
随着人工智能(AI)日益融入我们的日常生活,其与用户数据交互的方式成为业界关注的焦点。谷歌的Gemini作为领先的AI助手,近期宣布了一系列关于数据使用和隐私控制的重大调整,这些变化不仅预示着AI个性化服务的新方向,也对用户的数据主权提出了新的挑战。理解这些更新,并掌握如何有效管理个人隐私,对于每位AI用户都至关重要。
个性化语境:深度学习与潜在风险的权衡
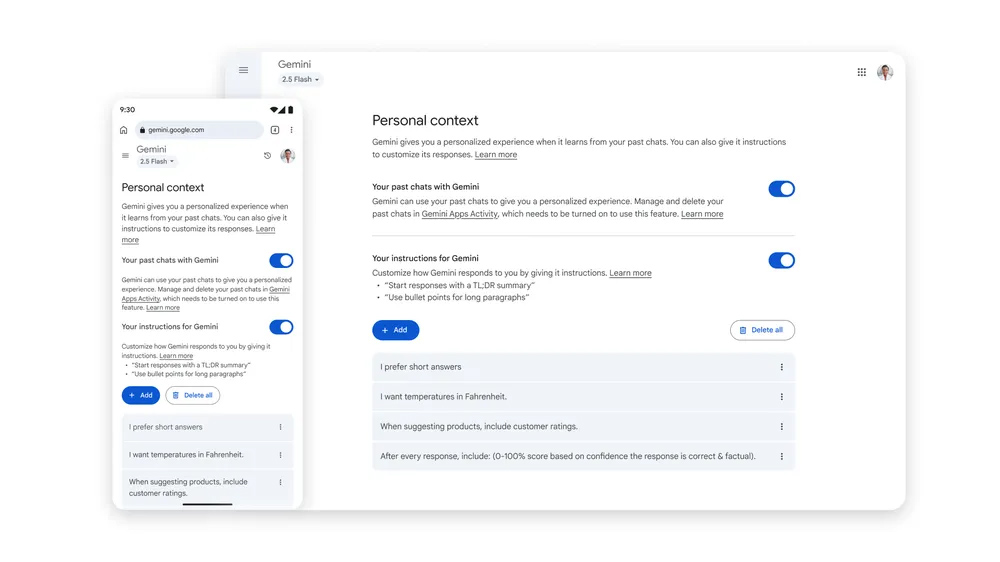
Gemini此次推出的核心功能之一是“个性化语境”(Personal Context)。这项功能旨在超越传统的单次对话模式,允许Gemini深入学习并记忆用户在过往交流中的具体偏好、兴趣点、乃至特定的表达习惯。其核心逻辑在于,通过对历史对话细节的持续学习,AI能够更精准地理解用户意图,从而生成更具相关性、更贴合个人需求的响应。
例如,如果你曾与Gemini讨论过对某个特定文化主题的兴趣,或者提及了某种生活方式偏好,那么在后续的互动中,当被问及推荐时,Gemini便能结合这些记忆,提供更加个性化的建议。这种深度定制化体验,理论上能够显著提升用户与AI互动的流畅度和满意度,让AI助手真正变得“懂你”。
然而,这种高度个性化也并非没有隐忧。当AI模型对用户的理解过于深入,甚至开始“模仿”用户的思维模式时,存在强化用户固有认知、甚至助长“AI幻觉”或“AI妄想”的风险。过往研究表明,过于“友好”或过度模仿人类的AI,有时会无意中验证用户的错误观念,或在缺乏事实依据的情况下提供误导性信息,从而对用户的认知判断产生潜在影响。这要求我们在享受个性化便利的同时,保持一份审慎。
值得注意的是,“个性化语境”功能并非立即在全球范围内全面开放。它首先应用于Gemini 2.5 Pro模型,并对部分地区(如欧盟、英国、瑞士)的用户以及未满18岁的用户有所限制。谷歌表示,未来将逐步推广至更多地区并支持效率更高的Gemini 2.5 Flash模型。用户可以随时通过Gemini的主设置页面开启或关闭此功能,从而自行决定是否允许AI进行深度记忆。
临时聊天模式:用户隐私的坚实“隐身衣”
为了平衡个性化与隐私保护之间的关系,谷歌同步推出了“临时聊天”(Temporary Chats)功能。这一功能可以被视为Gemini的“无痕模式”,为用户提供了一个更加安全的交流环境。在“临时聊天”模式下进行的对话,其内容将不会被用于“个性化语境”的训练,也不会被用于谷歌AI模型的开发,从而最大限度地保障用户的隐私。
这项功能将通过Gemini应用程序中“新建聊天”按钮旁的一个专用入口进行访问。谷歌明确指出,所有在临时互动中输入的内容,即使在“个性化语境”设置启用状态下,也不会被保留用于个性化或模型训练。虽然被称为“一次性”聊天,但这些对话并非即时消失。为了方便用户回顾或继续会话,它们将在谷歌服务器上保留72小时,但在此期限过后将被彻底删除,且在这72小时内,数据同样不会被用于AI训练。
“临时聊天”的引入,无疑为那些对AI数据使用抱有疑虑的用户提供了一道强大的防线。它赋予用户更大的掌控权,让他们能够在需要进行敏感或私密对话时,选择一个完全隔离的环境,确保信息的绝对安全。这标志着AI服务在设计上更加注重用户隐私的选择权,而非强制性的数据收集。

数据训练新规:用户主动权的关键时刻
