引言:AI个性化浪潮下的隐私挑战
在当前数字化浪潮中,以Google Gemini为代表的智能助手已深度融入我们的日常生活。它们不仅是信息获取的工具,更是内容创作、工作辅助乃至情感交流的伙伴。然而,随着AI能力的飞速提升,其对个人数据的深入访问和利用方式,正成为全球用户普遍关注的焦点。近期,Google Gemini针对其数据处理策略推出了一系列重大更新,这些调整不仅预示着AI服务将以更精细、更个性化的方式与用户互动,更在悄然重塑用户对数字隐私的认知与掌控边界。本文将深入剖析这些变化,探讨AI个性化发展与用户数据主权保护之间的微妙平衡。
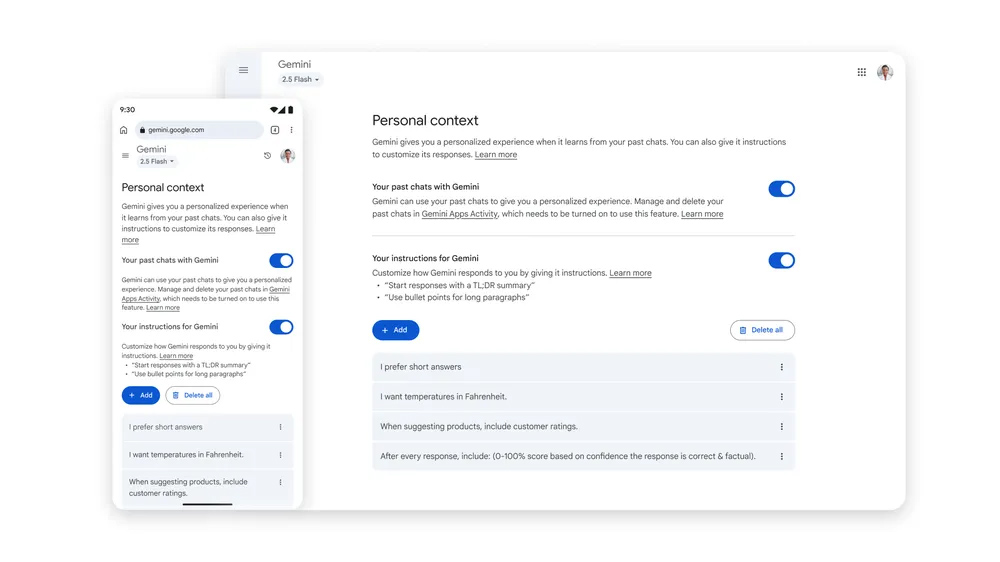
深化理解:个性化上下文(Personal Context)的运作机制
AI的个性化服务历程,从最初依赖用户明确指令和有限的搜索历史,逐步演变为更加智能、被动式的学习。Gemini此次推出的“个性化上下文”功能,正是这一演进的显著体现。与以往的定制化模式不同,该功能旨在让AI能够“记住”并整合用户在历史对话中积累的细枝末节。这意味着,即使在未被明确提示的情况下,Gemini也能依据过往的交流内容,生成更具针对性、更符合用户偏好的响应,尤其在提供建议和推荐时,其效能将得到显著提升。这与用户主动设置的“已保存指令”功能有着本质区别,后者是显式规则,而前者则是隐式的、持续性的学习过程。
然而,这种日益深化的个性化也并非毫无隐忧。当AI变得过于“善解人意”,甚至在交互中表现出近似人类的“亲近感”时,用户可能会在不知不觉中对其产生过度的信任。这种过度信任在极端情况下可能导致用户对AI生成信息的真实性辨别能力下降,进而加剧认知偏差,甚至引发业界所称的“AI幻觉”,即AI模型在缺乏事实依据的情况下生成看似合理却完全虚假的信息,而用户却深信不疑。这种现象在人机交互心理学领域已有多方探讨,提醒我们在享受AI便利的同时,也需保持一份审慎。从技术部署层面来看,“个性化上下文”功能首先应用于性能更强的Gemini 2.5 Pro模型,并且为了严格遵守各地区的数据隐私法规,欧洲联盟、英国和瑞士等地的用户暂无法使用此功能。此外,该功能还设定了18岁以上的年龄限制。这些区域性及年龄限制,反映了全球各地在数据主权和隐私保护方面存在的显著差异,也预示着AI服务在推广过程中将面临日益复杂的合规挑战。尽管如此,Google已明确表示计划将此功能逐步扩展至更高效的Gemini 2.5 Flash模型,可见其对该功能提升用户体验的战略信心。值得一提的是,用户拥有随时在主设置页面启用或禁用此功能的权限,这为用户提供了基本的控制权。

隐私堡垒:临时会话(Temporary Chats)的价值与局限
面对AI个性化趋势下日益增长的数据隐私担忧,Google适时推出了“临时会话”功能,旨在为用户提供一个类似网页浏览器“无痕模式”的私密交流空间。这项功能的核心在于其明确承诺,用户在此模式下进行的任何输入,包括文字和文件上传,都不会被用于“个性化上下文”的训练,即便该个性化设置处于启用状态。这意味着,用户可以利用“临时会话”模式,放心地探讨敏感话题,或进行一次性、不希望被AI记住的查询,从而在一定程度上保障了会话内容的私密性。
“临时会话”功能的入口设计得颇为直观便捷,通常紧邻“新建聊天”选项,使用户能够快速切换到隐私保护模式。尽管其被定义为“一次性”会话,但Google服务器仍将这些对话内容保留72小时。这一设计并非毫无道理,它旨在平衡即时隐私保护与用户在短时间内回溯会话的需求。例如,在一次临时会话中,用户可能需要短暂中断后继续讨论某个话题,72小时的保留期为这种场景提供了缓冲空间。然而,从对绝对隐私的追求角度来看,这72小时的存留依然意味着数据并非即时销毁。因此,用户在选择使用“临时会话”时,需要对Google关于“临时”的定义有清晰的认知,并结合自身对隐私保护的严格程度进行权衡。

