
Anthropic的AI模型研发一直走在前沿,而最新推出的Claude Opus 4.1,无疑是其在大型语言模型领域的一次里程碑式飞跃。作为此前广受赞誉的Claude Opus 4的重磅升级版本,Opus 4.1在核心能力、技术架构以及性能表现上均实现了显著的优化与提升,尤其在处理复杂任务和确保模型安全性方面,展现出无与伦比的先进性。它不仅代表了Anthropic对AI技术边界的持续探索,更预示着人工智能在赋能企业智能化转型和推动产业升级方面将扮演更为关键的角色。
Claude Opus 4.1的核心能力深度剖析
Claude Opus 4.1的设计理念在于提供一个全面且高度智能化的AI助手,其核心功能涵盖了多个关键领域,为用户带来了前所未有的操作体验与效率提升:
卓越的高级编程能力
该模型能够实现单次高达32k Token的超长序列输出,这意味着开发者可以处理更为庞大的代码库,进行大规模的项目重构,而无需频繁地进行上下文切换或分批处理,极大地提升了开发效率与复杂任务的应对能力。Opus 4.1不仅能生成高质量、语法正确的代码,更能深度理解上下文,适应不同的编程范式和风格,从而生成高度定制化的解决方案。
强大的Agent(代理)能力
在自动化与决策方面,Claude Opus 4.1展现出强大的自主决策和执行能力。它能够精准管理多渠道营销活动,例如根据市场反馈实时调整投放策略;亦能高效协调复杂的企业工作流程,从项目管理到资源分配,实现跨部门的无缝协作。这种Agent能力使得AI不再仅仅是工具,更是能够独立思考并驱动业务流程优化的智能实体。
深度研究与搜索能力
对于需要大量信息整合与分析的场景,Opus 4.1能够独立完成长达数小时的研究任务。它能同时分析来自专利数据库、学术论文、市场报告等多源异构信息,并进行深度提炼与交叉验证,最终形成全面且富有洞察力的研究报告。这对于企业进行市场策略制定、技术前瞻研究以及风险评估具有无可替代的价值。
高质量内容创作
模型在内容创作领域的表现堪称惊艳,它能生成高质量、自然流畅且富有创意的人类水平文本。无论是需要严谨的报告撰写、富有感染力的市场文案,还是深度挖掘人物情感与故事情节的创意写作,Opus 4.1都能游刃有余。其在故事创作中展现出塑造丰富角色和构建复杂叙事结构的能力,为内容产业带来了全新的创作维度。
灵活的混合推理机制
Claude Opus 4.1支持即时响应和扩展的逐步推理两种模式。用户可以根据任务的紧急程度和复杂性,灵活选择合适的推理方式。对于需要快速反馈的场景,可启用即时推理;而对于需要深度思考、多步骤分析的复杂问题,则可采用扩展推理模式,以确保结果的准确性和全面性。API用户还能精细控制推理预算,实现成本与性能的平衡。
坚实的安全与合规保障
在AI伦理与安全日益受到关注的当下,Claude Opus 4.1在安全性方面表现卓越。通过严格的内部评估,其拒绝违规请求的无害响应率从Opus 4的97.27%进一步提升至98.76%。同时,在处理敏感主题的良性请求时,模型保持了极低的拒绝率,这表明它能够在确保安全性的同时,最大限度地满足用户的正常需求,为企业级应用提供了坚实的信任基础。
