
人工智能前沿:2025年模型与应用革新的深层洞察
当前,人工智能技术正以惊人的速度演进,不断刷新我们对计算能力与智能应用的认知边界。从轻量级模型在移动设备上的突破,到多模态能力在复杂场景中的深度融合,再到AI工具链对传统工作流的重塑,每一个进展都预示着一个更加智能化的未来。本报告将深入剖析近期AI领域一系列里程碑式的发布与趋势,揭示其背后的技术逻辑与产业影响。
赋能移动与边缘计算的轻量级模型突破
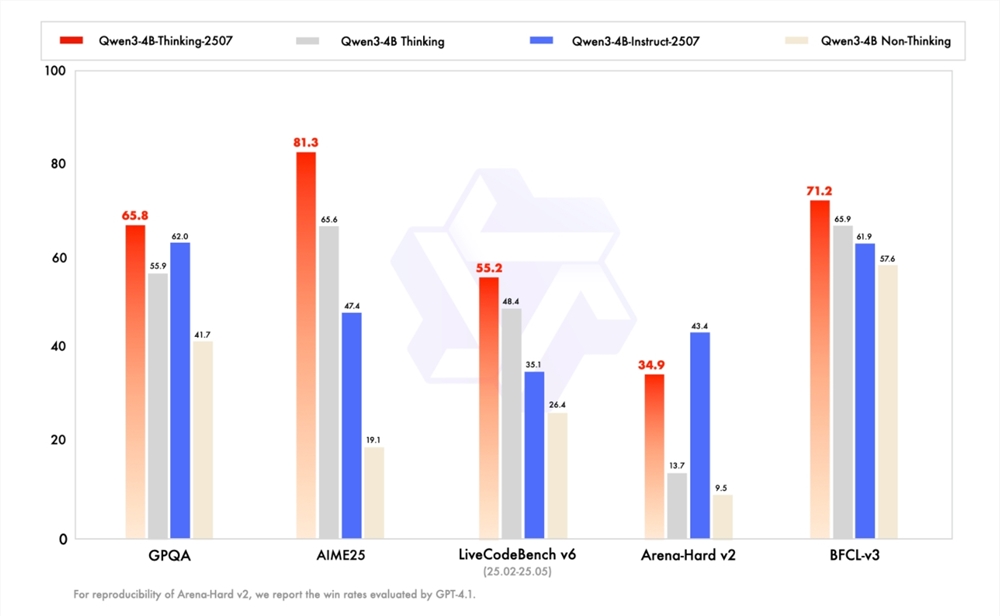
1. 阿里云Qwen3-4B系列:小巧机身蕴藏大智慧
阿里巴巴通义千问团队最新发布的Qwen3-4B系列模型,是微型语言模型领域的重大突破。该系列模型在保持小体积的同时,展现出卓越的性能,为移动端AI应用开辟了新的路径。其核心优势在于对性能与资源利用的精妙平衡,使其能够在资源受限的移动设备上高效运行,极大拓宽了AI的普及面。例如,Qwen3-4B-Instruct-2507版本甚至超越了部分闭源小型模型,其表现已接近于大规模模型Qwen3-30B-A3B的能力水平,这无疑是小型模型开发的一个重要里程碑。此外,Qwen3-4B-Thinking-2507在数学推理等评测中取得的高分,进一步证明了其强大的逻辑推理潜力,这对于在智能手机等终端设备上部署复杂AI应用具有重要意义。
2. MiniCPM-V4.0:手机上的多模态GPT-4V
MiniCPM-V4.0的开源发布,再次验证了轻量级模型在多模态领域的巨大潜力。这款仅4.1B参数量的模型,基于SigLIP2-400M和MiniCPM4-3B构建,却能展现出令人印象深刻的图像、视频理解和多轮对话能力。其在移动设备上的实测表现尤其引人注目,例如在iPhone16Pro Max上,首次响应延迟不到2秒,解码速度超过每秒17个Token,这使得高并发的多模态交互在手机端成为可能。MiniCPM-V4.0的强大之处不仅在于其效率,更在于其提供了丰富的生态支持,兼容主流框架,并提供详细教程与iOS应用,显著降低了开发者在移动端部署多模态AI的门槛。这预示着,未来个人智能助理将能够更深度地理解用户周边的视觉信息,提供更加个性化和场景化的服务。
多模态AI的深度融合与创新应用
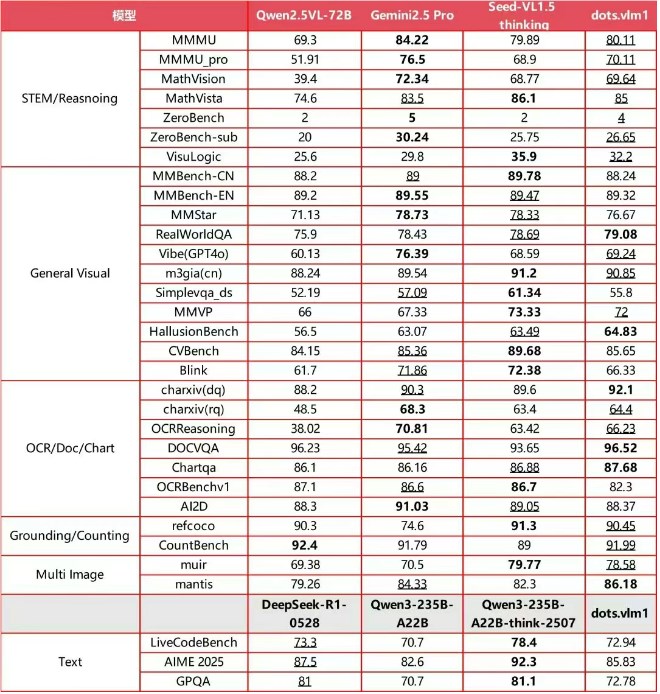
