
GPT-5:人工智能模型能力的新里程碑与通用智能的探索
OpenAI在近期夏季发布会上正式推出了备受瞩目的GPT-5模型,标志着大型语言模型领域的一次显著飞跃。此次发布会详细展示了GPT-5在多模态理解、代码生成、逻辑推理等核心能力上的全面提升,并将其定位为构建“超级智能”愿景中的关键一步。这一新模型不仅重新定义了AI性能的上限,更在可靠性和安全性方面取得了突破,为人工智能的未来发展描绘出宏伟蓝图。
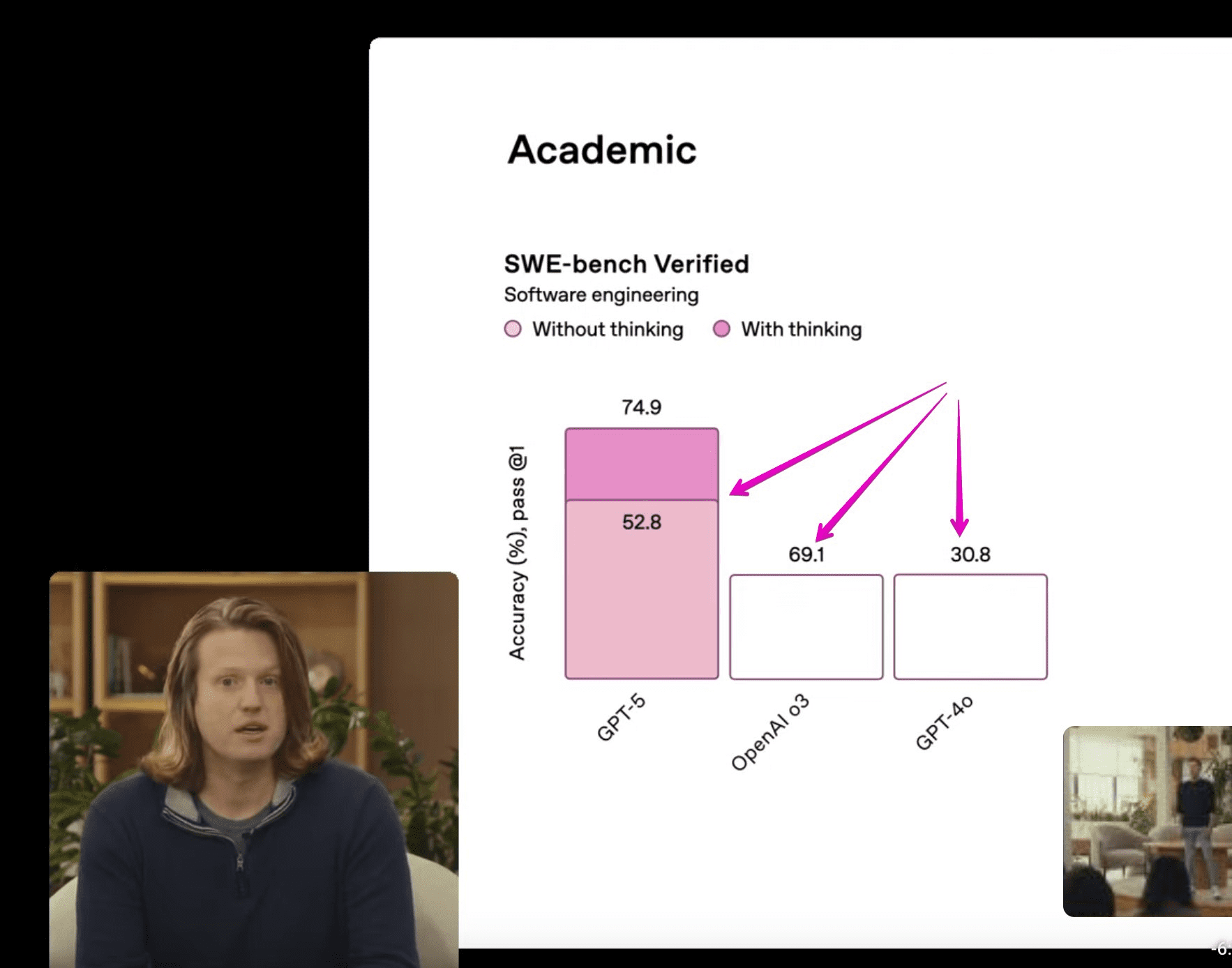
GPT-5的推出意味着OpenAI在模型能力竞赛中重新夺回了领先地位。根据官方公布的数据,GPT-5在多项基准测试中表现卓越,尤其在文本理解、网页开发(WebDev)以及视觉感知能力方面均位列榜首。在硬提示、编码、数学、创造力和长查询处理等复杂任务中,其性能更是达到了前所未有的高度。具体来说,GPT-5在代号为“峰会”的内部测试中,取得了当前Arena评分体系下的最高分数,实现了“屠榜”式的表现。
