
AI 辅助编程:效率提升还是适得其反?
大型语言模型(LLM)在各行各业的应用日益广泛,AI 公司纷纷标榜其在编程领域的巨大潜力,声称能显著提高程序员的生产力和整体效率。然而,一项最新的随机对照试验却得出了截然不同的结论:经验丰富的开源代码开发者在使用 AI 工具时,效率反而降低了。
研究背景与方法
由 METR(模型评估与威胁研究)的研究人员进行的这项研究,招募了 16 位在特定开源代码仓库拥有多年经验的软件开发者。研究人员跟踪记录了这些开发者在维护代码仓库过程中执行的 246 项独立任务,包括缺陷修复、功能添加和代码重构等日常工作。其中,一半的任务允许开发者使用 AI 工具(如 Cursor Pro 和 Anthropic 的 Claude),另一半则禁止使用 AI 辅助。
在任务分配之前,研究人员对每项任务的预期完成时间进行了预测,并以此作为平衡各实验组任务难度的依据。此外,评审人员反馈的 pull request 修改时间也被纳入整体评估。
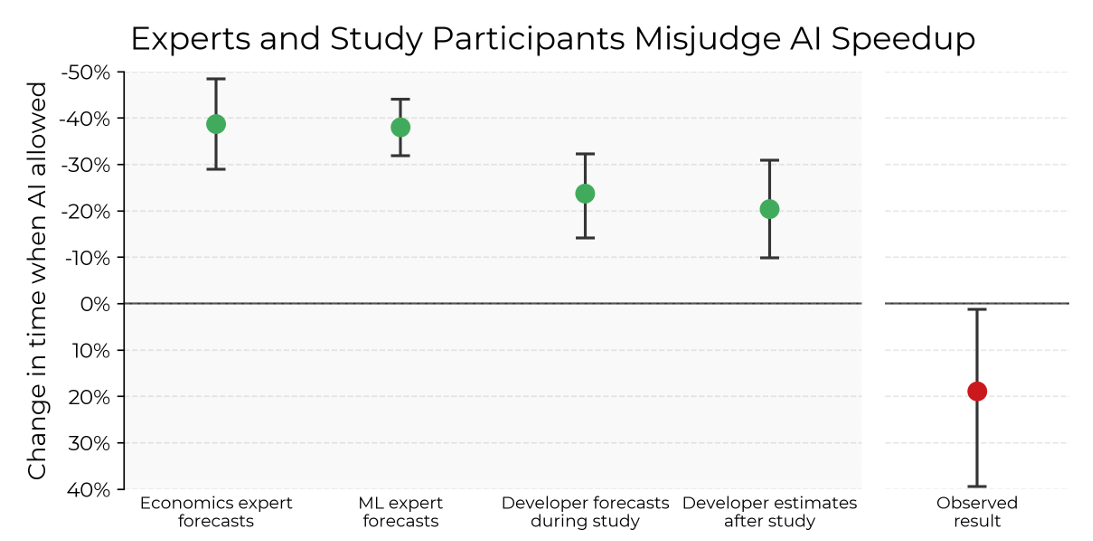
实验结果:事与愿违
在实验开始前,参与研究的开发者们普遍认为 AI 工具能将任务完成时间缩短 24%。即使在完成任务后,他们仍然相信 AI 平均提升了 20% 的效率。然而,实际结果却显示,使用 AI 辅助的任务比未使用 AI 的任务平均慢了 19%。
效率权衡:AI 的瓶颈何在?
通过分析部分开发者的屏幕录像数据,METR 的研究人员发现,AI 工具确实减少了开发者在编写代码、测试/调试以及阅读/搜索信息等方面花费的时间。然而,这些节省的时间最终被以下因素所抵消:
- 审查 AI 输出:开发者需要花费大量时间来检查 AI 生成的代码,确保其质量和准确性。
- 提示 AI 系统:为了获得所需的代码,开发者需要不断地调整和优化提示语。
- 等待 AI 生成:AI 生成代码需要时间,尤其是在处理复杂任务时。
- 闲置/额外开销时间:屏幕录像显示,有时开发者会因为 AI 工具的限制而无所事事。
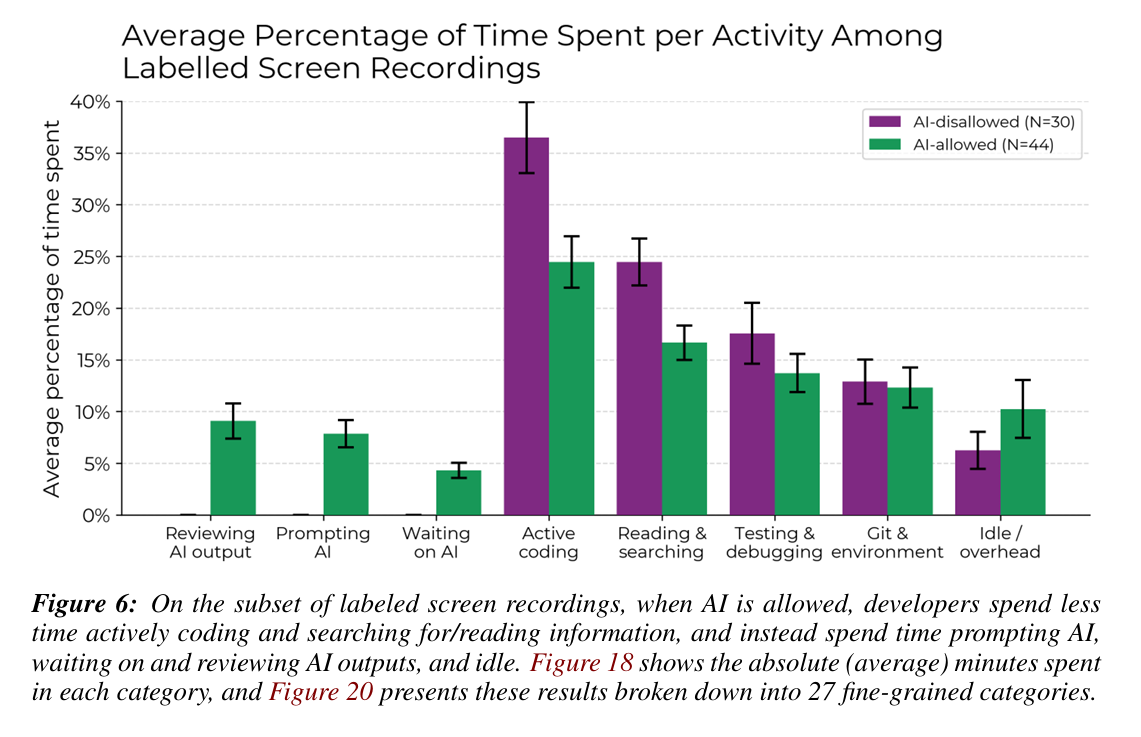
研究还发现,开发者平均只接受了 AI 生成代码的 44%,这意味着大部分代码都需要进行修改。在 AI 辅助的任务中,代码审查占据了总任务时间的 9%。
与其他研究的对比
METR 的研究结果似乎与其他一些研究相矛盾,后者表明 AI 工具可以提高编码效率。然而,这些研究通常以总代码行数或完成的任务数量来衡量生产力,而这些指标并不能真实反映编码效率。
此外,许多现有的编码基准测试侧重于专门为测试而设计的合成算法任务,难以与实际代码库的工作相提并论。METR 研究中的开发者表示,他们所处理的代码仓库的复杂性(平均 10 年历史,超过 100 万行代码)限制了 AI 的帮助。研究人员指出,AI 无法利用关于代码库的“重要隐性知识或背景”,而开发者对代码仓库的高度熟悉则提高了他们的编码效率。
研究结论与展望
METR 的研究人员认为,当前的 AI 编码工具可能不适合于对质量标准要求极高或存在许多隐性要求(如文档、测试覆盖率或代码格式)的场景。虽然这些因素可能不适用于许多涉及较简单代码库的实际经济环境,但它们可能会限制 AI 工具在复杂、真实场景中的影响。
