
深入剖析字节跳动Seed-OSS:开源大模型如何重塑长文本理解与智能推理边界
人工智能领域正经历前所未有的快速发展,大型语言模型(LLMs)的创新迭代成为驱动这一进程的核心力量。2025年8月20日,字节跳动Seed团队向全球开发者与研究者社区投下了一枚重磅炸弹——正式发布了Seed-OSS系列开源大型语言模型。这一系列的推出,不仅标志着字节跳动在LLM开源生态中的深度布局,更预示着在国际化应用场景(i18n)、长文本理解与复杂推理能力方面,将迎来一场深刻的技术革新。Seed-OSS旨在提供强大、灵活且高度开发者友好的工具,以加速全球范围内的AI创新与应用落地。
一、Seed-OSS核心架构与长文本处理优势
Seed-OSS系列模型建立在业界广泛认可的因果语言模型(Causal Language Model)架构之上,并融入了一系列前沿技术优化,旨在提升模型性能与效率。其中包括:
- 旋转位置编码(RoPE):这种编码方式能够有效增强模型处理长序列的能力,同时减少位置信息的丢失,对于维持长文本中语义关联性至关重要。
- 分组查询注意力机制(GQA - Grouped Query Attention):GQA通过共享键(key)和值(value)投影,显著降低了长上下文长度下的计算和内存开销,使得模型能够在有限资源下处理更长的输入序列,从而提升推理效率。
- RMSNorm归一化层:相较于传统的LayerNorm,RMSNorm在稳定训练过程、加速收敛方面表现出优势,并有助于模型泛化性能的提升。
- SwiGLU激活函数:作为一种高性能的激活函数,SwiGLU已被证明能有效提高模型的表达能力和训练效率。
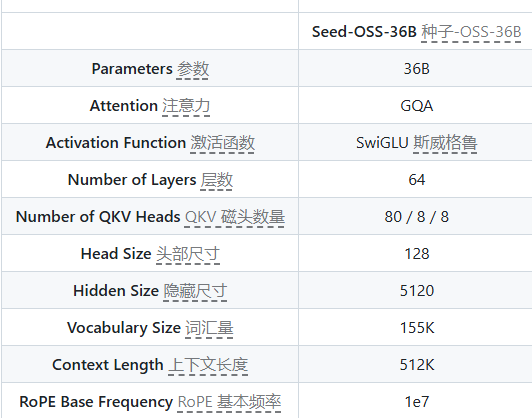
这些技术的巧妙结合,使得Seed-OSS模型系列,尤其是最新的Seed-OSS-36B模型,在参数规模与上下文长度之间达到了出色的平衡。该模型拥有360亿个参数,更令人瞩目的是其高达512K的超长上下文处理能力。这意味着Seed-OSS-36B能够一次性理解和处理相当于数十万个汉字长度的文本内容,远超当前主流开源模型的平均水平。在处理法律文档、科研论文、代码库甚至多轮复杂对话等场景时,这一特性将极大提升模型的理解深度和任务完成度。
值得注意的是,尽管Seed-OSS-36B仅使用了12万亿个训练数据,其在多个流行的基准测试中依然展现出卓越的性能。这不仅仅是参数规模的胜利,更是训练策略和架构优化有效性的有力证明,体现了模型在数据效率和性能之间的平衡艺术。
二、多样化模型版本与灵活的“思考预算”机制
为了满足不同应用场景和研究目的的需求,Seed-OSS模型系列提供了两种核心版本:
- Seed-OSS-36B-Base:此版本包含了经过精心设计的合成指令数据进行训练,使其在遵循指令、完成多样化任务方面表现出色,更适合作为高性能的基础模型直接应用于各类开发任务。
- Seed-OSS-36B-Base-woSyn:此版本则不包含合成指令数据。对于追求纯粹模型能力、希望避免合成数据可能引入的偏差、或旨在进行特定数据微调的研究者而言,woSyn版本提供了更为“原始”且灵活的研究基石。这种设计体现了字节跳动在推动AI研究透明度和有效性方面的承诺。
除了提供多样化的基础模型选择,Seed-OSS还引入了一项极具创新性的功能——“思考预算”(Thinking Budget)的灵活控制。在大型语言模型的推理过程中,尤其是在需要进行多步推理或生成长篇回复时,计算资源消耗巨大且难以预测。思考预算机制允许用户根据实际需求,动态调整推理过程的长度和深度。例如,在一个知识问答场景中,如果用户只需要一个简洁的答案,可以设置较低的思考预算以快速获取结果;而如果需要一个详细的分析报告,则可以提高预算,允许模型进行更深入的思考和信息整合。