OpenAI首席执行官Sam Altman将GPT-5的能力提升形象地比喻为从“中学生”到“博士级别专家”的质变。他强调,如果说早期模型如GPT-4o仍像是与一名大学生对话,那么GPT-5则首次带来了与一位具备深厚专业知识的博士级专家交流的真实感受。这种认知能力的飞跃,使得GPT-5在处理复杂问题和提供专业见解时,展现出前所未有的深度和准确性。Altman甚至在发布会上大胆断言,GPT-5是当前世界上编码能力最强、写作能力最强、以及在医疗保健领域表现最强的模型,预示着其在多个行业应用中的巨大潜力。
告别“幻觉”:AI可靠性的显著提升
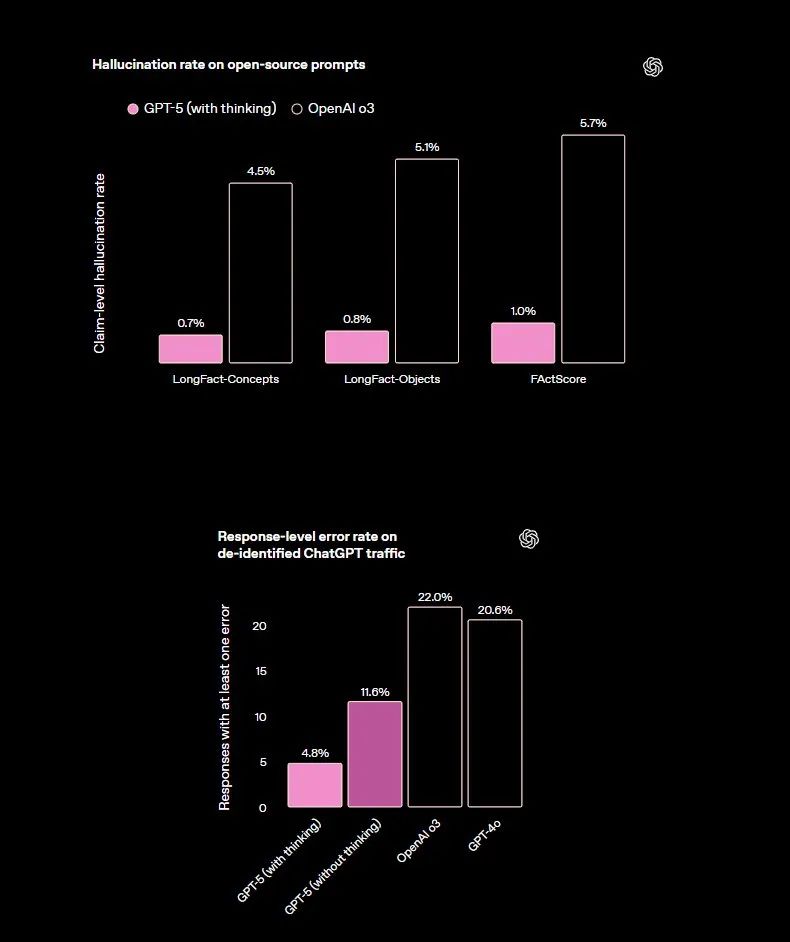
“AI幻觉”问题一直是大型语言模型广受诟病的核心缺陷。令人振奋的是,GPT-5在解决这一问题上取得了重大进展。OpenAI官方宣称,GPT-5产生幻觉的可能性已“显著降低”。
具体数据支撑了这一声明:在进行联网搜索时,GPT-5的回答出现事实性错误的概率比GPT-4o低了45%。更令人印象深刻的是,在独立思考模式下,其回答出错的概率相较于OpenAI o3模型更是大幅降低了80%。这些数据表明,GPT-5在事实准确性和信息可靠性方面达到了新的高度,极大地增强了用户对其输出内容的信任度。
