
AI时代内容获取的灰色地带:Perplexity“隐形爬虫”争议深度解析
人工智能技术飞速发展,深刻改变了信息获取与内容生产的方式。然而,随之而来的数据伦理与知识产权挑战也日益凸显。近期,全球知名的网络安全与优化服务商Cloudflare对AI搜索引擎Perplexity提出严厉指控,称其利用“隐形战术”规避网站的爬取限制,这不仅触及了互联网长期以来秉持的规范,更将AI时代的内容版权争议推向了风口浪尖。
违规爬取:Cloudflare揭露Perplexity的“隐形战术”
Cloudflare的指控并非空穴来风,而是基于其客户反馈与深入调查。据Cloudflare研究人员透露,尽管许多网站已通过robots.txt文件或Web应用防火墙(WAF)明确禁止Perplexity的已知爬虫访问,但这些网站的内容依然被持续获取。这一现象引发了Cloudflare的警觉,促使其启动了一系列旨在验证这些匿名访问源头的测试。
测试结果令人震惊。Cloudflare发现,当Perplexity的“声明”爬虫遭遇robots.txt或防火墙规则的阻拦时,Perplexity会迅速切换至一种“隐形爬虫”模式。这种模式下,其爬虫不再使用官方声明的IP地址范围,而是通过频繁轮换未公开的IP地址进行访问。更甚者,这些请求还会来自不同的自治系统号(ASNs),以期进一步规避网站的拦截策略。Cloudflare指出,这种违规行为遍及数万个域名,每天产生数百万次请求,其规模之大令人侧目。
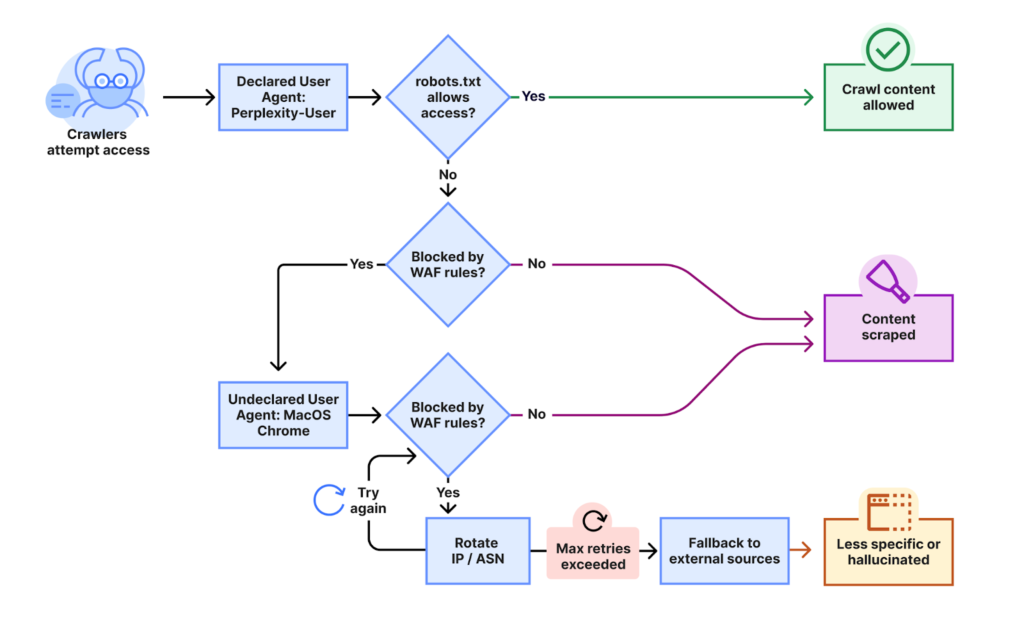
这一策略的本质在于利用IP地址和ASN的动态变化,制造一种“隐形斗篷”,使得网站管理员难以识别和阻止其违规行为。Cloudflare提供的示意图清晰地展示了这一“声明爬虫被阻止后,Perplexity切换到隐形爬虫,通过轮换IP和ASN继续访问”的流程。这种刻意规避阻拦的手段,无疑是对互联网互信基础的严重挑战。
互联网三十年共识的动摇:Robots排除协议的基石
Perplexity被指控的行为,直接冲击了互联网运行近三十年的核心规范——Robots排除协议(Robots Exclusion Protocol),即广为人知的robots.txt标准。早在1994年,工程师Martijn Koster便提出了这一协议,旨在为网站提供一种机器可读的格式,告知爬虫哪些区域允许访问,哪些区域应被排除。这一简单而有效的机制,成为了网站内容索引与网络爬虫之间默认的“君子协定”。
自其诞生以来,robots.txt标准得到了广泛的遵守与认可,并于2022年正式成为互联网工程任务组(IETF)的官方标准(RFC 9309)。它不仅代表了技术上的互操作性,更承载着互联网社区对内容所有者意愿的尊重。遵守robots.txt不仅仅是技术层面的合规,更是网络伦理与文化的重要体现。Perplexity的“隐形爬虫”行为,如果属实,无疑是对这一共识的公然藐视,动摇了开放网络生态的信任根基。
并非孤例:Perplexity面临的多方质疑与内容侵权指控
Cloudflare并非首次对Perplexity提出质疑。事实上,Perplexity在过去一年中已多次因其数据获取方式而饱受争议。
2024年,Reddit首席执行官Steve Huffman曾公开抱怨Perplexity,以及微软和Anthropic等其他AI引擎,称它们“像对待互联网上所有内容一样,认为可以免费使用”。Huffman的言论反映了内容创作者对AI模型未经许可大规模抓取和利用其内容的普遍不满。
