
在当今技术飞速发展的时代,人工智能领域正以惊人的速度演进,不断刷新我们对智能边界的认知。近期,一系列重磅级技术突破与产品更新集中涌现,从多模态大模型的创新应用到机器人操作系统的革新,再到代码理解与图像生成的前沿进展,无不彰显着AI技术深度融合与广泛落地的趋势。这些进展不仅预示着未来科技的走向,也为各行各业的智能化转型提供了强大动力。
多模态AI的创新里程碑
小米MiDashengLM-7B:音频理解的新标杆
小米近日隆重发布并全面开源了其MiDashengLM-7B多模态大模型,这无疑是音频理解领域的一次重大突破。该模型在性能与效率两方面均取得了革命性进展,成功在22个公开评测集上拔得头筹,彰显了其卓越的理解能力。更令人瞩目的是,MiDashengLM-7B在推理效率上表现惊人,其单样本首Token延迟仅为业界领先模型的四分之一,数据吞吐效率更是提升了20倍以上。这得益于其独特的双核心架构设计,巧妙融合了专业的音频处理与高级语言理解能力。通过这一创新架构,MiDashengLM-7B不仅能够统一理解语音、环境声音和音乐,显著提升了跨域音频识别的精度,还因其高效的推理能力,使得终端离线部署成为可能,从而大幅降低了用户的使用成本。这一模型有望在智能语音助手、智能家居以及音频内容分析等多个场景中发挥关键作用,极大地丰富人机交互的体验。

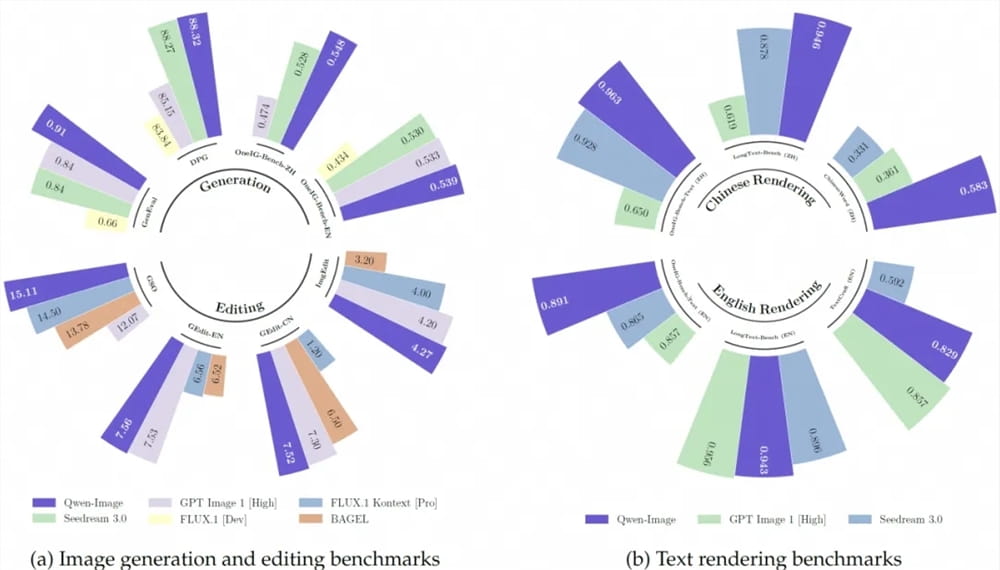
阿里通义千问Qwen-Image:文生图的艺术与效率
阿里巴巴通义千问团队再次发力,开源了全新的文生图模型Qwen-Image,这标志着图像生成与编辑技术迈入了全新的阶段。Qwen-Image在文本渲染和图像编辑方面的表现尤为出色,并在多项基准测试中展现出领先的性能优势。该模型的核心亮点在于其强大的多行布局处理能力、段落级文本生成精度,以及对细粒度细节的精准呈现。例如,它能高度还原宫崎骏风格的动漫场景,甚至能精确生成具有中文书法艺术美感的对联,这在现有模型中是极其罕见的突破。在图像编辑方面,Qwen-Image展现出多样的能力,包括风格迁移、物体增减和细节增强等,使得普通用户也能够轻松实现专业级的图像处理效果。它在多个公开基准测试中的卓越表现,特别是在中文文本渲染上显著超越现有先进模型,充分证明了其在文生图领域的全面领先地位。这项技术对于广告设计、内容创作和个性化表达等领域将产生深远影响。