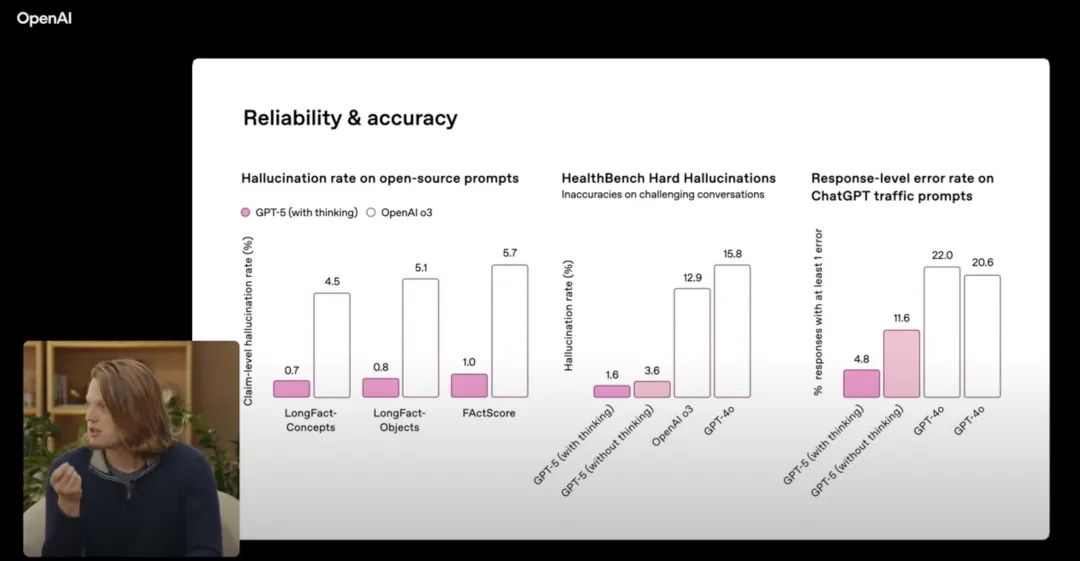
此外,GPT-5在ARC-AGI-2等新型测试中的表现也优于绝大多数主流模型,进一步印证了其在逻辑推理和认知能力上的优势。模型不仅在技术层面更加强大,在“伦理”层面也变得更为“诚实”。它不再倾向于对用户撒谎,也不再自吹自擂能够完成力所不能及的任务。当遇到无法完成、指令模糊或缺乏必要工具的任务时,GPT-5会更加坦诚地沟通其局限性,从而避免了无效的尝试和误导性的信息。
此次更新还引入了四种全新且可选的“人格”模式,包括犬儒(Cynic)、机器人(Robot)、倾听者(Listener)和学霸(Nerd)。用户可以根据个人喜好,自由设定ChatGPT与其互动和回答问题的方式,从而实现更加个性化和场景化的交流体验。例如,用户可以设定模型以耐心倾听者的姿态回应,也可以选择让其以专业学霸的风格提供深入分析。同时,ChatGPT还支持为单个聊天窗口更改颜色主题,提升了用户界面的定制化程度。
“软件按需生成”时代:代码能力的里程碑式突破
GPT-5在代码能力上的提升被Sam Altman视为一项具有划时代意义的突破,他预测这将开启一个名为“软件按需生成”的新时代。这意味着未来用户只需通过简单的自然语言描述,即可驱动AI模型生成复杂的软件和应用程序,极大地降低了软件开发的门槛和成本。