尽管如此,研究人员对 AI 工具的未来发展仍然持乐观态度。他们认为,如果能够提高 AI 系统的可靠性、降低延迟或生成更相关的输出(通过提示工程或微调等技术),那么 AI 仍有可能提高程序员的效率。他们表示,初步证据表明,最新版本的 Claude 3.7 “通常可以正确实现我们研究中包含的几个代码仓库中的核心功能”。
案例分析:AI 在复杂开源项目中的局限性
以 Linux 内核的开发为例,这是一个庞大而复杂的开源项目,拥有数百万行代码和无数的贡献者。在这个项目中,代码的质量、稳定性和安全性至关重要。开发者需要深入理解内核的架构、设计和实现细节,才能有效地进行开发和维护。
在这种情况下,AI 编码工具可能会遇到以下挑战:
- 缺乏上下文理解:AI 工具难以理解 Linux 内核的整体架构和设计理念,可能生成不符合内核规范或与其他模块不兼容的代码。
- 难以处理隐性知识:Linux 内核的开发涉及大量的隐性知识,例如代码风格、命名规范、最佳实践等。AI 工具可能无法捕捉到这些隐性知识,导致生成的代码质量不高。
- 难以保证代码质量:Linux 内核的代码需要经过严格的测试和审查,才能确保其质量和稳定性。AI 工具可能无法生成高质量的代码,需要人工进行大量的修改和调试。
因此,在 Linux 内核这种复杂的开源项目中,AI 编码工具可能无法显著提高开发效率,甚至可能适得其反。
数据佐证:AI 辅助编程的实际效果
除了 METR 的研究之外,其他一些研究也对 AI 辅助编程的实际效果进行了评估。例如,GitHub Copilot 是一项基于 AI 的代码补全服务,它可以根据开发者的输入自动生成代码。一项针对 GitHub Copilot 的研究发现,使用该服务的开发者平均可以节省 55% 的时间来完成编码任务。
然而,这项研究也指出,GitHub Copilot 可能会生成不安全或有偏见的代码,需要开发者进行仔细的审查和修改。此外,GitHub Copilot 的效果还取决于开发者的经验水平和任务的复杂程度。对于经验丰富的开发者和复杂的任务,GitHub Copilot 的帮助可能不大。
总结与展望
总的来说,AI 辅助编程的实际效果取决于多种因素,包括 AI 工具的质量、开发者的经验水平、任务的复杂程度以及代码库的特点。在某些情况下,AI 工具可以显著提高编码效率,但在其他情况下,它们可能会适得其反。
未来,随着 AI 技术的不断发展,我们可以期待 AI 编码工具在可靠性、延迟和输出质量方面得到进一步的提升。此外,通过提示工程和微调等技术,我们可以更好地利用 AI 工具来提高编码效率。然而,我们也要认识到 AI 辅助编程的局限性,并将其应用于合适的场景中。
METR 的研究有力地证明了,在某些复杂的真实编码场景中,AI 在编码任务中的作用可能存在很大的局限性。虽然 AI 在编程领域的应用前景广阔,但我们仍需谨慎评估其在不同场景下的实际效果,避免盲目乐观。
本文深入探讨了 AI 辅助编程的现状与挑战,通过案例分析和数据佐证,为读者呈现了 AI 在编程领域应用的真实面貌。希望本文能为开发者和研究人员提供有价值的参考,共同推动 AI 辅助编程技术的健康发展。

