
随着人工智能技术的飞速发展,大型语言模型(LLMs)和多模态模型(VLMs)已在文本生成、图像识别等领域展现出惊人的能力。然而,在面对需要跨越不同模态、进行复杂逻辑推理与深度信息整合的研究任务时,现有系统仍面临显著瓶颈。传统的纯文本AI模型难以有效处理现实世界中丰富的图像、图表和视频内容,而专注于视觉的AI系统则往往缺乏进行多工具协作与高阶推理的能力。为了填补这一空白,阿里巴巴自然语言处理团队开创性地推出了WebWatcher,一款开源的多模态深度研究智能体,旨在赋予AI系统像人类专家一样进行复杂、综合性研究的能力。
WebWatcher的核心创新与设计理念
WebWatcher的诞生,正是为了解决当前AI智能体在多模态深度研究领域的两大核心挑战:首先是闭源系统(如OpenAI的DeepResearch)虽在文本研究方面表现突出,却普遍受限于纯文本环境,难以应对图像、图表等视觉信息;其次是现有开源Agent的局限性,它们或是侧重文本检索但无法处理图像,或是具备视觉识别能力却缺乏跨模态推理和多工具协同作业的机制。WebWatcher通过整合网页浏览、图像搜索、代码解释器和内部OCR(光学字符识别)等多维度工具,构建了一个强大的认知框架,使其能够处理复杂的视觉理解、逻辑推理、知识调用、工具调度及自我验证任务。
WebWatcher的设计理念,强调了在高难度多模态深度研究任务中实现AI智能体的灵活推理与多工具协作能力。为此,研究团队构建了一套精巧且高效的技术方案,涵盖从高质量数据构建到训练优化的完整链路。
全自动多模态数据生成流程
高质量的训练数据是任何AI模型成功的基石,尤其对于需要复杂推理和多工具交互的多模态Agent而言,其重要性不言而喻。WebWatcher采用了创新的全自动多模态数据生成流程,这不仅大大降低了数据标注成本,更保证了数据的多样性和复杂性:
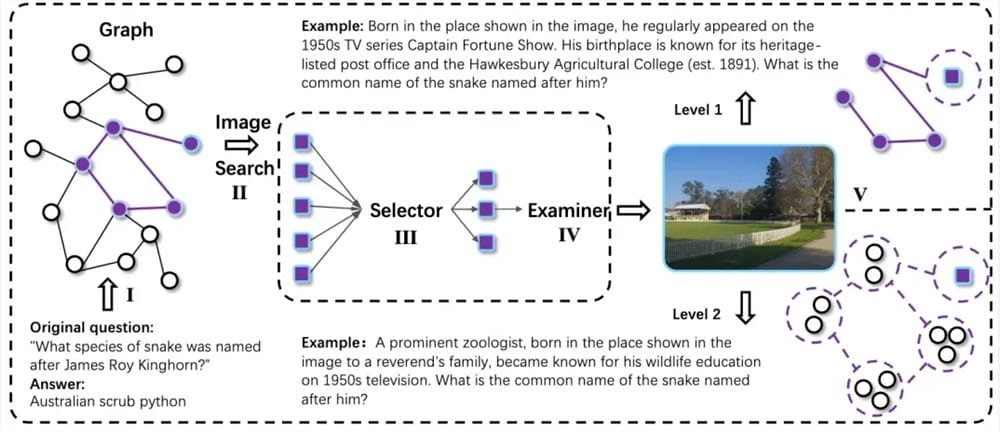
- 随机游走构建跨模态知识链:该机制模拟人类研究员在探索未知领域时,通过关联不同来源(文本、图像、代码等)的信息,逐步构建起完整的知识图谱。系统通过在知识图谱上进行随机游走,生成包含多模态元素的复杂问题链条,确保每个问题都能够触发跨模态的推理和信息整合。
- 信息模糊化技术引入不确定性:为了提升任务的真实性和挑战性,数据生成过程中引入了信息模糊化技术。这意味着生成的某些信息可能不完全明确或存在歧义,迫使智能体在推理时考虑多种可能性,并学会处理不确定性,这在现实世界的研究中至关重要。
- QA-to-VQA转换模块:此模块能够将传统的文本问答(QA)样本扩展为多模态视觉问答(VQA)版本。例如,一个关于数据分析的问题,可以被转换为需要结合图表或图像才能得出答案的VQA问题,从而强制模型进行跨模态理解和信息融合,极大地增强了模型的泛化能力和鲁棒性。
高质量推理轨迹构建与后训练策略
除了数据创新,WebWatcher在模型训练方面也采取了分阶段、渐进式的策略,确保模型能够有效掌握多模态推理和工具调用的复杂技能。
- Action-Observation驱动的轨迹生成:通过收集真实的多工具交互轨迹,模型能够学习到在不同情境下如何选择和使用工具,以及如何根据工具的输出(观察结果)来调整后续行动。这类似于人类在执行任务时,通过实践和反馈来优化其操作流程。
