
大型语言模型“模拟推理”的本质与泛化困境
近年来,大型语言模型(LLMs)凭借其在自然语言处理领域的卓越表现,引发了广泛关注。特别是在引入“链式思考”(Chain-of-Thought, CoT)推理范式后,LLMs似乎能够通过多步骤的逻辑推导来解决复杂问题,这使得许多人对通用人工智能(AGI)的实现充满了期待。CoT通过引导模型逐步思考,模仿了人类解决问题的过程,从而在各种基准测试中取得了令人印象深刻的成果。然而,伴随这种进步而来的是日益增长的质疑声:LLMs的“推理”能力究竟是真正的逻辑理解,还是仅仅是其训练数据中模式的复杂再现?
近期多项研究,包括一项来自亚利桑那州立大学的预印本论文,对LLMs的“模拟推理”能力提出了尖锐挑战。这些研究指出,LLMs并非真正的原则性推理器,而更像是“推理式文本的复杂模拟器”。这意味着,尽管它们能够生成看似逻辑严谨的推理步骤,但这可能仅仅是对训练数据中存在模式的复制与重组,而非基于深层逻辑概念的理解。当模型面临其训练数据中未曾出现的“域外”(out of domain)逻辑问题时,其性能会“显著退化”,暴露出“脆弱的幻象”。这种现象迫使我们重新审视,我们对LLMs智能本质的认知是否过于乐观。
链式思考的“脆弱幻象”:机制与实验证据
为了客观衡量LLM的泛化推理能力,亚利桑那州立大学的研究团队构建了一个名为DataAlchemy的受控LLM训练环境。这个实验平台旨在通过高度简化的文本转换任务,精确地评估模型在面对训练数据之外的逻辑组合时,表现出的推理能力。研究人员训练了小型模型,使其掌握两种基础的文本转换功能:ROT密码(一种简单的字母替换密码)和循环移位(将字符串中的字符按顺序移动)。随后,模型会接受额外的训练,学习这两种功能以不同顺序和组合进行执行的示例。
例如,模型可能被训练识别“先ROT再移位”或“先移位再ROT”的模式。这些简化的、可量化的任务,避免了真实世界语言的复杂性,使得研究人员能够清晰地追踪模型在处理逻辑转换时的行为。关键在于,DataAlchemy允许研究人员创造性地生成测试用例,这些用例在任务类型、格式和长度上都可能“超出”模型的训练数据分布。例如,一个模型可能只见过两次循环移位的组合,但却被要求执行两次ROT移位,尽管它只接受过单个ROT移位的基本训练。
实验结果令人深思。这些基础模型在被要求泛化到训练数据中未直接演示过的新颖转换组合时,性能“灾难性地失败”。研究发现,尽管模型会尝试根据训练数据中的相似模式来泛化新的逻辑规则,但这常常导致模型“呈现出正确的推理路径,但答案却是错误的”。这种情况表明,模型在生成推理过程的文本上表现出色,但其底层的逻辑推导却未能导向正确的结果。更令人担忧的是,在某些情况下,LLM甚至可能“偶然”得出正确答案,但其“推理路径却是不可靠的”,即推理步骤本身不符合逻辑。这进一步证明了模型并非真正理解问题,而是在进行某种形式的“表面模式匹配”。
 图片:这幅拼图与机器人之前看到的有多大程度的相似?
图片:这幅拼图与机器人之前看到的有多大程度的相似?