xAI Grok Imagine4:文生图与视频的探索
xAI推出的Grok Imagine4模型在文生图和图生视频领域进行了大胆尝试。其文生图功能以极快的生成速度著称,接近实时浏览体验,极大地提升了创作效率。在图生视频方面,Grok Imagine4同样展现出高效率,能够迅速将静态图像转化为动态视频。尽管视频的画面细节和流畅性仍有提升空间,但其探索性意义不容小觑。值得注意的是,Grok Imagine4原生支持NSFW(不适宜工作场所)内容生成,这一特性在AI伦理和内容监管领域引发了广泛讨论,凸显了技术发展与社会责任之间的复杂平衡。
大模型能力边界的持续拓展
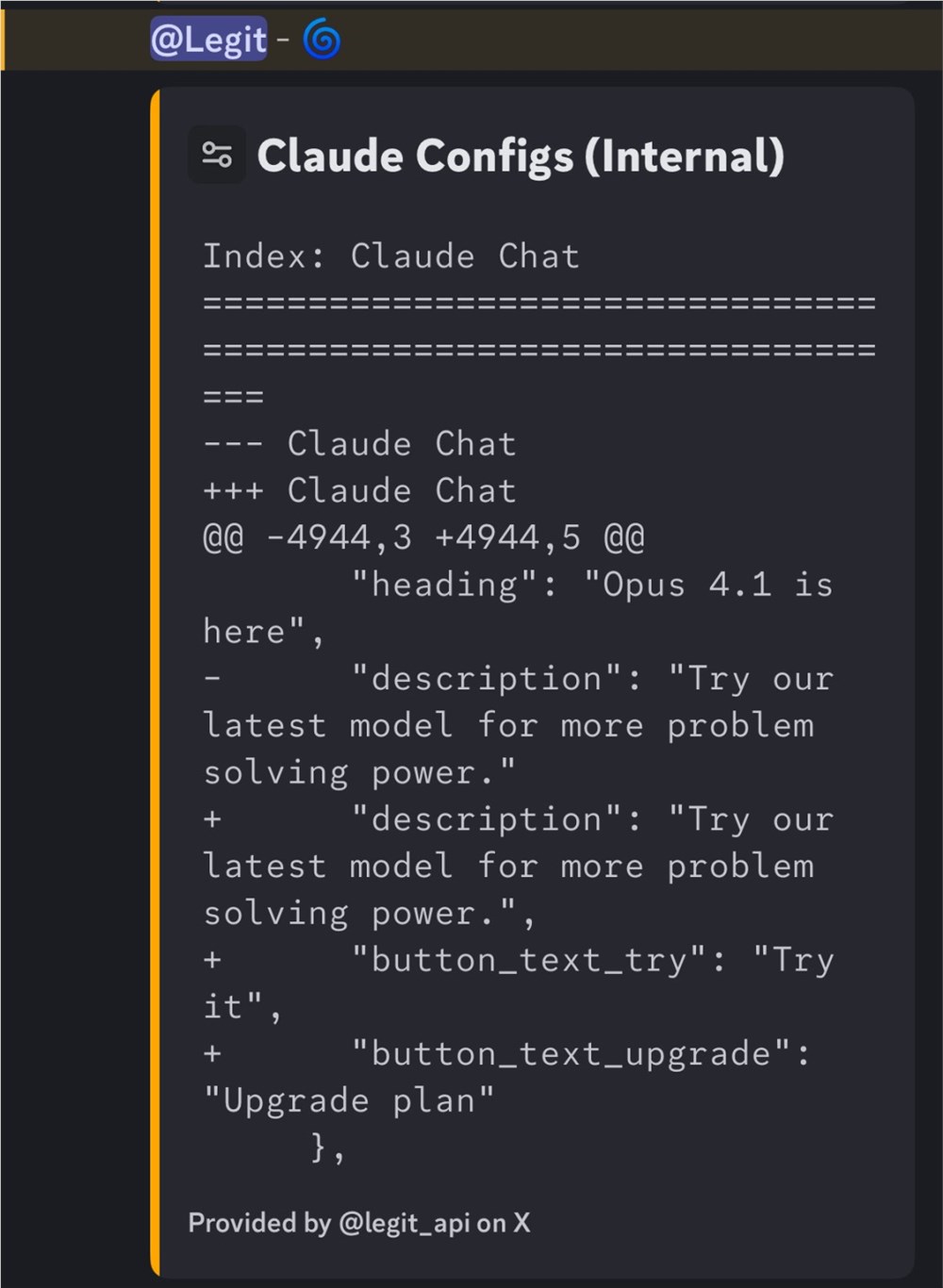
Anthropic Claude Opus 4.1:推理能力再升级
市场普遍关注,Anthropic正对其下一代大型语言模型Claude Opus 4.1进行内部测试,其内部代号“claude-leopard-v2-02-prod”本身就充满了暗示意味。新模型的宣传语强调了其在问题解决能力上的显著提升,这表明其在逻辑推理和处理复杂任务方面取得了重大突破。据推测,“leopard”(豹子)这一代号可能预示着模型具备更快的响应速度和更精准的分析能力,暗示了其底层架构的创新。内测版本号“v2-02-prod”进一步表明模型已进入生产环境测试阶段,距离正式发布可能不远。在当前竞争激烈的AI市场中,Claude Opus 4.1的推出无疑将有助于Anthropic保持其在技术领先地位,特别是在需要高级认知能力的专业领域。
智谱Zread.ai:GLM-4.5赋能的开发效率工具
智谱AI推出了Zread.ai,一款基于其GLM-4.5大语言模型的开发效率工具,旨在革新开发者的工作流程。这款工具的核心价值在于帮助开发者快速掌握项目结构、高效生成技术文档,并显著提升团队协作效率。Zread.ai的核心功能包括深入的代码理解、智能的知识生成以及无缝的团队协作。它利用GLM-4.5模型强大的代码分析能力和极低的误判率,实现对复杂代码库的精准理解,并在此基础上自动生成高质量的项目导读,涵盖架构解析、模块说明等关键内容,极大地简化了文档撰写工作。此外,Zread.ai还支持深入的技术问答,能够回答开发者在项目理解和调试过程中遇到的各种问题。这款工具的出现,预示着未来软件开发将更加智能化、自动化,极大地解放开发者的生产力,使其能更专注于创新性的工作。
