
人工智能隐私边界的冲击与再思考
近期,人工智能领域巨头OpenAI遭遇了一场严重的信任危机。其旗下广受欢迎的生成式AI工具ChatGPT被曝出存在重大隐私漏洞,数以千计的用户私密对话,原本应仅限于用户与AI之间,却意外地出现在谷歌等主流搜索引擎的公开结果中。
这一事件引发了全球范围内的广泛关注与强烈质疑,令无数用户感到震惊和不安。它不仅深刻揭示了当前AI技术飞速发展背后所潜藏的深层次隐私风险与伦理挑战,更迫使业界重新审视人工智能产品在设计、部署及运营过程中,应如何严格界定用户数据的使用边界,以及如何在技术创新与个人隐私保护之间寻求精妙的平衡。
此次泄露并非源于外部攻击,而是出人意料地源于产品内部一个被忽视的设计缺陷——一个“可发现性”选项的误导性呈现。这使得许多用户在无意中“同意”将其与AI的私密对话公之于众,其内容涉及个人健康、心理状况、情感关系乃至敏感的社会议题。这些高度个性化且具有潜在识别性的信息一旦暴露,无疑将对用户的数字安全和个人声誉构成严重威胁。

隐私泄露的机制解析与深层原因
“可发现性”功能的双刃剑
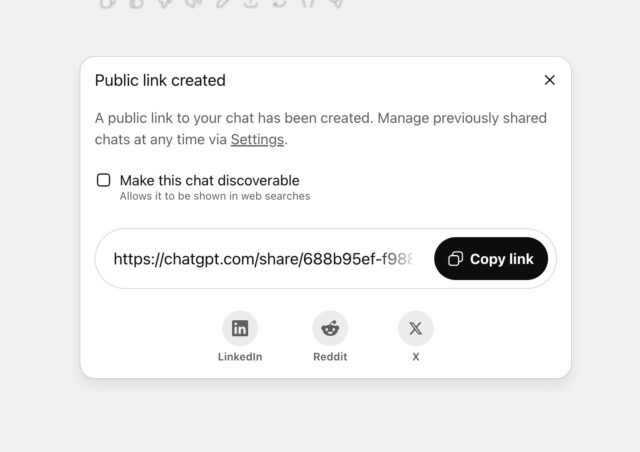
根据最初的调查报告,此次大规模隐私泄露的根源,指向了ChatGPT中一个名为“共享”(Share)的功能。当用户选择分享对话时,界面会弹出一个勾选框,标注“使此聊天可发现”(Make this chat discoverable),下方则以较小、浅色的字体提示“该聊天可能会出现在搜索引擎结果中”。正是这种含糊不清、易于忽略的表述方式,成为了泄露的关键症结。
用户可能仅仅是为了生成一个方便后续访问的链接,或者希望通过WhatsApp等平台与少数人分享,却在不经意间勾选了使其对话在公共搜索引擎上可被索引的选项。这种设计无疑在用户体验与隐私保护之间制造了巨大的矛盾。从产品设计的角度来看,可能OpenAI的初衷是希望通过公开可发现的对话来促进知识共享或提升模型透明度。
然而,其对用户隐私影响的评估显然不足,或者在界面指引上未能达到应有的清晰度与警示性。尤其考虑到AI对话中用户可能倾泻高度个人化甚至脆弱的信息,这种“默认共享”或“隐晦同意”的模式,是对用户信任的一种严重背离。
敏感信息与识别风险
泄露的对话内容之敏感性令人震惊。据报道,其中不乏用户关于药物使用、性生活、心理健康困扰,乃至个人创伤经历的详细描述。尽管OpenAI声明索引内容不包含用户身份信息,但《快公司》(Fast Company)的调查指出,这些对话中极度具体的个人细节,完全有可能在特定情境下导致用户的身份被反向推断和识别。
例如,如果某段对话详细描述了特定地理位置、职业背景或独有的家庭关系,即使没有姓名,也可能在社交网络或其他公开信息中找到匹配点,从而揭示用户的真实身份。这种匿名化的脆弱性在数据隐私领域是一个长期存在的挑战。传统的匿名化技术在面对高维度、高粒度的行为数据时往往力不从心。
用户在与AI互动时,往往会放下戒备,将AI视为一个私密的倾听者,从而无意中提供远超其预期的个人信息。当这种“数字信任”遭遇机制上的漏洞,其后果将是灾难性的。隐私泄露不仅可能导致个人信息被滥用,更可能引发心理困扰和社会污名化,对受影响的用户造成难以估量的长期损害。
OpenAI的回应与行业反思
紧急补救与责任界定
面对舆论的巨大压力,OpenAI的首席信息安全官戴恩·斯塔基(Dane Stuckey)最初曾辩称该功能标签“足够清晰”,但随着事态发酵及内部评估,OpenAI最终承认该功能“引入了太多用户可能意外分享不打算分享内容的可能性”。公司迅速采取行动,将其定义为一次“短期的实验”,并已于上周五早上完成功能下线,同时加紧协调搜索引擎,移除相关已索引内容。
在此事件中,谷歌方面也作出了回应,澄清了其作为搜索引擎的角色。谷歌发言人表示,搜索引擎并不控制哪些页面被公开索引,而是由页面的发布者(即OpenAI)全权决定其内容是否可被搜索。这意味着,此次隐私泄露的责任,核心在于OpenAI对用户隐私设置的把控不当。