1. 小红书dots.vlm1:开源多模态大模型的新标杆
小红书Hi Lab推出的开源多模态大模型dots.vlm1,凭借其原生自研的NaViT视觉编码器和基于DeepSeek V3大语言模型,将开源多模态技术推向了新高度。NaViT视觉编码器支持动态分辨率,显著提升了模型的泛化能力,使其在处理多样化的视觉信息时表现更为出色。该模型通过构建大规模、清洗精细的训练集,极大地提升了图文对齐的质量,使其在图表推理、STEM数学推理等复杂任务中表现卓越。评测数据显示,dots.vlm1的性能已接近闭源的Gemini2.5Pro和Seed-VL1.5等领先模型,这对于推动多模态AI研究的开放性和创新具有里程碑意义。其在复杂视觉信息理解上的优势,有望在内容理解、智能辅助创作等领域发挥关键作用。
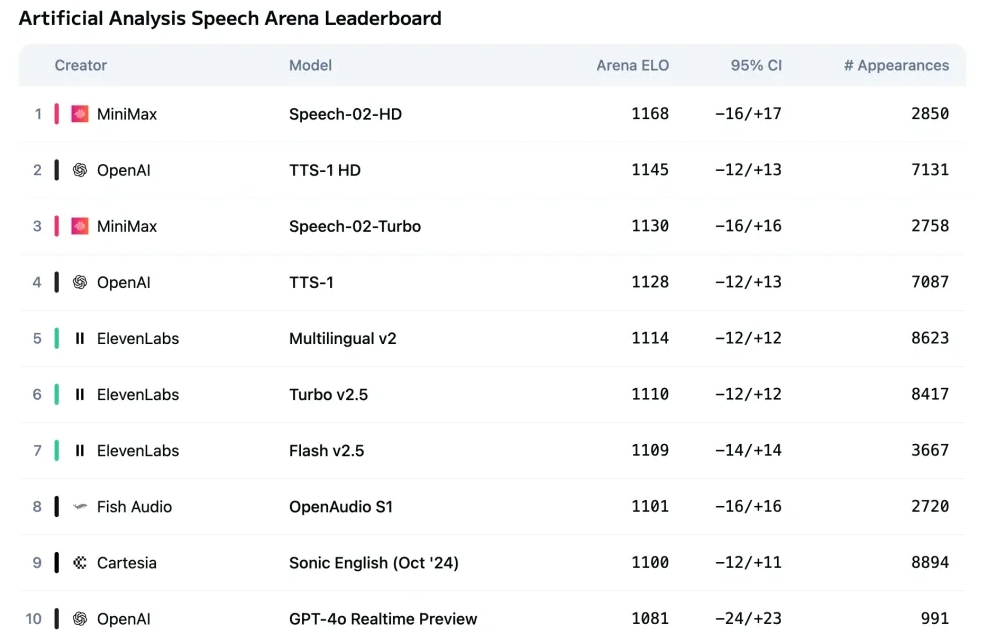
2. MiniMax Speech 2.5:多语种语音生成的新境界
MiniMax发布的Speech 2.5语音生成模型,在多语种表现力、音色复刻精度和语种覆盖范围上实现了显著飞跃。该模型不仅在中文语音生成方面保持了全球领先水平,同时在英文及其他多达40种语言的表现力方面也得到全面提升。其音色复刻技术达到了行业顶级精度,能够细致保留不同地区的口音特色,这为全球化内容创作和跨文化交流提供了前所未有的便利。Speech 2.5通过深度学习与声学建模的创新,使得合成语音的自然度、情感表达和语境适应性达到了新高度,为教育、娱乐、客户服务等多个行业带来了革新机会。这项技术有望让AI的语音交互体验更加逼真和个性化。
AI工具链的智能化升级与效率提升
1. Midjourney HD视频模式:专业影像创作的新利器
Midjourney推出的HD视频模式,是其在AI视频生成领域迈出的重要一步,专为专业用户提供更高清、更高质量的视频生成能力。虽然其成本相较SD模式有所增加,但分辨率和清晰度的显著提升,满足了专业级影像制作对视觉效果的严苛要求。这一功能的发布,进一步巩固了Midjourney在AI视频生成市场的竞争力,并与其他领先模型如OpenAI的Sora和Runway的Gen-4展开激烈竞争。它标志着AI视频技术正从概念走向实用,为电影制作、广告创意、虚拟现实等领域提供了强大的新工具。
2. Cursor 1.4:加速大型代码库自动化进程
