
WeKnora:腾讯开源大模型赋能文档智能,革新企业知识管理新范式
随着人工智能技术的飞速发展,大语言模型(LLMs)正逐步重塑各行各业的运作模式。在海量的非结构化和半结构化数据中,如何高效、精准地提取、管理并利用知识,成为企业和研究机构面临的共同挑战。传统的文档处理工具往往受限于单一格式或缺乏深度语义理解能力,难以应对日益复杂的知识管理需求。正是在这一背景下,腾讯近期正式开源了基于大语言模型的文档理解与检索工具——WeKnora,这不仅是腾讯在AI领域开放生态的重要举措,更标志着复杂多模态文档处理技术迈入了智能化与模块化的新纪元。WeKnora的推出,旨在为企业知识管理、学术研究、法律合规及医疗健康等多个垂直行业提供坚实的技术底座,赋能高效的知识服务体系构建。
多模态内容理解:跨越格式壁垒的核心能力
WeKnora的核心竞争力在于其卓越的多模态文档解析能力。在实际应用场景中,企业资料、科研报告、法律文书等往往以PDF、Word、图片扫描件等多样化的格式存在,并融合了文本、表格、图像、图表等多种信息载体。传统方法在处理这类混合型文档时,往往面临信息孤岛、格式转换复杂、内容提取不完整等诸多难题。
WeKnora通过整合先进的计算机视觉(CV)技术与自然语言处理(NLP)技术,实现了对这些复杂文档的深度解析。它能够智能识别不同文档元素(如标题、段落、列表、表格结构、图片描述),并将其内容精确提取。例如,对于包含复杂表格的财务报表,WeKnora不仅能识别出表格的行列结构,还能提取其中数值并理解其语义关系。对于内嵌的图片或图表,它能够通过图像识别技术进行内容分析,甚至提取图片中的文字信息。
通过这一系列精细化的处理,WeKnora将来自不同来源和不同模态的信息整合成统一的、结构化的语义视图。这种“化零为整”的能力,极大地提升了信息提取的效率和准确性,打破了传统文档处理的格式壁垒,使得企业和机构能够更全面、更深入地挖掘文档中蕴藏的价值。无论是处理跨国合作的合同文本、分析海量实验数据,还是解析历史档案,WeKnora都能提供一套统一高效的解决方案,为后续的知识检索、分析和应用奠定坚实基础。
智能交互:大模型赋能的深度问答与知识挖掘
在信息爆炸的时代,如何从海量文档中迅速获取所需信息,是衡量知识管理系统效率的关键。WeKnora凭借其集成大语言模型的强大能力,在智能交互方面展现出显著优势。它超越了传统的关键词匹配式搜索,能够深刻理解用户提问的真实意图,即使是复杂或模糊的自然语言问题,也能给出精准且富有上下文逻辑的回答。
其核心在于大语言模型对文档内容的深层语义理解和推理能力。当用户提出问题时,WeKnora不再仅仅是查找包含特定词语的段落,而是能够综合考量文档的整体语义结构、不同章节间的关联以及潜在的逻辑关系,从而生成高度相关的答案。更进一步,WeKnora支持多轮对话功能。这意味着用户可以像与专家对话一样,通过连续的提问来逐步深化对某个主题的探索,或者从不同角度剖析文档内容。例如,用户可以先询问某个项目的主要目标,然后接着提问“实现这些目标的关键挑战是什么?”或者“相关的负责人有哪些?”,系统都能够基于之前的对话语境和文档内容,提供连贯且准确的回复。
这种基于语义理解和多轮对话的智能交互能力,极大地提升了用户获取知识的效率和体验。它使得WeKnora能够作为强大的知识助手,在构建企业内部智能问答系统、辅助科研人员进行文献综述、为法律专业人士提供案例分析支持、或帮助医疗从业者快速查询临床指南等方面,发挥不可替代的作用。它将原本需要耗费大量人工和时间进行的信息检索和梳理工作,转化为高效、智能的交互过程,彻底改变了人与文档交互的方式。
模块化架构:灵活扩展与场景适配的关键
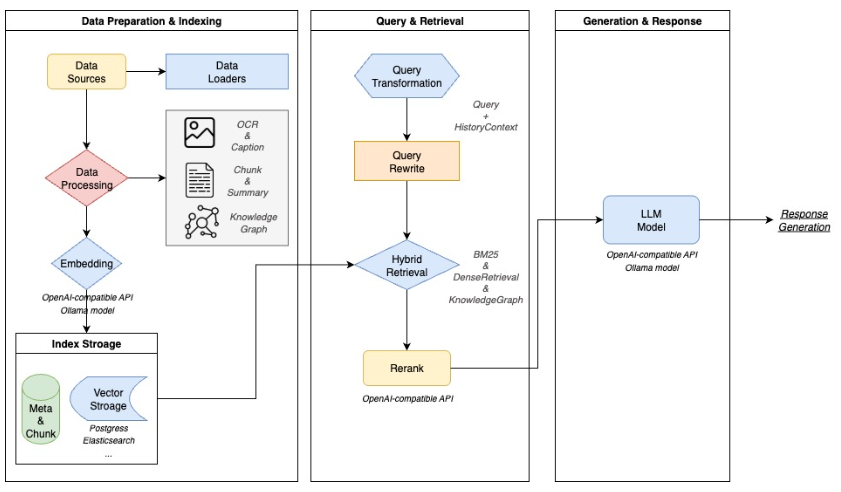
WeKnora在技术架构上采用了精巧的模块化设计,这不仅是其强大功能的基础,也是其能够广泛适应不同行业和定制化需求的关键。整个系统由多个核心组件构成,包括:
- 文档解析模块:负责多模态文档的格式识别、内容提取和结构化处理,为后续的理解和检索提供高质量的原始数据。
- 向量化处理模块:将解析后的文本、图像等内容转换为高维向量表示,这些向量能够捕捉内容的深层语义信息,为高效相似度检索奠定基础。
