法依赖于语料库中词汇的频率,而低资源语言的语料库往往不够丰富,导致分词效果不佳。
- 特殊字符结构:某些语言或领域中存在大量的特殊字符结构,如医学术语、化学公式等。这些特殊字符结构往往具有复杂的内部规则,传统的分词方法难以准确识别和处理。
- 动态语境:语言是不断变化的,新的词汇和表达方式层出不穷。静态的词汇表无法及时更新,导致模型无法理解和处理新的语言现象。
AU-Net 的创新之处
AU-Net 通过其独特的架构和处理方式,有效地克服了传统分词技术的局限性:
自回归 U-Net 结构:AU-Net 借鉴了图像分割领域的 U-Net 结构,采用收缩路径和扩张路径相结合的方式。收缩路径负责提取文本的宏观语义信息,扩张路径负责还原局部细节信息。这种结构使得模型能够同时捕捉文本的全局和局部特征。
直接从原始字节学习:AU-Net 直接从原始字节开始学习,避免了传统分词方法对预定义词汇表的依赖。这意味着模型可以处理任意字符结构的文本,无需进行额外的预处理。
动态组合字节:AU-Net 能够灵活地将字节组合成单词、词组,甚至是包含多个单词的组合。这种动态组合的方式使得模型能够更好地适应不同的语境和语言现象。
多层次序列表示:AU-Net 能够生成多层次的序列表示,从字节、单词到词组,每个层次都包含不同的语义信息。这种多层次的表示方式使得模型能够更全面地理解文本的含义。
AU-Net 的技术细节
为了更好地理解 AU-Net 的优势,我们深入探讨其技术细节:
收缩路径
- 第一阶段:模型直接处理原始字节,采用限制注意力机制来保证计算的可行性。限制注意力机制可以减少计算量,同时保留重要的语义信息。
- 第二阶段:模型在单词边界处进行池化操作,将字节信息抽象为单词级别的语义信息。池化操作可以降低序列的长度,减少计算复杂度。
- 第三阶段:模型在每两个单词之间进行池化操作,以捕捉更大范围的语义信息。这种操作可以增强模型对文本含义的理解。
扩张路径
- 多线性上采样:扩张路径采用多线性上采样的策略,使得每个位置的向量能够根据序列中的相对位置进行调整。这种策略可以优化高层次信息和局部细节的融合。
- 跳跃连接:跳跃连接的设计保证了在还原过程中不会丢失重要的局部细节信息。这种设计可以提升模型的生成能力和预测准确性。
自回归生成机制
- AU-Net 在推理阶段采用自回归的生成机制,即根据已经生成的文本来预测下一个词。这种机制可以确保生成的文本既连贯又准确,同时提高推理效率。
AU-Net 的应用前景
AU-Net 的创新架构使其在多个领域具有广泛的应用前景:
- 机器翻译:AU-Net 可以直接处理原始字节,无需进行分词,从而避免了分词错误对翻译质量的影响。尤其是在处理低资源语言时,AU-Net 的优势更加明显。
- 文本摘要:AU-Net 能够捕捉文本的宏观语义信息和局部细节信息,从而生成更准确、更全面的文本摘要。
- 文本生成:AU-Net 的自回归生成机制可以生成连贯、流畅的文本,适用于各种文本生成任务,如文章创作、对话生成等。
- 信息检索:AU-Net 可以用于构建更高效的信息检索系统,通过理解文本的深层语义,提高检索的准确率和召回率。
AU-Net 的局限性与未来发展方向
尽管 AU-Net 具有诸多优势,但仍然存在一些局限性:
- 计算复杂度:AU-Net 的架构相对复杂,计算复杂度较高,需要大量的计算资源进行训练和推理。
- 可解释性:AU-Net 的内部机制相对复杂,难以解释其决策过程,这在某些应用场景下可能是一个问题。
未来的研究可以集中在以下几个方向:
- 优化模型架构:简化 AU-Net 的架构,降低计算复杂度,使其更易于部署和应用。
- 提高可解释性:研究 AU-Net 的内部机制,提高其可解释性,使其在更多领域得到应用。
- 探索新的应用场景:将 AU-Net 应用于更多的自然语言处理任务,如情感分析、文本分类等。
结论
AU-Net 作为一种创新的文本处理架构,为大语言模型的发展提供了新的思路。它通过自回归的 U-Net 结构,直接从原始字节开始学习,灵活地将字节组合成单词和词组,从而形成多层次的序列表示。AU-Net 的出现,有望改变传统的文本处理模式,为自然语言处理领域带来新的突破。