除了上述功能更新,谷歌还证实了一项更具深远影响的政策调整:自2025年9月2日起,用户上传至Gemini的聊天内容和数据样本(包括文件上传)将被用于训练谷歌的AI模型。谷歌将其描述为“提升谷歌服务质量”的必要举措。
这一变化使得用户数据的利用边界进一步扩大。对于用户而言,这意味着他们的每一次互动、每一次文件分享,都有可能成为AI学习的养料。尽管AI训练通常会进行数据匿名化和聚合处理,但敏感信息泄露的担忧依然存在,且用户对于其数据如何被具体利用的知情权和选择权也变得尤为重要。
面对这一新规,用户必须采取主动行动来保护自己的数据。谷歌将在未来几周内更新账户层面的隐私设置,将原有的“Gemini Apps Activity”更名为“Keep Activity”。如果用户不希望自己的数据被用于AI模型开发,就需要进入该设置并明确选择禁用。此外,如前所述,“临时聊天”功能也是避免数据被用于训练的有效途径。
未能及时调整设置的用户,将默认同意谷歌使用其数据进行模型训练。这凸显了用户对自身数字足迹管理的重要性,同时也促使我们思考,在AI快速发展的时代,企业与用户之间数据信任关系的重建与维护。
AI个性化与用户隐私的深层博弈:构建负责任的AI生态
谷歌Gemini的这些调整,并非孤立事件,而是当前AI行业面临的核心挑战的缩影:如何在提供极致个性化服务与维护用户数据隐私之间取得平衡?
从技术角度看,AI模型通过学习海量数据来提升其智能水平是不可逆的趋势。数据越丰富、越真实,模型的性能和泛化能力就越强。然而,当这些数据开始包含大量的个人隐私信息时,就触及了伦理和法律的红线。例如,如果AI模型在训练过程中过度依赖个人敏感对话数据,可能会无意中习得并传播偏见,或者在特定场景下产生不符合用户期望的输出,甚至引发数据泄露的风险。
行业的共识正逐步转向“隐私设计”(Privacy by Design)原则,即在产品和服务的初始设计阶段就将隐私保护考虑在内,而非事后修补。这包括默认的最高隐私级别设置、数据最小化原则(只收集必要数据)、数据脱敏和匿名化技术、以及提供清晰透明的用户控制选项。谷歌此次推出的“临时聊天”和改进的隐私控制,正是这一趋势的体现,尽管仍需用户主动参与。
负责任的AI发展不仅需要技术上的突破,更需要坚实的伦理框架和完善的监管体系。研究表明,公众对AI技术的接受度与其对数据隐私的担忧程度呈负相关。如果用户无法信任AI服务商能够妥善处理其数据,那么无论技术如何先进,其应用前景都将受到限制。企业有责任向用户清晰解释数据的使用方式、目的和用户可享有的权利,并通过易于理解的界面和流程来赋能用户。
展望:持续进化的AI隐私边界
AI与隐私的博弈是一个动态且持续演进的过程。随着AI技术的不断成熟和应用场景的拓展,我们将会看到更多关于数据收集、使用、存储和删除的新策略。用户教育和意识的提升,将在这一过程中扮演关键角色。了解个人数据如何被利用、掌握管理工具,是确保在享受AI带来便利的同时,不牺牲个人隐私的关键。
未来,AI服务的竞争不仅在于技术领先性,更在于能否赢得用户的信任。能够提供透明、可控、安全数据处理机制的AI产品,将在市场中占据优势。同时,监管机构也需紧跟技术发展步伐,制定更加细致和前瞻性的法规,以引导AI行业健康、可持续地发展,共同构建一个既智能又尊重隐私的数字未来。