这种机制在实际应用中具有显著优势:
- 提升推理效率:通过限制不必要的冗余计算,直接缩短了模型响应时间,降低了计算成本。
- 资源优化:尤其对于资源受限的部署环境,思考预算能够帮助开发者更好地管理和分配计算资源。
- 用户体验优化:允许用户根据任务重要性或实时性要求,个性化定制模型的“思考”程度,从而提升了整体的用户体验。
此外,Seed-OSS在模型设计和训练阶段就特别优化了推理任务。这意味着在保持模型良好通用能力的同时,其在逻辑推理、问题解决等领域的表现得到了额外加强。这种以推理为核心的优化方向,使其在处理复杂的代理智能任务时更具优势。
三、Seed-OSS在多领域的前瞻性应用与卓越表现
Seed-OSS的发布,不仅为学术研究提供了强有力的工具,其在各类实际开发任务中的广泛应用前景也备受瞩目。Seed团队强调,该模型尤其适用于代理智能(Agentic AI)任务,例如:
- 工具使用(Tool Use):模型能够理解并调用外部工具(如API、搜索引擎、代码解释器等)来完成特定任务,极大地扩展了LLM的能力边界。例如,一个基于Seed-OSS的智能体可以接收“预订航班”的指令,然后自主调用航班预订API,并根据用户偏好进行参数调整。
- 复杂问题解决(Complex Problem Solving):通过多步推理和分解任务,模型能够逐步解决原先需要人类专家介入的复杂问题,例如软件开发中的bug定位与修复、科研数据分析等。
- 知识问答(Knowledge Question Answering):凭借其强大的长文本理解能力,Seed-OSS可以在海量文档中精确抽取信息,并以结构化或非结构化的方式回答用户提问,特别是在处理专业领域或冗长手册时展现出高效率。
- 数学推理(Mathematical Reasoning):通过理解数学语言和逻辑,模型能够解决从基础算术到复杂代数、几何问题,甚至辅助进行定理证明。
- 编程辅助(Programming Assistance):Seed-OSS可以协助代码生成、错误检测、代码重构、多语言翻译以及算法设计,成为开发者的高效副驾驶。
来自Seed团队的训练和评估结果显示,Seed-OSS在上述各项任务中的表现均达到了开源领域的领先水平。例如,在针对长文本理解的特定基准测试中,Seed-OSS展现出了比同等规模模型更低的困惑度与更高的信息抽取准确率。在逻辑推理任务中,它能够处理多达五步的逻辑链条,并在多数情况下得出正确结论。
四、开发者友好生态与未来展望
字节跳动Seed团队深知开源社区的力量,因此在Seed-OSS的设计和发布中,充分考虑了开发者的便捷性。团队提供了详细的快速入门指南,用户只需通过简单的pip install命令即可安装相关依赖,轻松下载和部署Seed-OSS模型。
此外,为了进一步优化模型的实际运行效率和部署门槛,Seed-OSS还支持多种量化方式,例如INT8、INT4等,这使得模型能够在更低的内存消耗下运行,尤其适合部署在边缘设备或资源有限的云服务器上。这种对效率的极致追求,无疑将加速Seed-OSS在各行各业的普及与应用。
总而言之,Seed-OSS的发布是字节跳动在推动人工智能技术普惠化进程中的一个重要里程碑。通过提供高性能、高灵活性且开发者友好的开源大语言模型,Seed团队期待能够激发全球AI社区的无限创新潜力,共同探索长文本理解、智能推理以及代理智能等前沿领域的更多可能性。Seed-OSS不仅仅是一个模型,更是一个连接研究者与开发者、赋能未来AI应用的强大平台,将有力推动人工智能技术在解决真实世界复杂问题方面迈向新的高度。