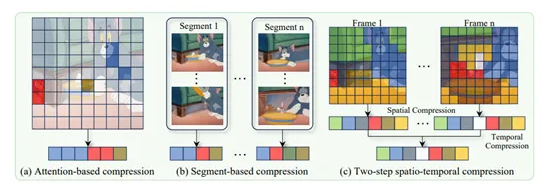
阿里巴巴与南开大学LLaVA-Scissor:视频大模型压缩新范式
在视频大模型领域,阿里巴巴通义实验室与南开大学计算机科学学院联合开发了一种创新的视频大模型压缩方法——LLaVA-Scissor。该技术旨在解决传统方法中Token数量激增导致计算资源消耗巨大的问题。LLaVA-Scissor通过基于图论的SCC(强连通分量)算法,有效计算Token之间的相似性,构建图并识别连通分量,从而在显著减少Token数量的同时,最大限度地保留关键语义信息。这一方法显著提升了视频处理效率,并在多项视频理解基准测试中表现出色,尤其在低Token保留率下展现出卓越的性能优势,特别是在视频问答和长视频理解任务中表现尤为突出。这项技术为高效处理和分析大规模视频数据提供了新的解决方案,对于视频内容理解、智能安防和自动驾驶等领域具有重要意义。
AI应用生态的深化与扩展
腾讯ima:AI赋能知识管理新体验
腾讯旗下的AI知识管理工具ima近期推出了多项实用新功能,旨在全方位提升用户的知识获取与管理体验。其中最引人注目的是AI播客生成功能,这项创新允许用户将长篇文章或报告轻松转化为音频播客,极大地便利了碎片化时间的知识消化。此外,ima还新增了一键导入文件夹功能,简化了文档的批量管理流程,提升了工作效率。同时,支持Xmind脑图导入和知识库内容置顶功能,使用户能够更灵活地组织和突出显示重要信息,从而显著提升信息检索的效率和知识体系的构建能力。这些功能的迭加,使得ima成为一个更加全面、智能的知识管理平台,满足了现代工作和学习中对高效知识处理的迫切需求。

ChatGPT的商业化成功与发展思考
OpenAI旗下的ChatGPT用户规模持续爆发式增长,周活跃用户数已达7亿,同比增长超过四倍,这一数据创下了历史新高。随之而来的是OpenAI年化收入飙升至120亿美元,远超市场预期,印证了其在商业化道路上的巨大成功。有迹象表明,新一代模型GPT-5可能即将发布,这无疑将进一步推动AI技术边界的扩展。然而,在商业成功和技术迭代的同时,OpenAI也开始更加关注用户健康与体验。例如,新增的休息提醒功能体现了其对用户福祉的考量,旨在促进健康的使用习惯。ChatGPT的快速崛起及其带来的巨大商业价值,无疑对整个AI行业产生了深远影响,同时也引发了关于AI产品优化、用户健康以及与谷歌等巨头竞争的深入思考。
