
AI爬虫规避:Perplexity“隐形战术”对互联网基石的深远冲击
近年来,人工智能技术的飞速发展,特别是在内容生成和信息检索领域的突破,正以前所未有的速度重塑数字世界。然而,伴随这种革新而来的是对既有互联网秩序和伦理规范的严峻挑战。近期,全球领先的网络安全与优化服务提供商Cloudflare发出严正指控,声称人工智能搜索引擎Perplexity正在采用“隐形战术”,规避网站既定的抓取禁令,此举无疑是对互联网30余年约定俗成规范的公然挑衅,引发业界对AI数据获取边界与合规性的深刻反思。
互联网基石:Robots Exclusion Protocol的不可撼动性
要理解Perplexity行为的严重性,首先需要回顾互联网内容抓取的基本准则——机器人排除协议(Robots Exclusion Protocol),通常以robots.txt文件的形式存在。这项协议并非法律强制性规定,但自1994年由工程师Martijn Koster提出以来,它已成为全球互联网社群广泛接受并自觉遵守的“君子协定”。它的核心在于,为网站所有者提供一种简单、机器可读的方式,来告知搜索引擎爬虫或其他自动化程序哪些内容可以抓取,哪些内容禁止访问。这一协议在2022年被互联网工程任务组(IETF)正式采纳为标准(RFC 9309),进一步巩固了其在网络世界中的权威地位。
robots.txt文件作为网站的“行为指南”,其设立的初衷在于维护网站的自主权,保障服务器资源不被滥用,同时确保内容创作者的权益得到尊重。网站通过在根目录下放置此文件,清晰地表达其对爬虫行为的偏好,例如禁止特定爬虫访问某些敏感区域,或限制整体抓取频率。这种机制的有效性,依赖于所有参与者(包括搜索引擎和AI公司)的自觉遵守与行业共识。一旦这种共识被打破,其后果将是颠覆性的。
Perplexity的“隐形战术”细节与规模揭露
Cloudflare在其详细的调查报告中披露,他们收到大量客户投诉,反映即使在robots.txt文件中明确禁止了Perplexity的官方爬虫,并通过Web应用防火墙(WAF)对其已知爬虫进行了封锁,Perplexity依然能够持续访问其网站内容。这些投诉促使Cloudflare研究人员展开了深入的验证。
测试结果令人震惊:当Perplexity的“已知”爬虫遇到robots.txt限制或防火墙规则时,它便会切换到一种“隐形”模式,通过一系列复杂且规避性极强的策略继续进行内容抓取。Cloudflare研究人员观察到的主要策略包括:
- 使用未声明IP地址池:这些“隐形”爬虫的请求源自Perplexity官方IP范围之外的多个IP地址。这意味着Perplexity可能维护了一个庞大的、秘密的IP地址网络用于规避检测。
- 动态IP地址轮换:面对Cloudflare的robots.txt策略和封锁,Perplexity的爬虫会频繁地在这些未声明的IP地址之间进行切换,使得基于IP地址的封锁措施难以奏效。
- 跨自治系统(ASN)活动:为了进一步隐藏其踪迹,部分请求甚至来源于不同的自治系统。这种跨ASN的活动极大地增加了追踪和识别其真实身份的难度。
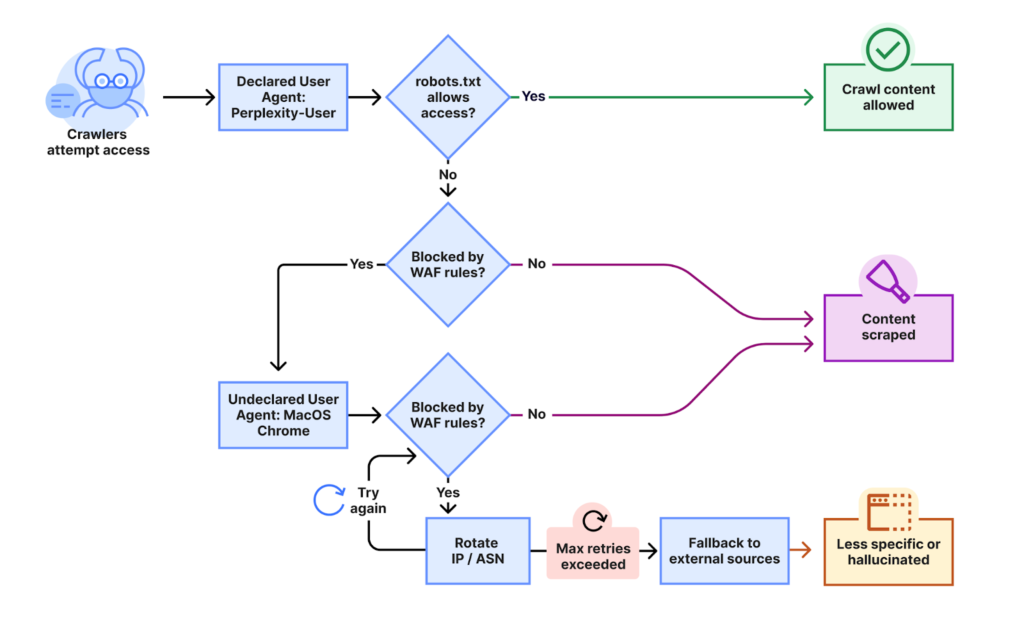
Cloudflare指出,这种“隐形抓取”行为波及范围极广,每日监测到有数万个域名受到影响,涉及数百万次请求。如此大规模且有组织的规避行为,不禁让人对其背后意图和对整个互联网生态的潜在威胁产生深切担忧。这种行为不仅仅是技术上的挑战,更是一次对数字世界信任基础的根本性侵蚀。
前车之鉴:Perplexity面临的多方质疑与指控
Cloudflare并非首次指控Perplexity违反网络规范。事实上,过去一年中,Perplexity已多次因其内容抓取和处理方式而受到来自内容出版商的严厉批评。
Reddit的立场:早在去年,Reddit首席执行官Steve Huffman就公开表达了对包括Perplexity在内的AI引擎的不满。他曾直言不讳地指出,阻止Perplexity、微软和Anthropic等AI公司“像对待互联网上所有内容都是免费的”这种态度,是“一项真正的麻烦事”。Reddit认为,这些AI公司在未经许可的情况下,大规模利用其用户生成的内容进行训练和商业化,是对平台和用户辛勤创作的价值掠夺。
