
在人工智能领域,特别是自然语言处理(NLP)方向,模型创新层出不穷。近日,字节跳动Seed团队发布了一项引人注目的实验性成果——Seed Diffusion Preview,这是一种基于扩散的语言模型,旨在探索下一代语言模型的基础框架。这一模型的发布,无疑为语言模型的未来发展方向提供了新的思路和可能性。
Seed Diffusion Preview 的核心目标是突破现有自回归(AR)模型在推理速度和全局控制上的瓶颈。自回归模型在生成文本时,通常需要逐个 token 进行预测,这在长文本生成时会显著降低效率。而扩散模型,已经在图像和视频合成等连续数据领域展现出强大的能力,其从粗到精的生成范式,为解决语言模型的效率问题提供了借鉴。
然而,将扩散模型应用于自然语言处理领域并非易事。自然语言是离散的,而标准的扩散过程则更适用于连续状态空间。这种不兼容性构成了将扩散模型应用于自然语言处理的根本挑战。尽管如此,研究者们普遍认为,离散扩散模型在可扩展性和生成效果上具有巨大的潜力,值得深入探索。
为了克服这些挑战,Seed Diffusion Preview 采用了多项关键技术创新,这些创新共同构成了其独特的技术架构:
两阶段课程学习: 该策略包含两个阶段:基于掩码的扩散训练和基于编辑的扩散训练。在基于掩码的扩散训练阶段,模型学习如何根据上下文补全被掩盖的部分文本,这有助于提升模型的局部上下文理解能力。而在基于编辑的扩散训练阶段,模型则需要评估和修改已生成的代码,从而提升全局代码的合理性。
这种两阶段学习策略,类似于人类学习语言的过程。首先,我们学习如何理解和使用单个词语和短语(基于掩码的扩散训练),然后,我们学习如何将这些词语和短语组合成有意义的句子和段落,并不断修改和完善我们的表达(基于编辑的扩散训练)。
约束顺序扩散: 在代码生成任务中,代码的结构和依赖关系至关重要。约束顺序扩散通过引入代码的结构化先验知识,引导模型学习正确的依赖关系。这意味着模型在生成代码时,会更加关注代码的语法结构和语义逻辑,从而生成更符合规范、更容易理解和执行的代码。
例如,在生成一个函数调用时,模型需要先确定函数名,然后才能确定函数的参数。约束顺序扩散可以确保模型按照正确的顺序生成代码,避免出现语法错误或逻辑错误。
同策略学习: 同策略学习的目标是优化生成步数,从而提升模型的推理速度。在扩散模型中,生成过程通常需要多个步骤,每个步骤都需要消耗计算资源。同策略学习通过智能地调整生成步数,可以在保证生成质量的前提下,显著减少计算量,提升推理速度。
这种策略类似于在绘画时,画家会根据画面的复杂程度和细节要求,选择不同的笔触和绘画步骤。对于简单的画面,画家可能会使用较少的笔触,而对于复杂的画面,则需要更多的笔触。
块级并行扩散采样方案: 传统的扩散模型通常是串行生成,即每个 token 都需要依赖于前一个 token 的生成结果。块级并行扩散采样方案则可以在保持因果顺序的同时,实现高效的块级推理。这意味着模型可以同时生成多个 token,从而显著提升生成速度。
这种方案类似于在写作时,我们可以先写好文章的大纲,然后再逐步填充每个段落的内容。在填充每个段落的内容时,我们可以并行地进行研究、写作和编辑,从而提高写作效率。
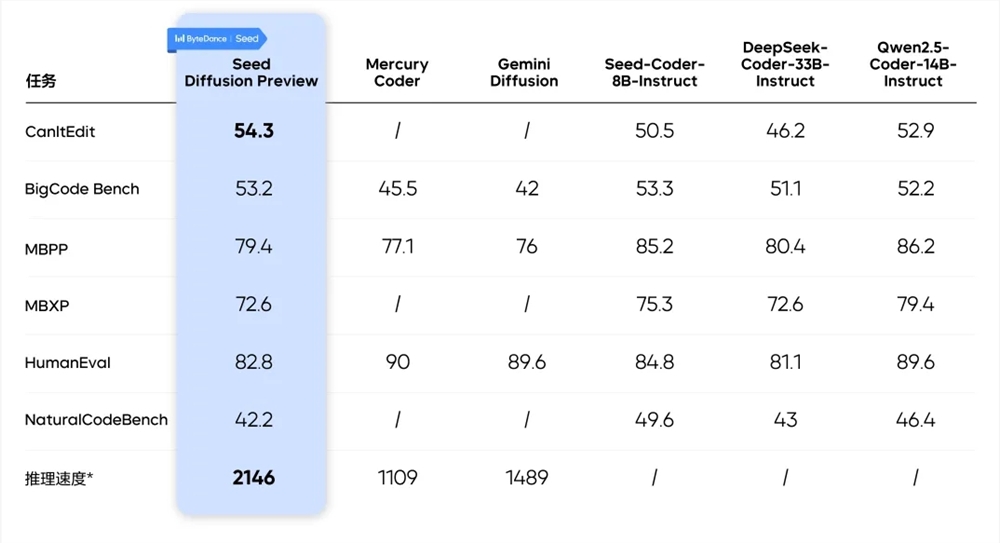
实验结果表明,Seed Diffusion Preview 在代码推理速度上取得了显著的提升,达到了 2146 tokens/s,相比同等规模的自回归模型提升了 5.4 倍。更重要的是,这种速度的提升并没有以牺牲生成质量为代价。在多个业界基准测试中,Seed Diffusion Preview 的性能与优秀的自回归模型相当,甚至在代码编辑等任务上实现了超越。
这一成果不仅证明了离散扩散模型在推理加速方面的潜力,也展示了其在复杂推理任务中的应用前景。这意味着,未来我们可以利用扩散模型来构建更加高效、更加智能的语言模型,从而更好地服务于各种自然语言处理应用。
Seed Diffusion Preview 的发布,是字节跳动 Seed 团队在语言模型领域的一次重要探索。它不仅为我们提供了一种新的语言模型架构,也为我们展示了扩散模型在自然语言处理领域的巨大潜力。随着技术的不断发展,我们有理由相信,扩散模型将在未来的语言模型领域发挥越来越重要的作用。
总而言之,Seed Diffusion Preview 通过其独特的技术创新,成功地将扩散模型应用于离散的自然语言处理领域,并在推理速度和生成质量上取得了显著的成果。这一突破性的进展,预示着下一代语言模型可能的发展方向,并为未来的研究提供了新的思路和灵感。随着技术的不断进步,我们期待看到扩散模型在自然语言处理领域取得更大的突破,为人工智能的发展注入新的活力。