OpenAI的内部测试数据显示,GPT-5在SWE-Bench、SWE-Lancer和Aider Polyglot等多个编码基准测试中,表现均超越了任何其他现有模型。在人类最终测试中,GPT-5取得了42%的优异成绩,而在SWE基准测试中更是达到了75%的完成率。这些数据充分证明了GPT-5在理解、生成和优化代码方面的卓越能力。
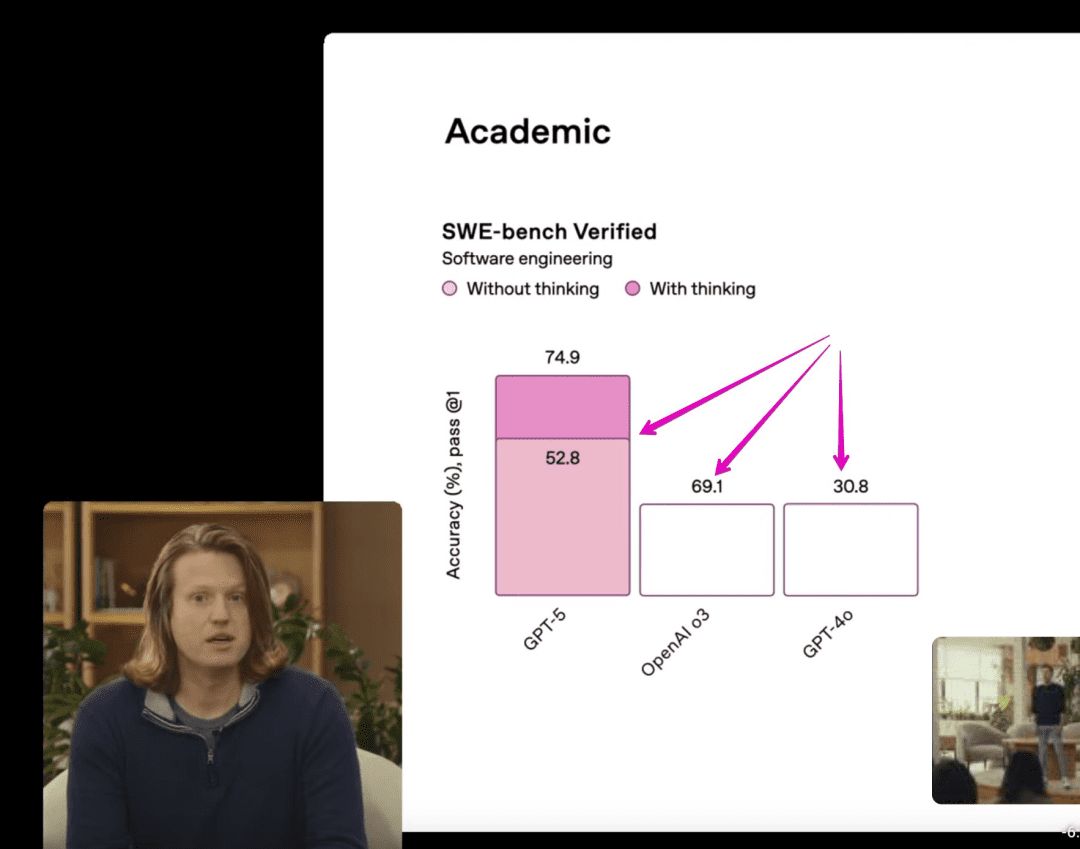
发布会现场,OpenAI的后期训练负责人Yann Dubois通过实时演示,直观地展现了GPT-5强大的编码能力。他要求模型生成一个用于学习法语、并带有互动游戏的网站。令人惊叹的是,在短短几秒钟内,GPT-5便编写了数百行代码,并直接呈现了可交互的前端界面。这一演示不仅彰显了模型的高效性,也预示着AI在软件工程领域将扮演越来越重要的角色。此外,发布会还展示了一款完全由GPT-5根据一段提示词创作的3D游戏。这款游戏不仅拥有精致的画面,其内部的物理效果也得到了高度准确的还原,进一步拓宽了AI在创意内容生成领域的应用边界。
