
1. AI时代的用户数据:隐私边界的模糊化
随着人工智能技术的飞速发展,大型语言模型(LLMs)如ChatGPT已深度融入个人与商业应用,其便捷性与强大功能令人惊叹。然而,伴随这种深度融合的,是对用户数据隐私保护的日益严峻挑战。近期,OpenAI的ChatGPT平台便遭遇了一场严重的隐私风波,数千乃至更多用户的私密对话记录,竟然通过Google搜索引擎被公开索引。这起事件不仅让用户感到震惊与不安,更深刻地揭示了在AI应用高速迭代背景下,企业在用户数据处理上的潜在漏洞与伦理困境。
事件的核心在于ChatGPT曾推出的一项“共享”功能,其设计存在严重缺陷。尽管OpenAI声称用户需主动选择“使此对话可被发现”方能被索引,但实际的用户界面(UI)设计,特别是文本格式上的提示,却极易误导用户。许多用户在无意间点击“分享”后,可能并未留意到下方以更小、更浅色字体标注的“该对话可能出现在搜索引擎结果中”的警示。这种模糊不清的引导,使得大量原本意图仅在私密圈层分享或仅供个人后续查阅的敏感对话,包括个人健康状况、情感纠葛、甚至毒品使用和创伤经历等高度私密内容,被无意间推向了公共视野。此类“暗模式”或误导性设计,在数字化产品中屡见不鲜,但当涉及用户最深层隐私时,其后果无疑是灾难性的。

2. 误导性设计:用户知情权与同意的挑战
用户知情同意是现代数据隐私法律和伦理框架的基石。然而,OpenAI此次事件中暴露出的问题,恰恰是对这一原则的践踏。表面上看,系统提供了“同意”选项,但其呈现方式未能确保用户在充分理解后果的情况下做出决策。这引出了一个关键问题:技术公司在推出新功能时,是否真正将用户隐私置于首位?抑或是在追求功能创新与用户增长的过程中,不自觉地模糊了隐私保护的边界?
牛津大学AI伦理学家Carissa Veliz对此事件的评价一针见血,她对Google能够索引这些“极其敏感的对话”感到“震惊”,并直言不讳地指出,科技公司常将“普通大众作为小白鼠”,通过推出新产品吸引海量用户,然后静观其变,观察其侵入性设计可能引发的后果。这种“先试后改”的策略,虽然在快速迭代的互联网行业司空见惯,但在涉及用户核心隐私和数据安全时,其风险与代价是巨大的。它不仅损害了用户信任,更可能带来严重的法律和声誉风险。
事实上,此类事件并非孤例。在AI领域,数据的收集、处理与使用往往伴随着复杂的伦理和隐私难题。从训练数据的偏见问题,到用户交互数据的安全存储,再到模型输出内容的版权归属,每一个环节都可能成为隐私泄露或滥用的潜在风险点。本事件再次敲响警钟,提醒所有AI开发者,在追求技术创新和产品功能完善的同时,必须将用户数据安全和隐私保护放在同等重要的位置,并确保设计流程中的每一个环节都充分考虑伦理规范。
3. 技术响应与信任重建:一场艰难的战役
面对舆论压力和用户反弹,OpenAI迅速采取了行动。其首席信息安全官Dane Stuckey在X(前Twitter)上证实,该公司已将该功能移除,并承诺将通过技术手段从相关搜索引擎中删除已被索引的内容。Stuckey将此功能描述为一项“短命的实验”,旨在“帮助人们发现有用的对话”。然而,这种“实验性”的解释,并不能完全平息用户的担忧。一项可能泄露海量敏感数据的“实验”,其背后的风险评估和隐私影响评估机制是否健全?这需要OpenAI给出更深层次的解释。
