
AI内容抓取伦理边界:Perplexity隐秘爬虫行为深度解析与网络规范挑战
近年来,人工智能(AI)在内容创作与信息整合领域的快速崛起,极大地改变了我们获取和处理信息的方式。然而,随着AI模型对海量数据需求的增长,其数据获取行为与既有的互联网规范之间逐渐显现出张力。近期,AI搜索引擎Perplexity被网络安全和优化服务商Cloudflare指控采用“隐秘战术”规避网站的抓取指令,这一事件不仅将AI伦理推向风口浪尖,更引发了对数字时代内容版权、数据所有权以及网络治理模式的深层次思考。这不仅是技术层面的较量,更是对长达三十余年互联网“君子协定”——Robots Exclusion Protocol——的严峻考验。
Perplexity的“隐形战术”:Cloudflare的揭露与警示
根据Cloudflare周一发布的博客文章,其研究人员接到多位客户投诉,称尽管已通过robots.txt文件设置或Web应用防火墙(WAF)规则明确阻止了Perplexity的已知爬虫,但该AI服务仍能持续访问其网站内容。为验证这些指控,Cloudflare展开了内部测试,结果令人震惊:当Perplexity的声明爬虫遭遇阻拦时,其系统会迅速切换至一种“隐形爬虫”模式,采取一系列规避策略来掩盖其活动。
Cloudflare的研究人员详细指出,这种未声明的爬虫使用了Perplexity官方IP范围之外的多个IP地址,并会根据网站严格的robots.txt策略或Cloudflare的防火墙规则进行IP地址轮换。此外,他们还观察到请求来自不同的自治系统编号(ASN),以期进一步绕过网站的封锁。据称,这种规避行为横跨数万个域名,每日请求量高达数百万次,揭示出其操作规模之广及其对现有网络协议的漠视程度。
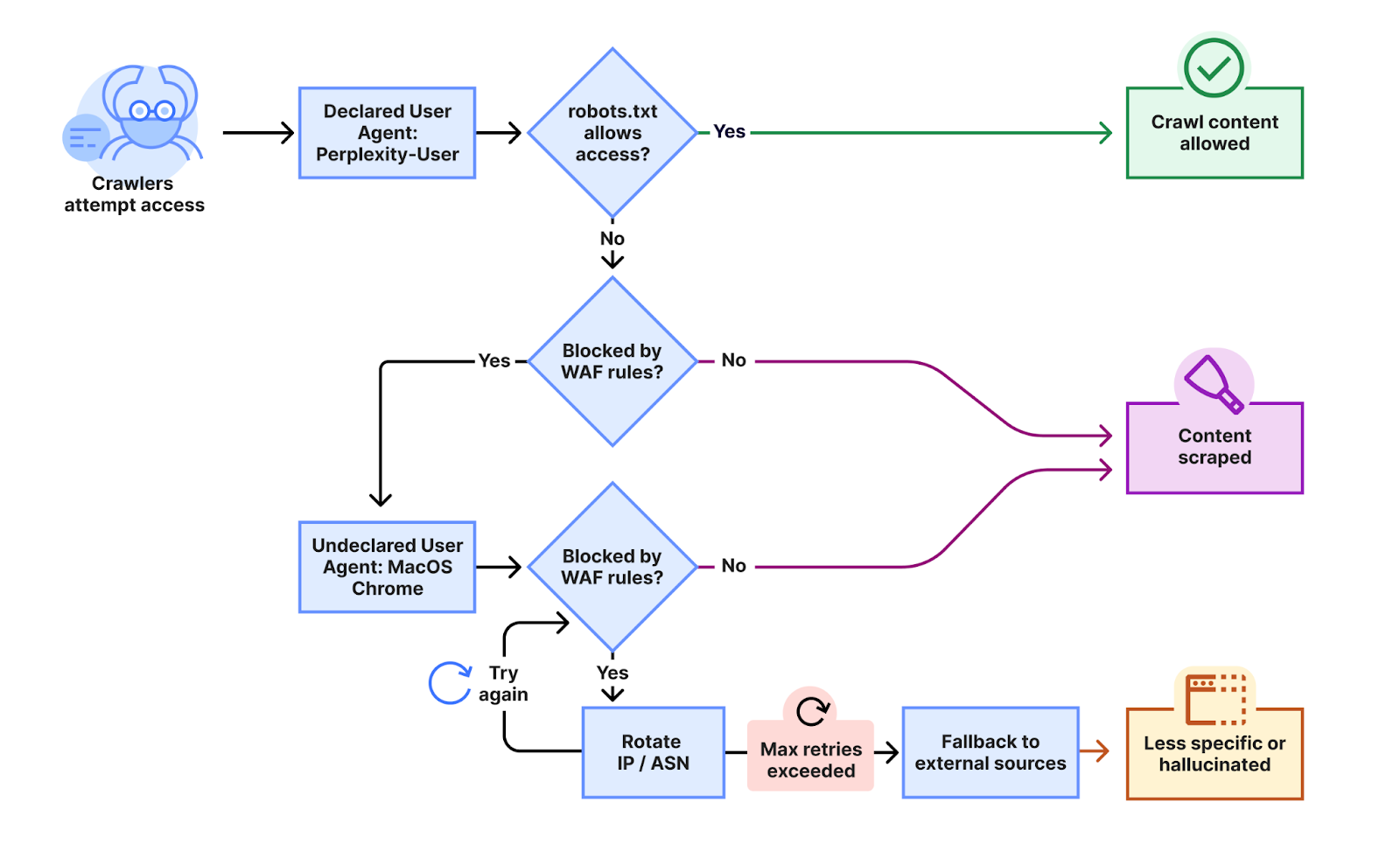
这种技术性的规避手段,无疑触及了互联网最基本的操作规范。它不仅挑战了内容提供者对其数字资产的控制权,也可能对整个网络生态的信任基础造成侵蚀。Perplexity的这一行为,无论是有意为之还是技术策略的“副作用”,都值得业界深入审视和反思,特别是当AI技术日益深入内容生成与分发的核心领域时。
网络爬虫协议的基石:Robots.txt的沿革与挑战
Cloudflare的指控之所以引发广泛关注,其核心原因在于Perplexity的行为被认为公然违反了互联网领域存在已久的“君子协定”——Robots Exclusion Protocol,即我们熟知的robots.txt文件。该协议诞生于1994年,由工程师Martijn Koster首次提出,旨在为网站提供一种机器可读的格式,用以告知网络爬虫哪些区域被允许访问,哪些区域被禁止抓取。简单而言,网站管理员只需在主页根目录下放置一个robots.txt文件,即可设定爬虫的访问权限。这一标准自提出以来便被广泛遵循和认可,成为互联网内容索引和管理的基础性规范。