模型安全与实用性:更安全、更“诚实”的交互体验
模型安全研究负责人Alex Beutel介绍,为了全面评估和理解潜在风险,OpenAI对GPT-5进行了超过五千小时的严格测试。测试的重点之一是确保模型不会对用户提供虚假信息。尽管GPT-5的“幻觉”现象已大幅减少,但“自信地撒谎”仍是大型语言模型固有且需持续解决的问题。当模型开始作为智能体执行多步骤任务时,这一问题的重要性更为凸显。OpenAI表示,GPT-5在更可靠地处理多步骤任务方面表现出色,避免了此前模型“声称完成任务但实际并未完成”的情况。
对于以往会直接拒绝回答的敏感或复杂提示,GPT-5引入了名为“安全补全”(safe completions)的新机制。Beutel解释说,例如,当用户询问“点燃某种特定材料需要多少能量?”时,这可能是一个恶意问题,也可能是一个学生出于学习目的的疑问。这种模糊性给模型的回应带来了挑战。通过“安全补全”机制,GPT-5试图在保持安全约束的前提下,给出尽可能有帮助的答案。模型通常只会部分遵从指令,并提供一些无法被用于造成实际伤害的、更宏观层面的信息,从而在用户需求和安全边界之间找到平衡。

获取与定价:GPT-5的广泛可用性与未来展望
关于GPT-5的获取方式,OpenAI提供了令人惊喜的免费体验机会。所有ChatGPT用户现在都可以立即免费体验GPT-5。这是OpenAI首次向所有用户免费开放其前沿模型,旨在加速技术普及和用户反馈。不同订阅级别的用户将享有不同的权限:Plus订阅用户在达到使用上限前可以享受更多的使用次数,而Pro订阅用户则可以访问具备更强推理能力的GPT-5 Pro版本。当用户达到使用上限后,ChatGPT会自动切换到“迷你版”的GPT-5来处理后续请求,确保服务的连续性。
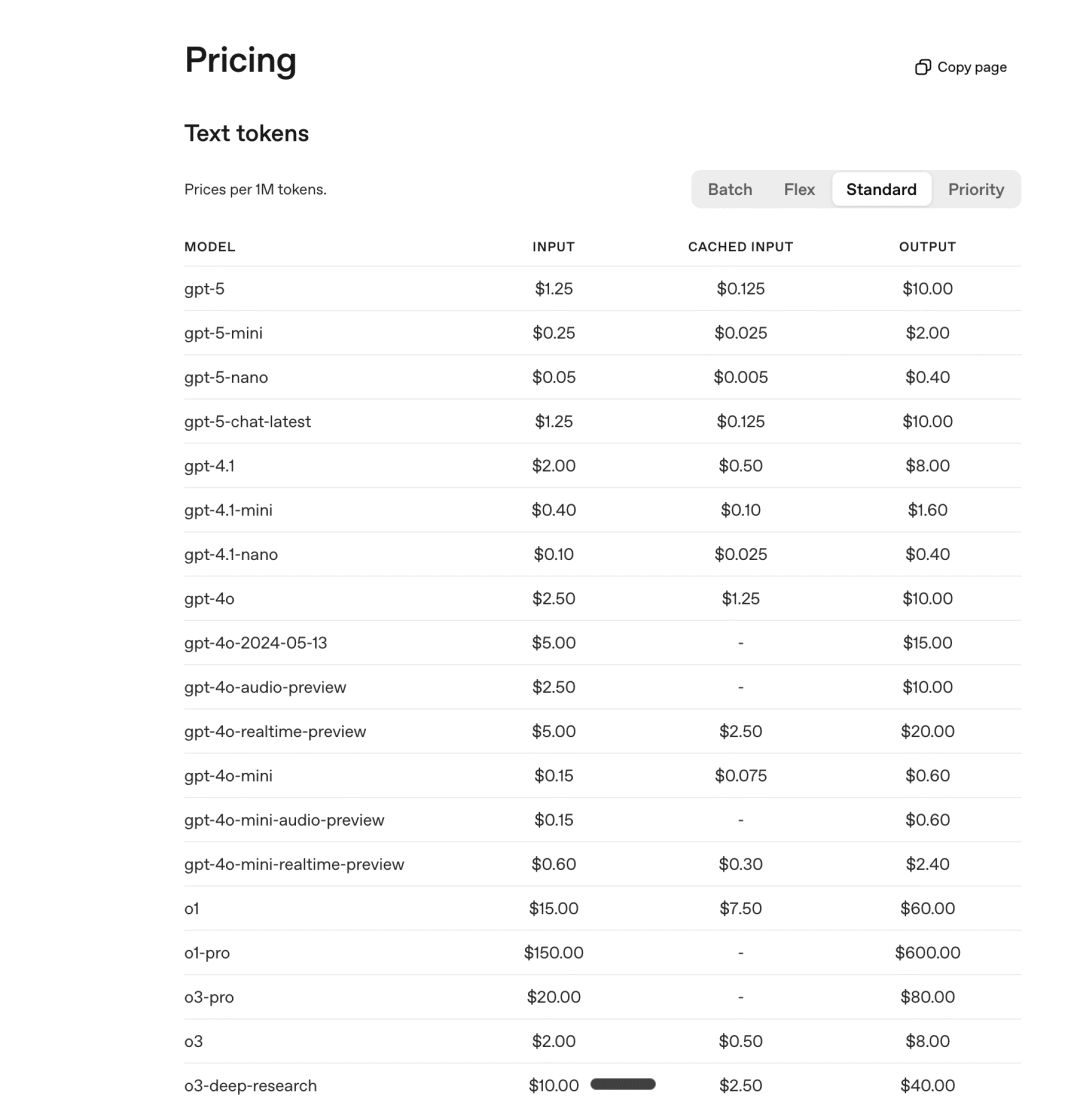
随着GPT-5的上线,它将正式取代GPT-4o、OpenAI o3、OpenAI o4-mini、GPT-4.1和GPT-4.5等一系列旧有模型,实现了模型体系的精简和统一。在API定价方面,标准版GPT-5的每百万输入Token定价为1.25美元,每百万输出Token定价为10美元。同时,OpenAI也提供了价格更为亲民的mini版和Nano版。此外,API中还发布了一个名为“Minimal”的新参数,允许开发者在所有用例中根据推理需求灵活调整GPT-5的使用力度。