北京人形机器人3D视觉系统:迈向真实世界的感知
北京人形机器人创新中心近日发布了Humanoid Occupancy视觉感知系统,标志着人形机器人在三维空间感知能力上取得全球领先地位。该系统通过引入语义占用表征技术,实现了对三维空间的精准建模,并支持多模态传感器的协同工作,从而显著提升了机器人整合环境信息的能力。这一突破性进展有效解决了人形机器人在复杂、动态环境中进行高精度感知的难题。此外,该中心还构建了大规模数据集,为未来人形机器人视觉系统的深入研究提供了宝贵的资源支持。这项技术为人形机器人在智能制造、服务业以及灾害救援等领域的广泛应用奠定了坚实基础,加速了它们融入真实世界的能力。

OpenMind OM1:打造机器人领域的“安卓”生态
OpenMind公司致力于构建开放的机器人软件生态,其核心产品OM1操作系统旨在成为机器人领域的“安卓”平台。OM1的创新之处在于其名为FABRIC的协议,该协议能够实现机器人之间的身份验证和信息共享,从而构建一个信任与协作的网络。通过FABRIC协议,机器人群体能够像有机体一样进行协作和学习,显著提升群体智能的进化速度。OpenMind选择家庭场景作为切入点,旨在满足对人性化交互的迫切需求,并期待通过OM1操作系统推动机器人从单一任务工具向智能伴侣的转变。OM1的愿景是为全球开发者提供一个统一、开放的机器人开发平台,加速机器人技术的普及和创新。
展望与挑战
当前AI领域的技术爆炸并非偶然,它是长期积累与持续创新的结果。无论是多模态模型的融合,还是基础大模型能力的增强,亦或是具身智能的突破,都指向一个共同趋势:AI正从单一功能走向多模态融合、从理论研究走向实际应用、从实验室走向千家万户。然而,伴随技术飞速发展而来的是伦理、安全、隐私等一系列挑战。例如,Grok Imagine4对NSFW内容的支持引发了关于内容监管的深思,而ChatGPT用户激增也促使OpenAI开始关注用户健康。这些挑战要求AI研发者和政策制定者在推动技术进步的同时,必须平衡好社会责任。未来的AI发展,需要更开放的合作、更深入的跨学科研究,以及更完善的伦理规范,以确保AI技术能够真正造福人类社会,共同绘制智能时代的宏伟蓝图。