2022年,Robots Exclusion Protocol更是获得了互联网工程任务组(IETF)的正式认可,成为RFC 9309标准,进一步巩固了其作为互联网基石的地位。这意味着,robots.txt不再仅仅是一个约定俗成的惯例,而是一个经过标准化、具有更强约束力的技术规范。Perplexity通过隐秘爬虫规避这一明确指令的行为,无疑是对这一成熟且被普遍接受的互联网规范的公然挑战。它不仅可能侵犯网站的自主权,也可能为未来的AI数据获取实践埋下隐患,使得内容创作者面临前所未有的信息控制困境。
并非孤例:Perplexity面临的多方指控
Perplexity并非首次被指责在数据获取方面存在争议。去年,Reddit首席执行官Steve Huffman就曾公开表示,阻止Perplexity以及微软和Anthropic等其他AI引擎抓取其内容是“一件非常令人头痛的事情”。Huffman明确指出:“我们发现微软、Anthropic和Perplexity的行为,仿佛互联网上的所有内容都可供他们免费使用,这正是他们的真实立场。”这番言论揭示了内容平台与AI公司之间围绕数据使用权的紧张关系。
更甚者,Perplexity还面临多家出版商的剽窃指控。例如,《福布斯》曾指责Perplexity在发布其文章一天后,生成了一篇与《福布斯》独家报道“极其相似”的内容,称其为“愤世嫉俗的盗窃”。《连线》(Wired)也提出了类似的主张,指出其网站出现了可疑的IP流量模式,这些流量很可能与Perplexity相关,且似乎无视了robots.txt的排除指令。此外,有报道称Perplexity曾操纵其爬虫的ID字符串,以绕过网站的封锁机制。这些独立的指控与Cloudflare的发现相互印证,共同描绘出Perplexity在数据获取策略上,倾向于采取侵略性甚至不透明手段的画像。这些行为不仅损害了原创内容的价值,也严重冲击了数字内容生态的公平与信任。
Cloudflare的反制措施与行业影响
面对Perplexity的规避行为,Cloudflare已采取具体行动以保护其客户。该公司已将Perplexity从其“已验证机器人”列表中移除,并增加了启发式规则至其管理规则集,旨在有效阻止此类隐秘爬虫的活动。这一举措具有深远的行业意义。
首先,Cloudflare的反应明确传递了一个信号:网络服务提供商将不再容忍AI公司规避既定网络规范的行为。透明度、目的明确性、特定活动执行以及最重要的是遵循网站指令和偏好,是衡量一个网络爬虫是否“负责任”的关键标准。Perplexity的观察行为被Cloudflare判定为不符合这些标准,从而失去了其“已验证”的地位。这为其他内容交付服务商和网站管理者提供了处理类似情况的参考范例,预示着未来可能会有更多平台采取类似的强硬立场。