Claude Opus 4.1底层技术原理剖析
Claude Opus 4.1之所以能够实现上述卓越性能,得益于其背后先进且复杂的AI技术架构和训练方法:
基于Transformer的架构
模型的核心是Transformer架构,这是一种在自然语言处理领域具有里程碑意义的神经网络结构。它通过多头自注意力机制(Multi-Head Self-Attention)有效捕捉长序列数据中的复杂上下文关系和依赖性,无论文本长度如何,都能保持高效的信息编码与解码能力。这种架构使得模型在理解和生成语言时具备了深厚的语义洞察力。
大规模预训练与知识沉淀
Claude Opus 4.1在海量的文本和代码数据上进行了大规模的预训练。这一阶段的目标是让模型学习到语言的内在语法结构、丰富的语义信息以及隐含的逻辑关系。通过无监督学习方法,特别是预测文本序列中的下一个词语,模型能够内化人类语言的复杂模式,为后续的特定任务处理打下坚实基础。
精准的指令微调(Instruction Tuning)
预训练之后,模型通过指令微调进一步提升其理解和执行用户指令的能力。针对编程、写作、问答等各类具体任务,Anthropic设计了大量的指令-响应对进行精细化训练。这使得模型不仅能“知道”信息,更能“理解”并“按照指令”生成高质量的输出,极大地增强了模型的实用性和可控性。
创新的混合推理机制
模型内部集成了独特的混合推理机制,能够根据任务特性智能切换推理模式。例如,对于需要快速回答的问题,模型可以采用更直接的推理路径;而对于需要逐步分析、逻辑推演的复杂问题,则能展开更深入、更耗时的“思考”过程。这种机制确保了模型在不同场景下都能提供最优的性能表现。
多维度安全对齐与伦理保障
Anthropic在Opus 4.1的研发过程中,将安全性和对齐机制置于核心地位。模型通过广泛的单轮和多轮测试,全面评估其在拒绝恶意请求、避免生成偏见内容以及保护用户隐私等方面的表现。结合强化学习(Reinforcement Learning from Human Feedback, RLHF)和一系列安全训练,确保模型的行为与人类价值观和Anthropic的使用政策保持高度一致,从而降低潜在风险。
Claude Opus 4.1的卓越性能表现
通过多项严苛的基准测试,Claude Opus 4.1展现出领先业界的性能指标,尤其在编程和复杂任务处理上优势明显:
编程能力遥遥领先
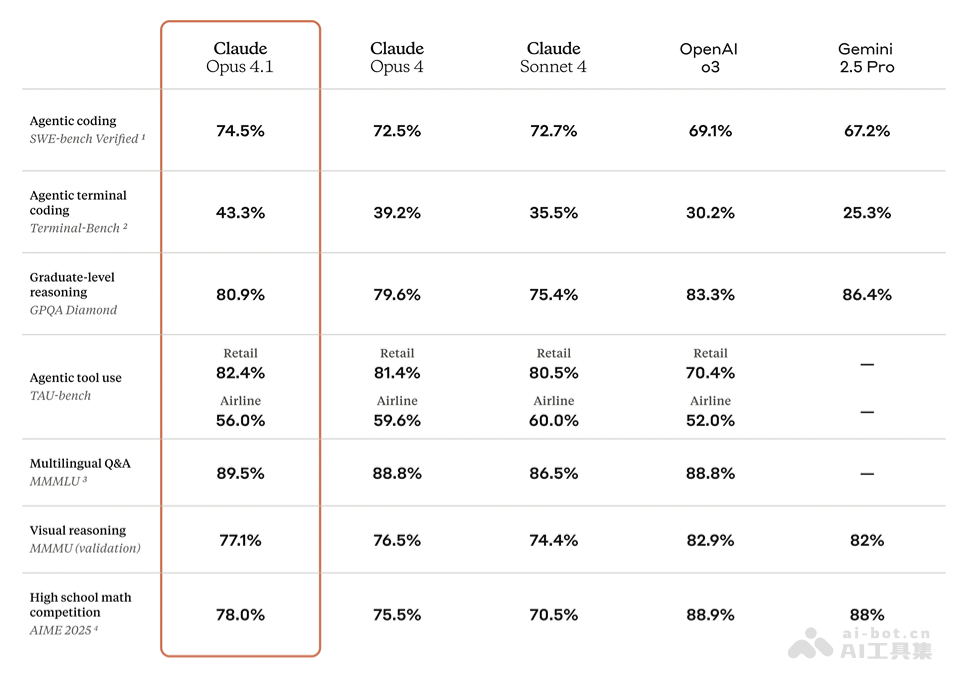
在权威的SWE-bench Verified基准测试中,Claude Opus 4.1取得了惊人的74.5%得分,这不仅相比前一版本Opus 4提升了2个百分点,更显著超越了包括OpenAI的GPT-4.1(仅为54.6%)在内的诸多竞品模型,以及自家的Sonnet 3.7(62.3%)。这一数据有力证明了Opus 4.1在代码生成、修复和理解方面的行业领导地位。
优化长时程任务处理