更为直接的指控来自出版界。知名商业杂志《福布斯》曾指责Perplexity存在“蓄意的盗窃行为”。福布斯指出,Perplexity发布的一篇文章与《福布斯》前一天发布的独家文章“极其相似”,暗示其存在直接抄袭行为。
无独有偶,《连线》(Wired)杂志,作为Ars Technica的姐妹刊物,也提出了类似的指控。Wired声称,Perplexity不仅存在内容剽窃,还被发现篡改其爬虫的ID字符串以绕过网站的拦截。这些指控都指向Perplexity利用技术手段规避网站限制,并在未经授权的情况下复制和利用受版权保护的内容,这不仅是技术层面的违规,更触及了法律和道德的底线。

这些案例共同描绘了一个令人担忧的趋势:随着AI模型对高质量训练数据的渴求日益增长,一些AI公司可能会为了追求数据而剑走偏锋,挑战既有的网络规范和知识产权法律。这不仅损害了内容创作者的利益,也可能扭曲健康的网络生态。
Cloudflare的应对与行业反思:构建负责任的AI生态
面对Perplexity的“隐形爬虫”行为,Cloudflare已采取果断措施。研究人员表示,鉴于Perplexity的行为与透明、有明确目的、遵守网站指令的爬虫原则不符,Cloudflare已将其从“认证爬虫”列表中移除,并增加了新的启发式管理规则,以阻止这种隐形爬取。这意味着Cloudflare正在利用其强大的网络基础设施和分析能力,积极捍卫其客户的权益和互联网的公平原则。
这一事件引发了业界对于AI数据获取伦理的深刻反思。人工智能的未来发展,无疑需要海量数据作为支撑。然而,数据的获取方式必须是透明、合法和道德的。忽视或刻意规避既定的网络规范,不仅会损害个别网站的利益,长远来看,也将侵蚀AI技术赖以生存的信任基础,甚至可能招致更严格的监管和法律制裁。
以下是几点行业应深入思考的关键问题:
- 数据伦理与透明度: AI公司在数据采集过程中,是否充分尊重内容所有者的意愿?是否提供了透明的机制让网站管理者了解其数据使用方式?
- 知识产权与合理使用: 如何界定AI训练和内容生成中“合理使用”的边界?在多大程度上,AI系统可以引用、整合甚至改写现有内容而不构成侵权?这需要法律界、技术界和内容界共同努力,制定更清晰的指导原则。
- 技术对抗与合作: 网站如何有效识别和阻止恶意爬虫?Cloudflare的案例表明,技术反制是可能的,但更重要的是,AI公司应主动与内容创作者和网络服务商合作,共同构建一个公平、共赢的数据生态。
- 监管与行业自律: 在缺乏明确法律框架的情况下,行业自律显得尤为重要。AI公司是否有责任主动公开其爬虫行为准则,并承诺遵守既定的网络协议?
展望未来:AI与内容产业的共赢之路
Perplexity事件是AI技术与传统内容产业摩擦的一个缩影。它提醒我们,在拥抱AI带来的巨大便利和潜力时,绝不能忽视其可能带来的伦理挑战和潜在风险。要实现AI与内容产业的真正共赢,需要各方共同努力:AI开发者应坚持负责任的创新,确保数据获取的合法性和透明性;内容创作者应积极探索与AI技术结合的新商业模式,同时坚决捍卫自身的知识产权;而监管机构和行业组织则需及时跟进技术发展,制定符合时代需求的法律法规和行业标准。
只有当技术进步与伦理规范并行不悖,AI才能真正成为推动社会进步的积极力量,而不是内容生态的潜在破坏者。此次Perplexity事件,无疑为所有AI从业者敲响了警钟,敦促我们重新审视并加强对数字世界互信原则的承诺。








