阿里通义千问Qwen-Image:探索文生图领域的颠覆性突破
近年来,人工智能在图像生成领域取得了飞速发展,其中文生图模型更是成为备受瞩目的焦点。在这一浪潮中,阿里通义千问团队推出的Qwen-Image模型无疑是其中的佼佼者。作为通义千问系列中的首个图像生成基础模型,Qwen-Image凭借其20B参数的MMDiT架构,在复杂文本渲染和精确图像编辑方面展现出前所未有的强大能力,尤其在高保真中英文文本输出方面树立了新的行业标杆。它不仅在通用图像生成和编辑任务中表现卓越,更通过其开源策略,为整个AI视觉内容生态注入了新的活力,预示着一个更加智能、高效的创意时代正加速到来。
核心技术能力解析:重塑图像生成边界
Qwen-Image的设计旨在解决当前文生图模型在细节处理和编辑精度上的痛点,其核心功能涵盖了多方面,旨在为用户提供全面且强大的视觉内容创作工具:
高保真复杂文本渲染的突破 传统文生图模型在生成包含文字的图像时,往往面临文字模糊、排版错乱或字体失真等挑战。Qwen-Image则在此方面实现了显著突破,它能够支持多行甚至段落级文本的精确生成,即便对于细小文字也能清晰呈现。无论中文还是英文,模型都能实现高保真的输出效果。这种能力对于需要精确图文结合的应用场景至关重要,例如海报设计、产品说明图或含有文字信息的艺术创作,极大地提升了图文一体化的生成质量,解决了长久以来困扰AI生成文本图像的“伪字”问题。
精细化图像编辑的艺术化呈现 除了从零生成图像,Qwen-Image还具备强大的图像编辑能力。这包括:
- 风格迁移与创意变换:用户可以轻松将一种图像的风格应用于另一图像,或探索多样化的艺术风格,为艺术创作和设计提供无限可能。
- 对象增删改的精准控制:模型能够准确识别和操作图像中的特定对象,实现无缝添加、删除或修改,而不会破坏整体图像的自然感。
- 细节增强与局部优化:针对图像中的微小细节进行增强或调整,提升视觉质量。
- 文字内容与排版编辑:模型支持对图像中已存在的文字进行修改,甚至调整其字体、大小和排版,这在广告设计和品牌推广中尤为实用。
- 人物姿态与表情调整:在人像生成和编辑方面,Qwen-Image能够对人物的姿态和表情进行细致调整,使得生成的人物形象更加生动自然,满足多样化的创作需求。 这些功能共同确保了模型在保持图像整体自然和真实感的同时,能够实现高度精细化的编辑操作,为专业设计师和普通用户提供了极大的创作自由度。
通用图像生成的多样性与创新 Qwen-Image在通用图像生成方面同样表现出色,能够根据用户输入的文本描述,生成涵盖各种主题、场景和风格的创意图像。无论是写实的风景、抽象的艺术画作,还是概念性的插图,模型都能灵活驾驭,为创意产业提供了一个高效、便捷的视觉内容生产平台。
深层架构剖析:创新驱动的工程实践
Qwen-Image之所以能实现卓越性能,得益于其精妙而稳健的技术架构和训练策略:
模型架构:多模态融合的智慧结晶
- 多模态大语言模型(MLLM):Qwen-Image以先进的MLLM作为其文本特征提取模块。MLLM能够深度理解文本语义,捕捉细微的上下文信息,并将其转化为图像生成所需的精确特征向量。这种深度语义理解能力是实现高保真文本渲染和精确图像编辑的基础。