模型在处理复杂且耗时的长时程任务方面表现出色。例如,在TAU-bench等基准测试中,Opus 4.1能够自主管理多渠道营销活动,协调跨功能企业工作流程,并能准确处理需要多步骤逻辑推演的任务。其持久的上下文记忆能力和任务分解能力,使其成为自动化复杂业务流程的理想选择。
综合推理能力突破
针对Agentic编码和推理能力的基准测试显示,Claude Opus 4.1在绝大多数指标上均领先于Opus 4及其他主流竞品,如OpenAI o3和Gemini 2.5 Pro。这表明模型不仅在单一任务上表现优异,更能在需要多方面推理、规划和执行的复杂场景中展现出卓越的综合智能。
显著提升无害响应率
在单轮测试中,Claude Opus 4.1的无害响应率达到了98.76%,这一数据相较于Opus 4的97.27%有显著提升。这体现了Anthropic在模型安全性与可靠性上的不懈努力,为模型的广泛应用提供了坚实的安全保障,尤其对于企业级用户而言,这意味着更高的合规性和更低的风险。
Claude Opus 4.1的多元化应用场景展望
Claude Opus 4.1的强大功能使其在多个行业和领域拥有广阔的应用前景,为用户带来变革性的解决方案:
软件开发与代码优化
开发者可以利用Opus 4.1生成高质量、符合最佳实践的代码,进行多文件、跨模块的代码重构,甚至协助调试复杂程序。其长序列输出能力尤其适用于处理大型项目中的遗留代码或进行新模块的快速原型开发,显著缩短开发周期,提升软件质量。
企业自动化流程管理
模型能够自主管理和优化企业内部的复杂流程,例如自动化客户服务响应、优化供应链管理、协调跨部门项目进度、以及生成定制化的业务报告等。通过减少人工干预,Opus 4.1将助力企业实现运营效率的飞跃式提升。
市场研究与学术研究
对于需要深入洞察和分析的场景,Opus 4.1能独立进行数小时的数据挖掘与信息整合。无论是分析市场趋势、评估竞争格局、进行专利检索,还是综合学术文献、提炼研究发现,它都能提供全面、客观且富有前瞻性的洞察,为战略决策提供强有力的数据支撑。
高效内容创作与文案撰写
从市场营销的广告文案、社交媒体内容,到企业的技术文档、新闻稿,乃至创意文学作品和剧本创作,Opus 4.1都能快速生成高质量、符合语境、且风格多样的文本。这将极大地解放内容创作者的生产力,并为各类媒体和出版机构提供强大的内容引擎。
教育与个性化学习辅助
在教育领域,Opus 4.1可以作为个性化学习的智能伴侣,为学生提供定制化的学习建议、解答复杂的学术问题、生成练习题和学习材料。它还能模拟不同角色进行互动对话,帮助学生进行语言练习或场景模拟,从而提升教学效果和学习体验。
驱动未来的智能引擎
Anthropic Claude Opus 4.1的推出,不仅仅是一个技术进步,它更是人工智能赋能各行各业、驱动创新发展的关键引擎。其在编程、Agent能力、深度搜索、内容创作以及安全保障等方面的全面提升,使得AI不再局限于辅助性角色,而是能够深度参与并优化核心业务流程的战略性资产。随着技术的不断演进和应用场景的持续拓展,我们可以预见,Claude Opus 4.1将成为未来智能世界中不可或缺的一部分,引领人类与AI协作进入一个全新的纪元,共同构建一个更高效、更智能的未来。