- 监督微调(SFT):在训练初期,模型通过对这些高质量交互轨迹进行监督微调,快速掌握ReAct(Reasoning and Acting)式推理和工具调用的基本模式。ReAct框架使得模型能够通过内部思考(Reasoning)来规划行动,并通过执行行动(Acting)来获取外部信息,从而形成闭环推理。
- 强化学习(GRPO):在SFT阶段奠定基础后,模型进入强化学习阶段,采用GRPO(Generalized Policy Optimization for Reinforcement Learning,广义策略优化)算法进一步提升多模态Agent在复杂环境下的决策能力。GRPO有助于模型在面对长期目标和稀疏奖励的任务时,优化其策略,从而在多步、多工具的复杂推理任务中表现出更强的探索和优化能力。这使得WebWatcher在面对不确定性和需长期规划的问题时,能够做出更明智的决策。
WebWatcher的卓越性能与行业影响
为了全面、客观地评估WebWatcher的性能,研究团队提出了BrowseComp-VL,这是现有BrowseComp基准在视觉-语言任务上的扩展版本。该基准旨在最大程度地逼近人类专家在进行跨模态研究任务时的难度和复杂性,通过多轮严格评测,全面验证了WebWatcher在复杂推理、信息检索、知识整合以及聚合类信息寻优等核心能力。
实测结果令人印象深刻:
- 人类终极考试(Humanity’s Last Exam, HLE-VL):这是一个衡量多步复杂推理能力的基准。WebWatcher以13.6%的Pass@1分数一举夺魁,远超GPT-4o(9.8%)、Gemini2.5-flash(9.2%)和Qwen2.5-VL-72B(8.6%)等代表性多模态大模型。这表明WebWatcher在执行需要多步骤、多维度推理的复杂任务时,具有显著的优势。
- MMSearch评测:在更贴近真实多模态搜索场景的MMSearch评测中,WebWatcher的Pass@1得分高达55.3%,大幅领先于Gemini2.5-flash(43.9%)和GPT-4o(24.1%)。这一结果凸显了WebWatcher在快速准确地从海量多模态数据中检索和整合关键信息方面的卓越效率。
- LiveVQA评测:在LiveVQA评测中,WebWatcher的Pass@1成绩达到58.7%,同样领先于其他主流模型。这进一步证明了其在实时视觉问答任务中的强大能力,能够精准理解图像内容并结合上下文进行回答。
- BrowseComp-VL综合基准:在最具综合挑战性的BrowseComp-VL基准上,WebWatcher以27.0%的平均得分(Pass@1)遥遥领先,成绩提升超过一倍。这充分验证了WebWatcher在处理复杂视觉-语言任务中的全面领先性,其在多模态感知、逻辑推理和工具协同方面的综合能力达到了前所未有的高度。
WebWatcher的开源不仅为全球研究者提供了一个强大的多模态深度研究工具,更促进了相关技术的透明度和创新。它的出现,预示着AI智能体将能够更深入地参与到人类的知识发现和创造过程中,为科学研究、数据分析、市场洞察等领域带来革命性的变革。未来,随着多模态AI技术的持续演进,我们有理由期待WebWatcher及其衍生技术,将在构建更智能、更自主的通用人工智能(AGI)方面发挥关键作用,开启一个全新的智能研究纪元。