- 变分自编码器(VAE):VAE在模型中扮演着关键角色,负责将输入图像高效编码为紧凑的潜在表示,并在推理阶段进行解码,从而实现图像的高效处理和生成。它有效地在像素空间和潜在空间之间搭建了桥梁,降低了计算复杂度。
- 多模态扩散变换器(MMDiT):作为模型的核心生成引擎,MMDiT基于扩散模型原理,通过逐步去除噪声的方式生成图像。与传统的U-Net结构不同,DiT(Diffusion Transformer)采用Transformer架构,能够更好地捕捉长距离依赖关系和全局信息。结合文本特征进行引导,MMDiT确保了生成的图像与文本描述高度一致,并能产生高质量、高分辨率的视觉内容。
数据策源与质量控制:基石的铸造 Qwen-Image的成功离不开其所依赖的大规模、高质量数据集。团队通过广泛的数据收集和精细标注,构建了一个涵盖自然场景、艺术设计、人物肖像以及合成数据的丰富数据集。此外,模型采用了多阶段的数据过滤流程,严格去除低质量或不符合要求的数据,确保了训练数据的高质量和多样性,有效避免了模型学习到有害或偏见内容,也保证了生成内容的可靠性与真实性。
训练策略:效率与稳定性的平衡之道 在训练过程中,Qwen-Image采用了多项创新策略:
- 流匹配(Flow Matching)作为预训练目标:相较于传统的扩散模型训练目标,流匹配能通过普通微分方程(ODE)实现更稳定的训练动态,同时保持与最大似然目标的等价性。这不仅加速了训练收敛,也提升了模型在生成过程中的稳定性。
- 多任务训练范式:模型结合了文本到图像(T2I)、图像到图像(I2I)和文本图像到图像(TI2I)的多任务训练范式。这意味着模型在一个共享的潜在空间中同时学习多种任务,极大地增强了其通用性和泛化能力,使其既能从文本生成图像,也能基于现有图像进行编辑和变换。
性能卓越:行业标杆的树立
Qwen-Image在多个维度上展现出卓越的性能,证明了其在当前文生图领域的领先地位:
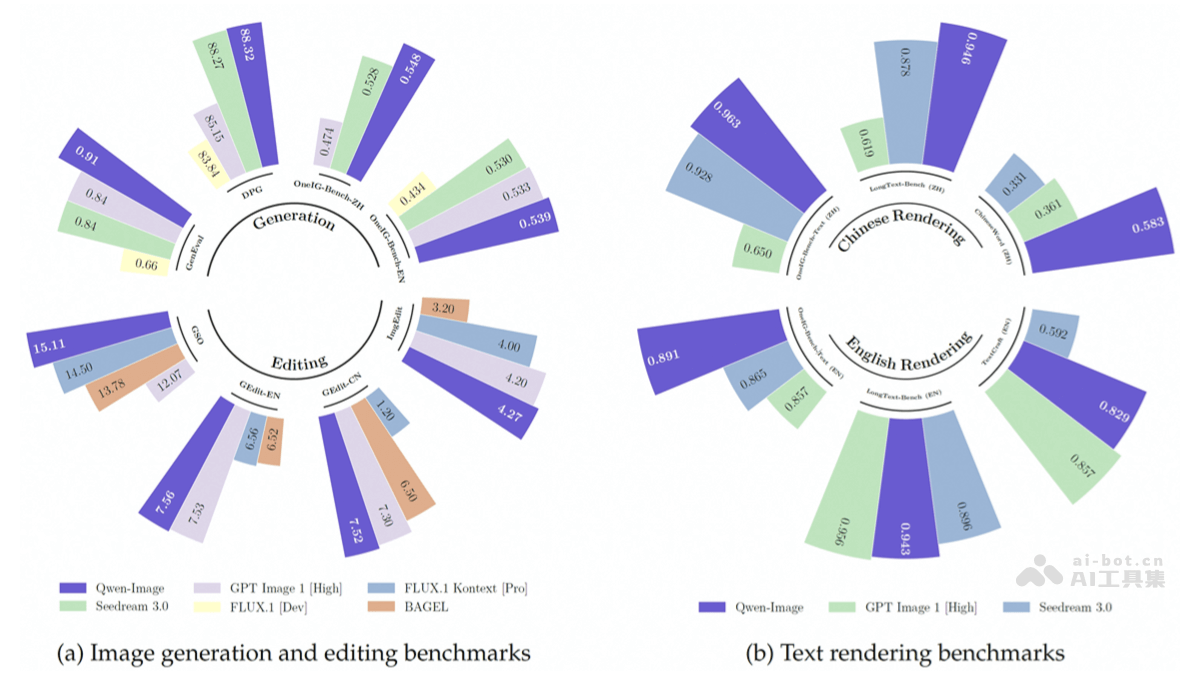
多基准测试的压倒性优势 在多个公开基准测试中,Qwen-Image取得了惊人的12项最佳表现(SOTA),这充分证明了其在图像生成和编辑领域的强大竞争力。它在通用图像生成测试(如GenEval、DPG和OneIG-Bench)中,性能超越了Flux.1、BAGEL等领先的开源模型。更值得一提的是,Qwen-Image在多个关键指标上甚至超越了字节跳动的SeedDream 3.0和OpenAI的GPT Image 1(High)等闭源模型,这表明其在生成质量和编辑能力上均已达到行业顶尖水平,为开源社区树立了新的性能典范。
