
人工智能时代的数据挑战与智能基础设施的崛起
当前,人工智能技术正以惊人的速度迭代演进,其核心驱动力在于对海量数据的深度挖掘与智能运用。数据智能,已然成为企业在全球竞争格局中构筑核心优势的关键要素。然而,伴随大模型技术的广泛应用,一系列深层挑战也逐渐浮出水面,例如其固有的“幻觉”问题导致信息失真,多模态应用在数据处理与理解上遭遇瓶颈,以及企业内部庞大且碎片化的私有知识难以被高效利用,这些都严重制约了AI赋能的深度与广度。面对这些迫切需求,业界普遍呼唤更强大、更智能的数据管理系统,以构建下一代人工智能的坚实基石。
在此背景下,同方知网数科凭借其在知识服务领域积累的深厚底蕴,重磅推出了AIKBase向量数据库管理系统V2.0。这一创新成果旨在为人工智能系统提供一个更为“聪明”的“数据大脑”,从根本上重塑传统的数据基础设施,使其能够更好地服务于复杂多变的AI应用场景,尤其是在处理非结构化和多模态数据方面,展现出前所未有的效率与准确性。
AIKBase V2.0:构建AI“数据大脑”的核心能力解析
AIKBase V2.0是一款集搜索型与向量型双重优势于一体的多模态数据管理系统。它并非简单的数据存储库,而是通过整合五大核心特性,全面赋能大模型,旨在帮助千行百业实现真正意义上的智能化升级。其设计理念,正是围绕着如何高效、安全、精准地管理和利用海量异构数据,从而为各类AI应用提供强大的数据支撑。
国产自主可控与卓越兼容性
在当前国际形势下,数据安全与技术自主可控已上升为国家战略高度。AIKBase V2.0正是积极响应这一号召的产物,它全面支持鲲鹏、飞腾等国产CPU架构,并深度兼容统信、麒麟等国产操作系统,完全符合国家信创标准。这意味着企业在享受AIKBase强大功能的同时,能够获得双重保障,确保核心数据资产的安全与主权。
更值得一提的是,AIKBase V2.0具备极高的灵活性与开放性。其灵活的嵌入能力和兼容多种数据格式的检索引擎,使其能够无缝适配当前市场上的任意主流大模型。无论是进行RAG(检索增强生成)以提升大模型回复的准确性,还是为特定的知识增强场景打通数据链路,AIKBase V2.0都能作为核心组件,确保数据流的畅通无阻,极大地简化了AI应用的开发与部署复杂度。
统一多模态数据管理与高效写入
在现实世界中,信息往往以多种模态呈现,包括文本、图像、视频、音频等。传统的数据管理系统在处理这些异构数据时,常常面临数据孤岛和管理效率低下的问题。AIKBase V2.0的出现,彻底改变了这一局面。它能够支持各类主流数据库的数据迁移,并将非结构化数据智能地“翻译”成向量表示,进而统一存储于其高效的数据仓库之中。
这种统一管理能力不仅简化了数据架构,更重要的是,它为后续的跨模态分析与应用奠定了基础。无论是海量文档的批量导入,还是图片、视频等新型数据的实时更新,AIKBase V2.0都能实现毫秒级的快速操作。其高吞吐量的数据写入能力,确保了系统能够应对数据量的爆炸式增长,并保证数据的时效性和完整性。
毫秒级向量检索与精准向标融合查询
在海量数据中快速而准确地找到所需信息,是数据智能的核心挑战之一。AIKBase V2.0通过引入毫秒级向量检索技术,实现了基于语义理解的“智能搜索”。传统关键词检索往往受限于字面匹配,难以捕捉词汇背后的深层语义。而向量检索通过将文本、图像等内容转换为高维向量,在向量空间中计算相似度,从而实现语义层面的精准匹配,即使是描述方式不同但意义相近的内容也能被准确召回。
更进一步,AIKBase V2.0创新性地提供了向标融合检索技术。这意味着用户可以自由组合向量检索的“语义理解”能力、标量检索的“结构化过滤”能力以及全文检索的“精准匹配”能力。例如,在查询一篇关于“人工智能”的报告时,不仅可以根据语义查找相关内容,还可以根据作者、时间、关键词等结构化标签进行精确筛选。在亿级数据量下,这种融合检索依然能够实现毫秒级响应,显著提升了检索的深度、广度与效率,确保用户总能获取到最精准、最全面的信息。
分布式集群架构与弹性扩展
随着业务规模的不断扩大和数据量的持续增长,系统的可扩展性与高可靠性成为决定其生命力的关键。AIKBase V2.0采用了先进的分布式集群架构,这意味着系统可以轻松进行水平扩展,通过增加节点来提升整体性能和存储容量。这种架构不仅能够确保在面对大规模并发查询和数据写入时依然保持高性能响应,还具备高可用性与容错能力。