值得注意的是,Google在此事件中声明,搜索引擎不控制网页的公开性,页面的发布者拥有完全的索引控制权。这进一步明确了OpenAI作为数据发布方,对此次泄露负有主要责任。虽然Google提供了工具帮助网站所有者阻止页面被索引,但这并不能保证内容立即从所有搜索引擎中消失,且对于已经通过其他方式扩散的隐私数据,追踪和彻底删除无疑是极其困难的。因此,即使OpenAI尽力补救,也无法完全消除已造成的负面影响,部分用户的私密信息可能已在网络上留下了难以磨灭的痕迹。
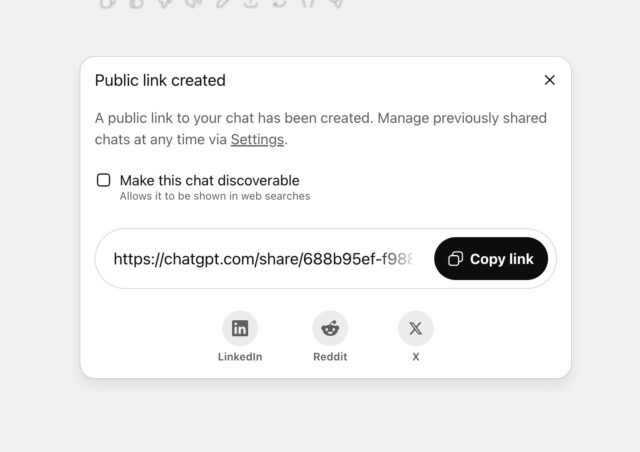
4. 法律合规与企业责任:从被动应对到主动预防
此次事件也凸显了AI企业在法律合规方面的挑战。此前,OpenAI曾因一项法院指令而与《纽约时报》对簿公堂,该指令要求其无限期保存所有被删除的ChatGPT对话记录。OpenAI当时认为这将是“隐私噩梦”,并试图抵制。讽刺的是,在未能阻止法院强制保留日志后,OpenAI自身的产品设计却率先制造了一场可能导致用户私密数据被公开索引的“隐私噩梦”。这种前后矛盾的态度,让外界对其在隐私保护方面的承诺产生了质疑。
从更宏观的层面来看,这起事件对全球数据保护立法,如欧盟的《通用数据保护条例》(GDPR)和美国的《加州消费者隐私法案》(CCPA)等,提出了新的拷问。这些法规的核心在于保障用户对个人数据的控制权,要求企业在数据处理前获得明确同意,并提供数据访问、删除等权利。OpenAI的“共享”功能显然未能达到这些标准所要求的透明度和用户控制水平。未来,AI企业在产品设计初期就应将“隐私设计”(Privacy by Design)和“默认隐私”(Privacy by Default)原则融入其中,而非在问题发生后才被动应对。
这要求企业建立健全的数据治理框架,包括:
- 严格的隐私影响评估(PIA):在推出任何可能涉及用户数据的新功能前,进行全面的隐私风险评估。
- 透明的用户界面设计:确保所有隐私相关的选项都清晰明了,避免使用模糊或误导性措辞。
- 用户控制权的赋予:允许用户轻松管理和删除其数据,并明确告知数据保留策略。
- 定期的安全审计与渗透测试:主动发现和修复潜在的安全漏洞。
- 应急响应计划:制定详细的危机管理预案,以应对可能发生的数据泄露事件。
5. 重塑用户信任:AI发展的长远基石
人工智能的未来发展,离不开用户的信任。此次ChatGPT隐私泄露事件,无疑是对这种信任的严重冲击。尽管OpenAI表示“安全和隐私对我们至关重要,我们将继续努力在产品和功能中最大限度地体现这一点”,但空洞的承诺远不如实际行动来得更有说服力。
展望未来,AI行业必须从此次事件中吸取深刻教训。这不仅仅是一次技术故障或设计失误,更是对AI伦理和企业社会责任的严峻考验。建立一个健康、可持续的AI生态系统,要求开发者不仅专注于技术突破,更要将用户隐私、数据安全和伦理考量置于产品生命周期的核心。只有当用户能够放心地与AI系统交互,确信他们的个人信息得到妥善保护时,AI才能真正发挥其潜力,成为造福人类的工具,而非带来潜在风险的“潘多拉魔盒”。这需要行业内的共同努力,包括政府的有效监管、企业的自律以及用户的警惕与参与,共同构建一个更加安全、可信赖的数字未来。