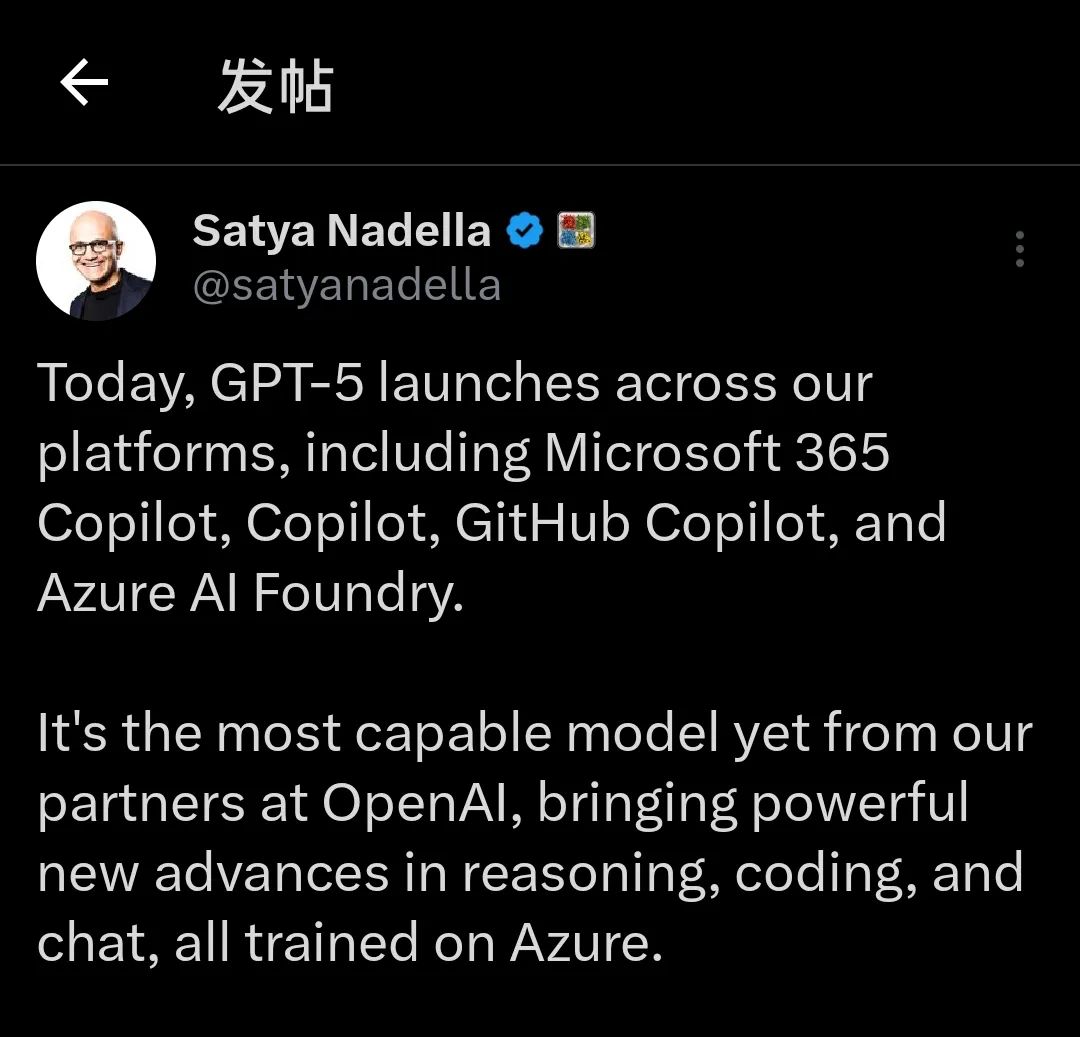
除了OpenAI的第一方平台,微软首席执行官纳德拉也宣布,GPT-5已全面上线微软旗下平台,包括Microsoft 365 Copilot、Copilot、GitHub Copilot和Azure AI Foundry,这表明GPT-5将通过强大的生态系统触达更广泛的用户群体。所有这些改进均在Azure平台上进行训练,体现了双方在AI技术研发上的深度合作。
最后,Altman重申了OpenAI开发通用人工智能(AGI)的宏伟使命。他承认,尽管GPT-5是朝着这一目标迈出的“重要一步”,但与真正的AGI相比,它仍然“缺少一些非常重要的东西”。他认为GPT-5并非仅仅是一个模型,而是从其所发现的新事物中生长出来的“原生事物”,这正是其成为AGI“种子”的深层原因。这一观点强调了GPT-5在通往更高智能形态的演进路径中,所承载的实验性和开拓性意义。GPT-5的发布不仅是技术上的胜利,更是对未来智能时代的一次深刻预演,它促使我们重新思考人工智能的边界与潜力。