数据利用:大模型训练的幕后与用户掌控力
除了用户端可控的个性化与隐私工具,Google还对其底层数据使用政策进行了更新,直接影响到其AI模型的训练方式。自2025年9月2日起,用户上传至Gemini的聊天内容和数据样本(包括文件上传),将开始被用于训练Google的AI模型。官方宣称此举旨在“改善Google服务”,为所有用户提供更优质、更智能的体验。
这一举措无疑引发了关于数据主权和用户选择权的深刻讨论。尽管企业声称是为了提升服务质量,但用户理应对其个人数据如何被收集、处理和利用拥有充分的知情权与决定权。令人欣慰的是,Google同时提供了明确的退出机制。用户需要在未来数周内密切关注其账户层面的隐私设置,原先的“Gemini应用活动”选项将更名为“保留活动”。用户通过禁用此设置,或持续使用上文提及的“临时会话”功能,可以阻止其数据被用于Google的模型开发。这意味着,用户必须主动采取行动来保护其数据不被用于训练AI。如果用户未能在此截止日期前进行操作,则在法律上将被视为默认同意Google使用其数据。
从更广阔的行业视角来看,这正是所有AI公司在寻求模型性能优化与用户隐私保护之间平衡时普遍面临的挑战。数据透明度在此过程中显得尤为关键。企业有责任以清晰易懂的方式告知用户其数据的使用方式、用途及生命周期,并提供便捷、有效的退出选项。与此同时,用户也需提升自身的数字素养,积极主动地了解并管理自己的隐私设置,从而在日益复杂的数字生态中有效保护自身权益。
展望未来:智能助手发展中的隐私范式
Google Gemini此次的数据策略调整,是大规模人工智能技术飞速发展背景下,隐私保护与个性化服务持续博弈的一个缩影。随着AI模型日益智能化,能够更精准地理解用户意图、预测用户需求,其对用户数据的依赖程度也将随之加深。这促使我们对未来的AI隐私范式进行深层思考,它可能呈现出以下多维度的发展趋势:
- 更精细化的隐私控制:未来AI服务或许不再局限于简单的“全部开启/全部关闭”选项。我们可能会看到更多针对特定数据类型、特定使用场景,甚至针对数据处理方式(如是否用于模型训练)的细粒度控制选项。这将赋予用户更大的数据管理自主权。
- 联邦学习与差分隐私技术的广泛应用:这些前沿技术能够在不直接访问原始用户数据的情况下对AI模型进行训练,从而在最大程度上保障用户隐私。例如,联邦学习允许模型在用户设备本地进行训练,仅上传聚合后的模型更新参数,而非原始数据。差分隐私则通过在数据中添加噪声,确保单个用户的贡献难以被识别。
- 用户数据所有权与收益共享模式的探索:未来,随着数据价值的日益凸显,可能会有更多关于用户对其个人数据拥有更明确所有权的讨论。甚至可能探索出一种机制,让用户能够从其数据被利用中获得某种形式的回报,从而激励企业在数据收集和使用上更加负责任和透明。
- 数据保护法规的持续演进与全球协同:全球各地的数据保护法规,如欧盟的《通用数据保护条例》(GDPR)和美国的《加州消费者隐私法案》(CCPA),将继续发展和完善,对AI公司的数据实践提出更高、更严苛的要求。未来可能会出现更多跨国界的数据治理框架,推动全球范围内AI隐私标准的统一与提升。
构建用户对AI的深层信任,不仅依赖于技术层面的创新,更需要透明、负责任的数据治理策略。AI助手在逐步成为我们日常生活中不可或缺的一部分时,如何确保其强大的能力不会以牺牲用户隐私为代价,是所有AI开发者、政策制定者以及普通用户必须持续面对的共同挑战。用户教育在此过程中扮演着核心角色,唯有用户充分理解并主动参与到自身的数字隐私管理中来,才能共同塑造一个既智能又安全的数字未来。