中文文本渲染的独特优势与深远影响 Qwen-Image在文本渲染能力方面表现尤为突出,特别是在中文文本渲染上实现了巨大飞跃。在LongText-Bench、ChineseWord和TextCraft等基准测试中,其表现大幅领先于现有的最先进模型,包括SeedDream 3.0和GPT Image 1(High)。这种在中文处理上的独特优势,源于模型在语言理解、字体生成和排版优化方面的深度技术积累。对于中文作为母语的用户和市场而言,这意味着AI工具能够更准确、更自然地处理中文内容,极大地拓展了中文AIGC的应用边界,使其在本地化内容创作方面具备无可比拟的优势。这意味着从中文标语、产品包装到教育材料,Qwen-Image都能提供精准且美观的文字呈现,极大提升了用户体验和内容质量。
广泛应用场景:赋能千行百业的无限潜力
Qwen-Image的强大功能使其在多个行业和领域拥有广阔的应用前景,正逐步成为推动数字内容创作和产业升级的关键力量:
内容创作与营销效率革新 对于内容创作者而言,Qwen-Image能够根据简单的文本描述快速生成高质量的图像、海报、社交媒体配图、广告创意和演示文稿(PPT)页面。这极大地提升了创意设计和营销材料的制作效率与视觉效果,帮助企业和个人在激烈的市场竞争中脱颖而出。它能迅速响应市场需求,生成符合品牌调性的视觉内容,加速营销活动的迭代周期。
艺术与设计领域的新维度 模型强大的风格迁移和创意绘画能力为艺术家和设计师提供了丰富的灵感来源和全新的创作工具。艺术家可以尝试不同的艺术流派,探索前所未有的视觉风格,甚至将AI生成作为辅助手段,加速艺术作品的构思和实现过程。这不仅能降低创作门槛,也为专业人士提供了更多实验和创新的空间。
教育与学习的互动升级 在教育领域,Qwen-Image能够辅助教师快速生成生动、直观的教学材料,如科普插图、历史场景复原图或概念图解。通过生成与语言学习相关的图像,它还能帮助学习者更好地理解和记忆抽象概念或外语词汇,使学习过程更具互动性和吸引力,提升教学效果和学习效率。
商业与品牌的视觉叙事 商业领域可以利用Qwen-Image快速生成吸引人的广告图像、品牌推广素材和产品原型图。其高保真输出确保了品牌视觉形象的一致性和专业性,有效提升广告的吸引力和品牌的市场影响力。从电商产品图到企业宣传画册,Qwen-Image都能提供定制化的视觉解决方案。
娱乐与游戏的沉浸式体验 在娱乐和游戏产业,Qwen-Image可以高效生成游戏中的角色、场景、道具图像,以及影视制作中的特效和概念图。这能够显著加速娱乐内容的创作周期,降低美术成本,同时为玩家和观众带来更加丰富、沉浸式的视觉体验。无论是独立开发者还是大型游戏工作室,都能从中受益。
未来图景与挑战:AI生成内容的进化
Qwen-Image的开源,不仅仅是技术上的一个里程碑,更是对AI社区的一次重大贡献。它降低了高性能文生图技术的门槛,使得更多开发者和研究者能够在此基础上进行创新,加速了整个生态系统的发展。然而,随着AI生成能力的不断提升,我们也需审慎思考其带来的挑战,例如内容真实性、版权归属以及潜在的滥用风险。未来的发展将不仅聚焦于模型性能的进一步突破,更在于如何构建一个负责任、可持续的AI生成内容生态。这包括开发更强大的内容鉴别工具,制定更明确的伦理规范,以及探索创作者与AI之间更和谐的协作模式。Qwen-Image的出现,无疑为我们打开了一扇窗,让我们得以窥见一个由AI赋能的创意未来,一个内容生产效率和创造力都将达到前所未有高度的全新纪元。