分布式集群的优势在于其弹性伸缩的特性,能够根据实际业务需求动态调整资源配置,避免资源浪费,同时确保服务的连续性和稳定性。这对于需要处理海量数据、承载高并发访问的企业级AI应用而言,是不可或缺的基石。它为企业提供了灵活、可靠且高效的数据基础设施,能够从容应对未来业务的快速增长与演变。
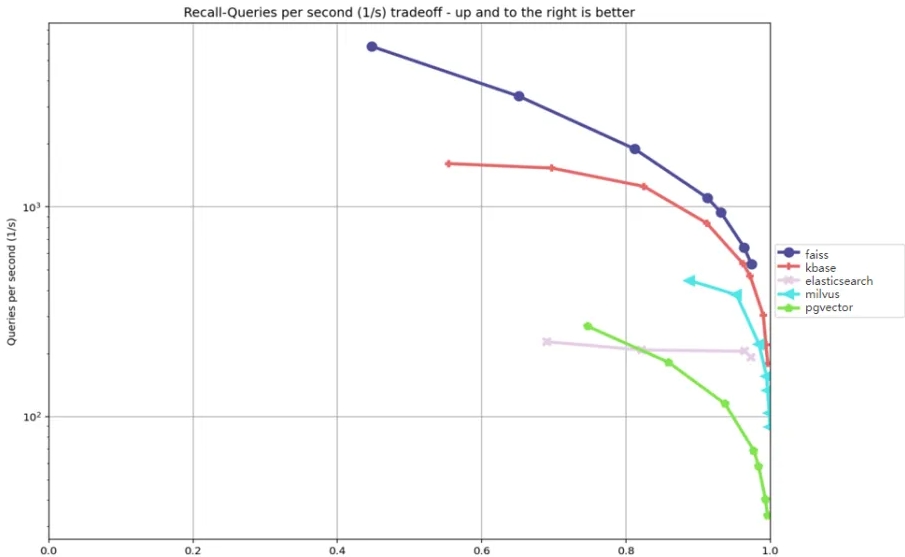
性能实测:AIKBase V2.0如何超越传统数据库
为了验证AIKBase V2.0在实际运行中的卓越性能,同方知网数科利用开源评测工具ANN-Benchmarks,对其进行了严谨的对比测试。测试对象包括了pgvector、Milvus、ElasticSearch等当前主流的开源数据库或向量检索方案。
测试结果令人印象深刻。在关键的90%召回率查询最大吞吐量(QPS)方面,AIKBase V2.0表现显著优于上述所有开源数据库,这表明其在提供高精度检索的同时,能够处理更高的并发请求。此外,在数据写入吞吐量方面,AIKBase V2.0也展现出更高的效率,能够更快地将新数据纳入索引。更短的索引构建耗时则意味着系统能够更快地准备好可供检索的数据,缩短了数据从入库到可用的时间。这些测试数据充分印证了AIKBase V2.0“存得快、找得准、反应快”的核心优势,为AI应用提供了坚实可靠的高性能数据底座,显著提升了数据处理与利用的整体效率。
赋能行业:AIKBase V2.0的广泛应用图景
AIKBase V2.0凭借其强大的功能与卓越的性能,正在多个行业领域展现出广阔的应用前景,成为赋能各行各业实现智能升级的关键力量。
大模型“去幻觉”与私有知识库构建
大模型的“幻觉”问题,即模型生成不准确或虚假信息,是当前AI应用面临的一大挑战。AIKBase V2.0通过为大模型提供高效、精准的私有知识库,能够有效解决这一痛点。它能够将企业内部的文档、报告、案例等私有数据构建成可检索的知识体系,当大模型生成内容时,可以通过AIKBase快速检索并获取最新的、最权威的私有知识作为参考,从而大幅提升生成内容的准确性与时效性。这对于企业内部的智能客服、智能问答、内容创作辅助等场景具有里程碑式的意义,确保了AI输出的可靠性和专业性。
跨模态检索与智能知识关联
在日益丰富的数字内容生态中,信息不再局限于单一文本形式。AIKBase V2.0的多模态检索能力,实现了文本、图像、视频等不同模态信息之间的秒级语义关联。例如,用户可以通过输入一段文字来搜索相关的图片或视频片段(以文搜图/视频),或者通过上传一张图片来查找相关的文字描述或文章(以图搜文)。这种跨模态的检索能力,极大地拓宽了知识获取的维度,为内容理解、媒体分析、智能安防、医疗影像诊断等领域提供了全新的解决方案,使得复杂信息的获取变得更加直观和高效。
混合检索:精度与效率的双重飞跃
纯粹的向量检索虽然擅长语义理解,但在某些需要精确匹配特定关键词的场景下可能略显不足;而传统的全文检索则缺乏对语义的深层理解。AIKBase V2.0巧妙地融合了向量检索的“语义理解”和全文检索的“精准匹配”优势,实现了混合检索功能。这种结合能够应对更为复杂的查询需求,例如在海量的学术论文库中,既要查找与“量子计算”概念相关的最新研究,又要精确匹配提及“2025年应用前景”的段落。混合检索显著提升了检索结果的精度和召回率,使用户能够以更高的效率找到所需信息,极大地优化了知识发现和信息利用的体验。
融入知网生态:AIKBase V2.0的未来展望
作为国内领先的知识服务基础设施提供商,同方知网数科将AIKBase V2.0深度融入其庞大的产品矩阵,这无疑标志着其在构建未来智能知识服务生态方面迈出了关键一步。AIKBase V2.0正为知网旗下包括AI增强检索、学术研究助手在内的多项核心功能提供强大的底层支撑。多模混合检索技术的应用,使得知识获取过程变得前所未有的智能;而毫秒级的响应速度,则确保了用户在使用各类知识服务时的极致高效体验。
展望未来,AIKBase V2.0不仅仅是一款先进的数据管理系统,它更是知网积极拥抱人工智能、推动知识服务模式创新的重要载体。它的推出,不仅解决了当前AI应用面临的数据管理痛点,更为学术研究、企业决策、社会创新提供了强大的技术引擎。通过不断的技术迭代与应用拓展,AIKBase V2.0将持续推动AI技术在各领域的深度融合与应用,为构建一个更加智能、高效的数字社会贡献核心力量。