Cursor 1.4版本的发布,标志着AI驱动开发工具在处理复杂任务方面的又一领先。该版本显著增强了异步和长程任务的处理能力,优化了大型代码库的索引与搜索功能,从而极大提升了代码补全和查询效率。Cursor 1.4的核心亮点在于推动AI编码工具向全自动化的转型,通过增强Agent的自主性和协作功能,使得AI能够更有效地参与到软件开发的整个生命周期中。例如,其后台Agent运行和任务队列管理能力,使得开发者可以将更多的重复性、耗时性任务交给AI完成,从而将精力集中在更高层次的系统设计与创新上。这预示着未来代码协作将更加高效,AI将成为开发团队不可或缺的智能伙伴。

3. 腾讯WeKnora:复杂文档智能解析的突破
腾讯开源的WeKnora是一款基于大语言模型的文档理解与检索工具,其创新之处在于能够高效处理多模态文档,并提供结构化内容提取和智能交互功能。WeKnora支持从PDF、Word、图片等多种格式中精准提取信息,并基于大语言模型实现多轮对话和自然语言查询,极大地提升了知识管理的效率和智能化水平。其模块化架构设计,使得WeKnora能够灵活配置和扩展,以适应不同行业的特定需求。该工具的出现,有望彻底改变企业和个人处理海量非结构化文档的方式,让信息检索不再依赖关键词匹配,而是基于深层语义理解,这对于法律、金融、医疗等行业的大规模知识管理具有颠覆性意义。
4. FlowSpeech:书面语转口语的创新TTS
FlowSpeech作为一款突破性的AI文本转语音(TTS)工具,专注于将书面文字转化为自然流畅的口语表达。与传统TTS工具不同,FlowSpeech通过上下文感知和多模态支持技术,有效解决了语调变化不自然、情感表达不足等问题,为用户提供了更贴近真实对话的语音体验。其智能内容筛选功能,能够自动识别并剪裁不适合朗读的内容,进一步提升语音质量。FlowSpeech的开发团队计划推出个性化声音定制服务,这将极大拓展其在有声读物、播客、在线教育和虚拟主播等领域的应用边界,使得AI生成的语音内容更具感染力与个性。
行业生态与未来展望
1. AMD、高通宣布支持gpt-oss系列开放模型:边缘计算的新纪元