- 检索引擎:基于向量检索和传统倒排索引的混合策略,实现从大规模文档库中快速、精准地召回相关信息。它能够根据用户查询的语义,从海量知识中定位最匹配的段落或章节。
- 大模型推理模块:利用预训练的大语言模型对召回的上下文信息进行深度理解、总结、问答和生成,确保回答的准确性和连贯性。
这种清晰的模块划分带来了显著的优势:首先,灵活性。每个模块都可以独立更新、优化或替换,使得系统能够快速响应新的技术发展或业务需求。其次,可扩展性。企业和开发者可以根据自身特定场景(例如,针对法律文档定制的解析器,或集成自有领域知识的大模型),选择性地配置或开发新的模块,实现高度定制化的解决方案。最后,易于集成。模块化的接口设计使得WeKnora能够无缝集成到现有的企业信息系统、知识管理平台或业务流程中,降低了部署和应用的门槛。无论是构建复杂的RAG(Retrieval-Augmented Generation)系统,还是优化现有内容管理流程,WeKnora的架构都提供了极大的便利,充分体现了其作为开放工具平台的价值。
应用潜力与行业赋能:构建智能知识生态
WeKnora的开源为众多行业带来了前所未有的智能升级机遇,其应用场景之广泛,预示着一个智能知识生态的逐步形成:
- 企业知识管理与运营:
- 内部知识库构建:帮助企业将散落在各部门、各格式的合同、报告、邮件、会议纪要等沉淀为统一、可检索的知识资产,大幅提升员工查找信息、解决问题的效率。例如,新员工可以快速学习公司制度和项目经验。
- 客户服务优化:集成WeKnora的智能问答系统可赋能客服机器人,使其能够从产品手册、FAQ文档中精准获取信息,提供更智能、更个性化的客户支持,降低人工客服压力。
- 合规与风险管理:对于金融、制药等强监管行业,WeKnora能帮助快速分析和检索海量法规文件,辅助进行合规性审查,及时预警潜在风险。
- 科研创新与学术探索:
- 文献综述与分析:研究人员能够通过自然语言提问,快速从海量学术论文中提取关键实验数据、研究方法和结论,加速文献综述的撰写和新研究方向的探索。
- 跨领域知识融合:WeKnora的多模态能力有助于整合不同学科的文献资料,促进跨学科的知识发现和创新。
- 专业服务领域的转型:
- 法律行业:律师和法律顾问可以利用WeKnora快速检索判例、法条、合同条款,辅助案件分析和文书起草,提升办案效率和准确性。
- 医疗健康:医生和研究人员能够更便捷地查阅临床指南、病例报告、医学文献,辅助诊断、制定治疗方案和进行医学研究,加速知识的传播和应用。
- 知识图谱构建与数据驱动决策:
- WeKnora不仅能提取信息,还能识别文档中的实体和关系,为自动化构建高质量的知识图谱提供基础。通过将非结构化文档转化为结构化知识,企业可以进行更深层次的数据分析、趋势预测和决策支持,实现真正的“数据驱动”。例如,构建一个行业知识图谱,可以帮助企业洞察市场竞争格局、预测技术发展趋势。
开放生态与未来展望:共创智能文档处理新范式
腾讯WeKnora的正式开源,不仅仅是一项技术的发布,更体现了腾讯在人工智能领域坚持开放、共享的战略愿景。通过将这一强大的文档理解与检索工具贡献给全球开发者社区,腾讯旨在汇聚全球智慧,共同加速智能文档处理技术的创新与普及。
开源模式的优势在于其能够吸引广泛的开发者参与,共同发现并解决问题,从而推动技术的快速迭代和功能优化。WeKnora凭借其卓越的多模态处理能力、灵活的模块化设计以及基于大语言模型的智能交互特性,使其在实际应用中具备极高的普适性和扩展性。它为开发者提供了构建各种智能知识应用的基础组件,无论是开发针对特定行业的垂直解决方案,还是集成到现有大型系统中,都具备极高的便利性。
展望未来,随着大语言模型技术的持续演进和多模态理解能力的不断突破,WeKnora有望在更多领域发挥其巨大潜力。我们可以预见,WeKnora将不仅仅局限于文档检索,更可能成为智能内容生成、知识自动化推理、人机协同决策等前沿应用的核心支撑。它的开源将激发更多创新应用场景的涌现,加速企业乃至整个社会迈向更高效、更智能的数字化未来。这正是WeKnora所承载的使命:以开放促创新,以智能赋能知识,共同绘制智能文档处理的新范式。