其次,此事件也将促使AI开发者重新审视其数据获取策略。在数据是AI模型生命线的当下,如何合法、合规且负责任地获取训练数据,将成为AI伦理治理的核心议题。Cloudflare的行动,无疑是对整个AI行业发出的一次严厉警告:技术的进步不能以牺牲网络基本秩序和内容创作者的权益为代价。这将可能推动AI公司在数据采集方面更加注重透明度与合作,探索如付费授权、数据共享协议等更可持续的模式。
AI数据伦理的深层思考:版权、公平与未来
Perplexity事件不仅仅是单一公司行为的争议,它触及了AI时代数据伦理的深层核心:即人工智能模型如何合法、合规且公平地获取和使用海量数据。当前,AI模型的训练往往依赖于对互联网内容的广泛抓取,这使得“合理使用”(Fair Use)原则在数字版权领域的适用性变得复杂。在许多情况下,AI公司可能声称其抓取行为属于数据分析或模型训练,符合合理使用的范畴。然而,当AI输出的内容与原始内容高度相似,甚至被指控构成剽窃时,其边界便变得模糊不清。

内容创作者和出版商的权益保护,是AI时代面临的重大挑战。如果AI可以通过规避机制无限制地使用其内容,那么原创内容的价值将面临贬值风险,数字内容经济模式的可持续性也将受到威胁。此外,数据所有权的问题也亟待解决:谁拥有AI训练过程中抓取到的数据?数据抓取行为应如何获得授权和补偿?这些问题不仅需要技术层面的解决方案,更需要法律、政策和行业自律等多方协同努力。
建立AI与内容生态和谐共存的机制,是当前业界必须面对的紧迫任务。这要求AI公司在追求技术创新的同时,更加重视社会责任和伦理规范,确保数据获取的透明性、公平性与可追溯性。同时,内容创作者也应积极探索新的数字版权保护技术和商业模式,以适应AI时代的新挑战。
展望:AI时代的网络治理与数据共享新范式
Perplexity与Cloudflare之间的争议,是AI技术发展过程中一个重要的里程碑事件。它清晰地揭示了在快速演进的AI时代,网络治理面临的复杂性。未来,我们可能需要构建一套全新的数据共享范式,以平衡AI对数据的需求与内容创作者的合法权益。
这种新范式可能包括:
- 更透明的数据获取协议: AI公司应公开其爬虫行为的详细信息,包括爬虫类型、目的、频率以及其遵循的协议。透明度是建立信任的基础。
- 标准化的内容授权机制: 发展易于实施和扩展的数字内容授权协议,允许内容所有者有选择性地向AI模型开放数据,并从中获得合理补偿。
- 技术与法律的协同: 法律法规应跟上技术发展步伐,明确AI数据使用的版权边界和责任归属。同时,技术解决方案如基于区块链的版权管理、数字水印等,也可在保护内容方面发挥作用。
- 行业自律与最佳实践: 推动AI行业形成一套共识性的伦理准则和最佳实践,引导企业负责任地开发和部署AI技术。
总而言之,AI技术的发展不应以牺牲网络基本秩序和内容创作者利益为代价。只有在尊重既有规范、秉持伦理原则的基础上,AI才能真正实现其赋能人类社会、推动数字经济健康发展的巨大潜力。Perplexity事件是一面镜子,映照出AI时代网络治理的紧迫性与复杂性,也为我们指明了未来构建一个更加公正、透明、可持续的数字生态系统的方向。