AMD与高通联合宣布支持OpenAI的gpt-oss系列模型,标志着边缘计算与AI结合的重大进展。AMD的锐龙AI Max+395处理器成为全球首款能够运行gpt-oss-120b的消费级AI PC处理器,这预示着高性能AI推理能力将逐步下沉到个人电脑终端。同时,高通骁龙平台也展示了gpt-oss-20b的出色推理能力,为移动设备上的复杂AI应用提供了强大支持。两大芯片巨头的举动,将极大加速AI模型在本地设备上的部署和普及,降低对云端计算的依赖,提升数据隐私和处理效率,开启了真正的AI PC和智能手机时代。
2. 谷歌AI搜索功能对网站流量的影响:数据与争议
谷歌近期反驳了关于其AI搜索功能对网站流量造成冲击的指控,声称自然点击量保持稳定且点击质量有所提升。然而,第三方数据显示,零点击搜索的比例显著增加,这反映出用户行为模式正在发生深层转变。尽管谷歌强调点击质量提高,但缺乏具体数据支持其结论,使得这一争议依然存在。同时,用户趋势转向Reddit和TikTok等其他平台寻求信息,也在一定程度上影响了传统搜索引擎的流量。这一现象促使我们重新审视搜索引擎在信息获取中的角色演变,以及内容创作者在AI时代下的应对策略。

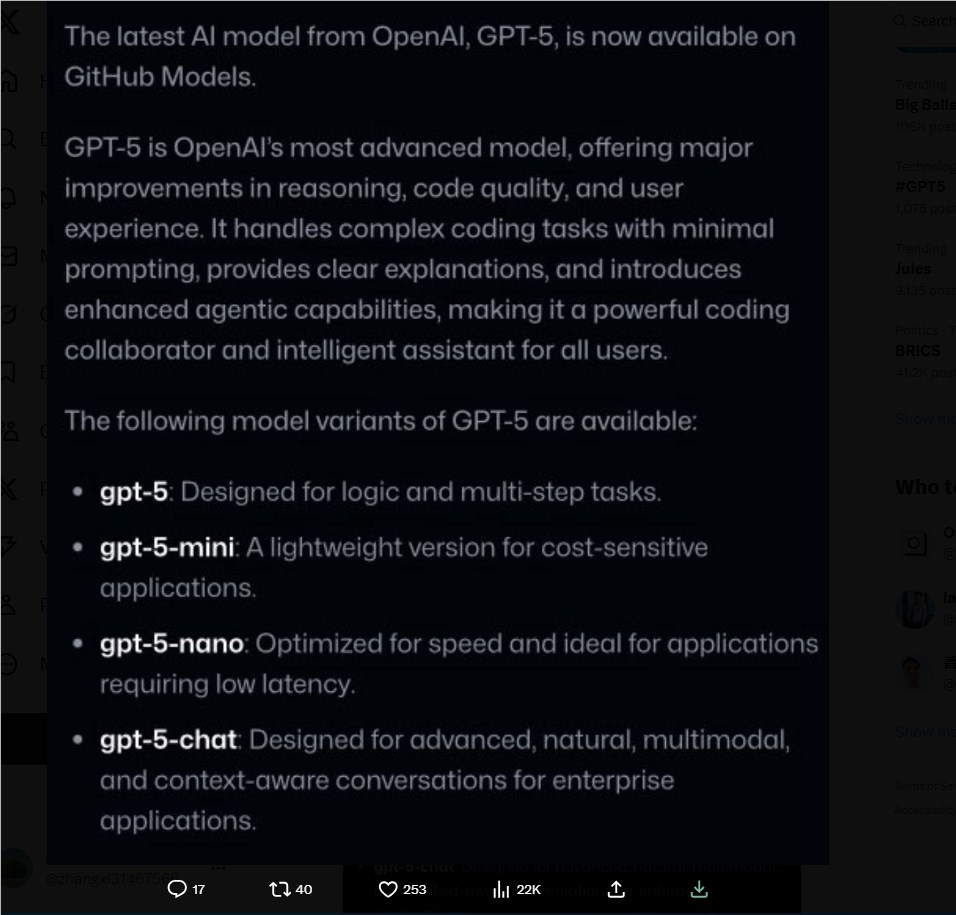
3. OpenAI旗舰模型GPT-5详细信息疑似泄露:未来的展望
在全球科技界翘首以盼OpenAI即将发布的GPT-5之际,一份疑似该模型的详细说明信息在GitHub上意外曝光,引发了广泛关注。泄露信息将GPT-5描述为OpenAI迄今最先进的大语言模型,具备更为强大的推理能力和代码质量。据称,GPT-5将推出多个版本,以满足不同用户和场景的特定需求。尽管泄露信息的真实性尚待官方确认,但这一事件无疑激发了开发者对GPT-5技术细节的强烈期待。如果内容属实,GPT-5的发布将有望在通用人工智能领域再次树立新的里程碑,并在代码生成、复杂问题解决、逻辑推理等多个维度带来质的飞跃。
总结与展望
2025年的AI领域,无疑是充满活力与变革的一年。从轻量级模型的普及,到多模态能力的深化,再到AI工具链的全面智能化,技术创新正以前所未有的速度推动着产业的进步。无论是赋能移动设备的边缘AI,还是提升生产力的智能开发工具,亦或是革新信息交互模式的生成式AI,都展现出巨大的应用潜力。尽管AI发展面临诸多挑战,如数据隐私、模型偏见以及技术伦理等,但持续的开源协作与跨界融合将是推动AI走向更广泛应用的关键。未来,我们期待AI技术能够更加深入地融入人类社会,以更负责任、更具包容性的方式,为全球带来新的发展机遇和智慧解决方案。