研究人员还进一步测试了模型在输入文本字符串长度或所需功能链长度发生微小变化时的表现。结果显示,随着“长度差异的增加,结果的准确性会随之下降”,这“预示着模型泛化能力的失败”。此外,测试任务格式中哪怕是模型不熟悉的细微差异(例如引入训练数据中未出现的字母或符号),也会导致模型性能“急剧下降”,并“影响模型响应的正确性”。这些发现共同指向一个结论:“链式思考在任务转换下的推理,似乎反映了训练期间所学模式的复制,而非对文本的真正理解。”
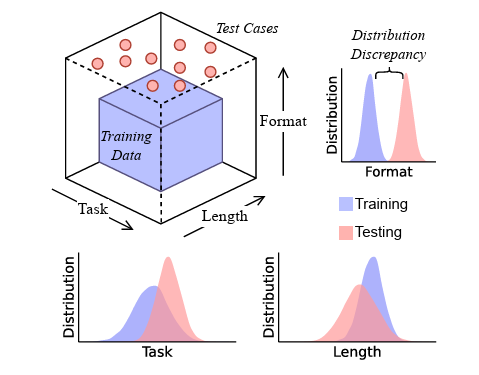 图片:研究人员使用的测试用例在任务类型、格式和长度上都超出了LLM的训练数据。
图片:研究人员使用的测试用例在任务类型、格式和长度上都超出了LLM的训练数据。
“虚假的可靠光环”:对现实世界应用的警示
这项研究的深层意义在于,它揭示了当前LLMs在处理超出其训练数据分布的复杂逻辑任务时的内在局限性。尽管通过监督式微调(SFT)引入少量相关数据可以在一定程度上提升模型在“域外”任务上的表现,但研究人员明确指出,这种“修补”方法“不应被误认为是实现了真正的泛化……依赖SFT来修复每一次‘域外’故障是一种不可持续的、被动的策略,未能解决核心问题:模型缺乏抽象推理能力。”
本质上,这些链式思考模型被描述为一种“复杂的结构化模式匹配形式”,当被轻微推离其训练分布时,其性能会“显著退化”。更具误导性的是,这些模型生成“流利的无稽之谈”的能力,创造出一种“虚假的可靠光环”,这种光环在仔细审查下根本站不住脚。
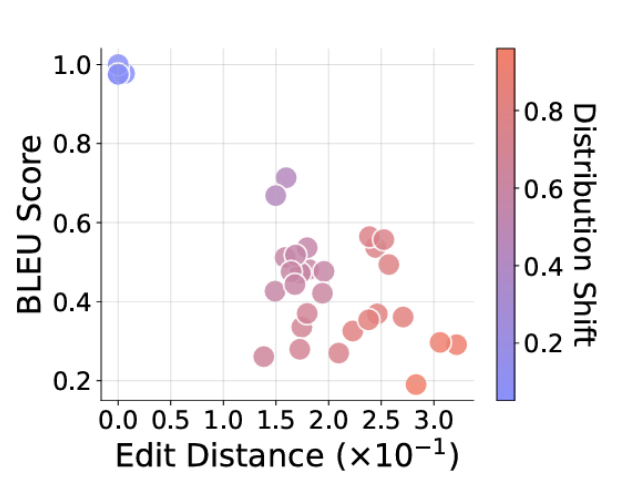 图片:随着请求的任务越来越超出训练分布(红色越深),提供的答案与预期答案的偏差也越大(图表右下角)。
图片:随着请求的任务越来越超出训练分布(红色越深),提供的答案与预期答案的偏差也越大(图表右下角)。
这种“虚假的可靠光环”在高风险领域尤其危险。例如,在医学诊断中,如果模型基于表面模式识别而非深层病理逻辑给出建议,可能会导致误诊;在金融分析中,对市场趋势的错误“推理”可能造成巨大经济损失;在法律咨询中,未能真正理解法律条文的细微差异,可能引发严重后果。LLMs虽然在海量数据中学习到了丰富的语言模式,但它们尚未能完全掌握人类所具备的、从具体实例中提取抽象原则并应用于全新情境的泛化推理能力。目前的LLMs更像是高级的模仿者,而非真正的思考者。
展望未来:超越模式识别,迈向深层推理
研究人员因此强烈警告,不要将“链式思考”式的输出等同于人类思维,尤其是在医学、金融或法律分析等高风险领域。这并非否定LLMs的价值,而是呼吁对其能力边界有更清晰的认知。
未来的研究和模型开发需要将重点从“表面模式识别”转向“展现更深层次的推断能力”。这可能需要新的模型架构、训练范式,甚至是结合符号逻辑与神经网络优势的混合方法。例如,可以探索如何让模型不仅学习到数据中的统计关联,更能理解这些关联背后的因果关系和抽象原则。这或许意味着在训练数据中引入更多结构化的、明确的逻辑知识,或者开发能够自我纠正、自我反思的元学习机制。
此外,当前的测试和基准应优先考虑那些“超出任何训练集”的任务,以探测这些模型固有的局限性。我们需要设计更具挑战性的评估体系,这些体系能够真正衡量模型的泛化能力和鲁棒性,而不仅仅是其在熟悉任务上的表现。这将帮助我们区分真正的理解与仅仅是复杂的模式复制,从而引导AI技术向更负责任、更可靠的方向发展。
总而言之,大型语言模型在模拟推理方面取得了显著进展,但其泛化能力仍然受限。我们必须清醒地认识到这些模型的本质和局限性,避免过度神化其“智能”。只有通过持续的深入研究和严谨的评估,我们才能逐步构建出真正具备抽象推理能力和广泛泛化能力的人工智能系统,使其在关键应用领域中真正发挥其潜力,而非仅仅提供“流利的无稽之谈”。