尽管谷歌提供了工具帮助网站所有者快速从搜索结果中移除页面,但其他搜索引擎的去索引速度可能不同,这使得完全清除泄露信息仍需时日,用户的数据暴露风险仍未完全解除。
“试验品”论与信任基石
牛津大学的AI伦理学家卡丽莎·韦利兹(Carissa Veliz)对此类事件表达了强烈不满,她直言“科技公司将普通民众当成小白鼠”。韦利兹指出,许多科技巨头在推出新AI产品时,往往采取一种“先上车后补票”的策略,即先吸引海量用户,再观察其激进设计选择可能引发的后果。这种“快速迭代,打破常规”的开发模式,在AI领域尤其危险。
它使得用户在不知情的情况下,成为未经充分伦理考量和风险测试的“实验品”,严重侵蚀了用户对技术服务提供商的信任基石。信任是AI技术普及和健康发展的核心驱动力。一旦用户对AI产品的隐私保护能力产生怀疑,不仅会阻碍其在敏感领域的应用,更可能引发广泛的抵制情绪,从而延缓整个AI产业的良性进步。
从个案看AI数据治理的深远挑战
与法庭指令的微妙关联
值得注意的是,此次事件并非OpenAI首次面临数据隐私的争议。在此之前,OpenAI曾极力反对一项法院命令,该命令要求其无限期保存所有被删除的ChatGPT聊天记录,理由是这将构成“隐私噩梦”。OpenAI首席执行官山姆·奥特曼(Sam Altman)曾公开表示,用户最私密的聊天记录可能被搜索是“一团糟”的情况。
然而,讽刺的是,在反对外部指令的同时,公司自身的产品设计却无意中导致了大量私密对话的公开。这种表里不一,无疑加剧了公众对OpenAI在隐私保护方面承诺的怀疑。法院指令与此次事件共同指向了一个核心问题:AI企业在数据收集、存储、处理和共享的全生命周期中,究竟应承担怎样的责任与义务?仅仅依靠事后补救和声明,远不足以构建稳固的信任体系。
构建更健全的隐私保护框架
此次ChatGPT隐私泄露事件为整个AI行业敲响了警钟。它再次强调,在AI产品的设计之初,就必须将“隐私保护”(Privacy by Design)原则深度融入。这意味着:
- 默认隐私(Privacy by Default):除非用户明确且清晰地同意,否则所有涉及个人数据的设置都应默认为最高级别的隐私保护状态。
- 透明化与可控性:用户界面应以直观、易懂的方式展示数据处理流程和隐私选项,确保用户能够真正理解并有效控制自己的数据。
- 细致的用户教育:企业有责任引导用户理解其数据的使用方式和潜在风险,而非仅仅提供一份晦涩难懂的服务条款。
- 定期隐私审计:AI系统应定期接受独立的隐私和安全审计,及时发现并弥补潜在漏洞。
- 伦理委员会介入:在AI功能设计和迭代过程中,应有独立的伦理委员会或专家组进行评估,确保产品发展符合社会伦理规范。
此外,行业监管机构也应加强对AI产品隐私合规性的审查与指导,推动制定更为严格的法律法规,确保用户的数字权利在技术创新的浪潮中得到充分保障。这需要构建多方协作的生态系统,共同维护数字世界的安全与秩序。
走向负责任的人工智能之路
OpenAI首席信息安全官斯塔基的声明中提到:“安全和隐私对我们至关重要,我们将继续努力在产品和功能中最大限度地体现这一点。” 这份承诺能否真正落实,将决定OpenAI乃至整个AI行业未来发展的轨迹。人工智能的未来,绝不能以牺牲用户隐私为代价。
只有当技术创新与伦理责任并行不悖,当企业真正将用户数据视为不可侵犯的宝贵资产,并为此构建起铜墙铁壁般的保护机制时,AI才能赢得公众的长期信任,最终实现其造福人类的宏伟愿景。此次事件是宝贵的教训,也是一次重塑行业规范、走向更加负责任的人工智能之路的契机。
构建一个既能释放AI潜力又能确保个人隐私的数字生态系统,是一项复杂而紧迫的任务。这需要技术开发者、政策制定者、伦理学家以及广大用户共同参与,持续对话,不断完善规则,以期最终实现技术进步与人文关怀的和谐共生。