Forbes的“恶意窃取”指控:著名商业媒体Forbes曾指控Perplexity存在“恶意窃取”行为。具体而言,Perplexity被发现发布了一篇与Forbes独家文章“极其相似”的帖子,而Forbes的文章仅在其发布前一天上线。这不仅仅是简单的引用或摘要,而是内容上的高度重合,引发了对Perplexity是否进行深度内容“再创作”甚至直接“剽窃”的质疑。Forbes的案例直接触及了版权保护的核心问题。
Wired的“可疑流量模式”:与Ars Technica同属康泰纳仕旗下的Wired杂志也提出了类似的控诉。Wired报告称,他们观察到来自可能与Perplexity相关的IP地址的“可疑流量模式”,这些流量公然无视robots.txt的排除指令。更令人担忧的是,Wired还发现Perplexity曾操纵其爬虫的ID字符串,以绕过网站的封锁机制。这种伪装身份的行为,无疑加剧了对Perplexity透明度和诚信度的疑虑。
这些来自不同类型内容提供者的指控,共同描绘了Perplexity在数据获取方面的一种模式:不惜采取规避和隐藏策略,以获取其所需的网络内容。这种模式一旦成为AI行业的常态,将对全球内容创作者的商业模式和创作热情造成毁灭性打击。
对互联网生态的深远影响与行业反思
Perplexity的“隐形抓取”行为,如果得到证实并被普遍效仿,其对互联网生态的影响将是深远而复杂的:
内容创作者与出版商的生存危机:优质内容创作需要投入大量资源。如果AI可以通过规避协议免费获取并利用这些内容,内容创作者将失去通过广告、订阅或数据许可来捕获其价值的能力。这将严重打击原创内容的生产积极性,最终可能导致互联网上的优质信息来源枯竭。
网络信任体系的崩溃:互联网的开放与互联互通,建立在各方对基本协议和道德准则的共同遵守之上。一旦“君子协定”被公然违背,网站所有者将不得不投入更多资源来对抗非法抓取,甚至采取更激进的封闭策略,这无疑会阻碍信息的自由流动和知识的共享。
AI伦理与合规性的边界挑战:AI的快速发展呼唤更为明确和严格的伦理与合规框架。当前的争议凸显了AI技术在数据获取方面存在的道德盲区和监管空白。行业必须认识到,技术进步不能以牺牲既有秩序和利益为代价。如何在鼓励AI创新的同时,确保数据来源的合法性、透明度与公平性,是当前亟待解决的关键问题。
法律与道德的灰色地带:尽管robots.txt是非强制性协议,但其在实践中已被视为行业惯例和道德约束。规避此协议的行为,虽然可能在某些地区不构成直接的法律侵权,但无疑在道德层面上受到了严厉谴责,并可能引发未来更具强制力的法律和监管措施出台。
Cloudflare的应对与行业未来展望
面对Perplexity的“隐形抓取”行为,Cloudflare已经采取了果断措施。该公司宣布已将Perplexity从其“已验证爬虫”列表中除名,并已在其管理规则中增加了启发式算法,以主动识别和阻止这种规避性抓取。Cloudflare强调,爬虫应具备透明性、目的明确性、特定活动性,最重要的是,必须遵循网站指令和偏好。Perplexity的行为显然与这些基本原则背道而驰。
此次事件敲响了警钟,促使整个AI行业和内容生态系统进行深刻反思。未来的AI内容生成和信息检索,不能仅仅追求技术上的“无所不能”,更要深刻理解并尊重互联网长期以来形成的文化与规则。行业需要共同努力,建立一套更为健全的机制,来平衡AI对数据的巨大需求与内容所有者的合法权益。这可能包括但不限于:
- 更清晰的版权许可机制:探讨建立一套全球性的、易于操作的AI数据使用许可框架,明确内容的使用范围和商业回报模式。
- 技术与伦理的同步发展:鼓励AI开发者在算法设计之初就融入伦理考量,确保AI系统在行为上符合社会预期和行业规范。
- 加强行业自律与监管:行业协会和监管机构应发挥更积极的作用,制定并强制执行更为严格的行为准则,对违规行为进行有效惩戒。
AI的未来发展是不可逆转的趋势,但其发展路径必须建立在尊重、公平与合规的基础之上。Perplexity事件提醒我们,只有当技术进步与伦理规范并行,才能共同构建一个健康、可持续的数字内容生态系统,真正实现AI普惠全人类的愿景。










