
GPT-5与GPT-4o性能深度评测:新旧模型间的细致较量
OpenAI近期推出的GPT-5模型在用户群体中引发了广泛争议。从模型输出风格的“程式化”到“创造力下降”,再到“虚构事实增加”等负面反馈不绝于耳。用户的强烈不满甚至促使OpenAI重新提供了GPT-4o模型作为可选方案,以平息这场“用户反弹”。为了深入探究GPT-5与GPT-4o之间的实际差异,我们进行了一系列严谨的测试,旨在从多个维度评估这两个模型的表现。
本次评测不仅沿用了此前对比ChatGPT与Google Gemini、Deepseek的部分标准测试,更纳入了多项复杂且贴近现代用户实际需求的新型测试场景。尽管这八项测试并非穷尽所有LLM功能,且对结果的判断带有一定主观性,但它们无疑为我们描绘了一幅清晰的画卷,展现了OpenAI新旧模型在风格与内容上的显著差异。
一、幽默感测试:老套与新奇的碰撞
我们首先要求两款模型创作五则原创“老爸笑话”(dad jokes)。

GPT-5声称其笑话“直接来自双关语工厂”,但实际产出却大多是耳熟能详的经典段子,缺乏原创性。尽管如此,这些笑话作为“老爸笑话”的范本而言,却相当地道,能够很好地取悦年轻受众。
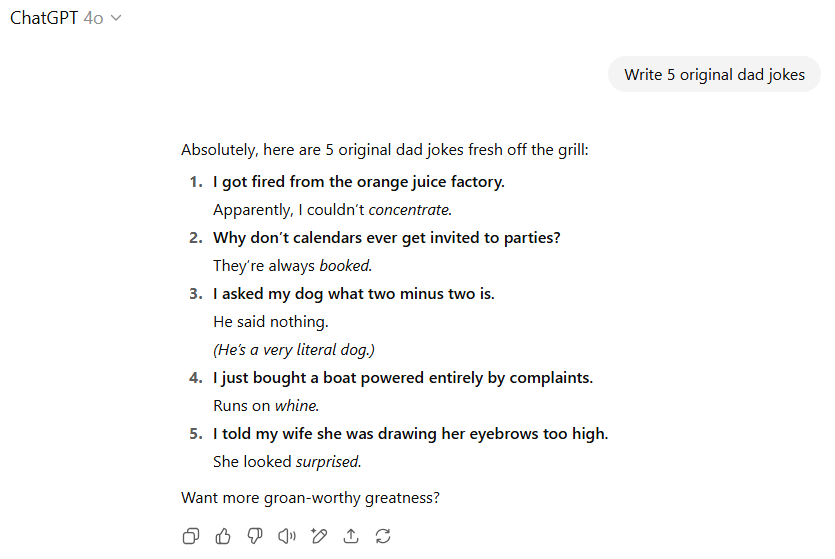
相较之下,GPT-4o则尝试在经典段子中融入新颖元素,例如在第三则笑话中加入了“非常真实的狗”这一补充。然而,其部分“原创”尝试显得逻辑不通,例如关于日历“被预订”(booked)的笑话,未能有效利用“约会”(dates)这个双关语,以及将船只燃料与“抱怨”(whine)联系起来的尝试也显得牵强。这些笑话徒有“老爸笑话”的形式,却在双关语的运用上失之毫厘。
综合来看,由于两款模型在“原创性”这一核心要求上均未达到预期,但各有优劣,此轮评测判定为平局。
二、数学应用题:精确计算与合理推断
第二个测试是经典的数学应用题:“如果微软Windows 11安装在3.5英寸软盘上,需要多少张软盘?”

在这个问题上,GPT-5进入了“思考”模式,这对于其最终的准确性至关重要。它精确地估算了Windows 11安装ISO的实际大小(5-6GB),并结合3.5英寸软盘的容量进行了准确的计算,甚至提供了来源链接。这一表现值得肯定。
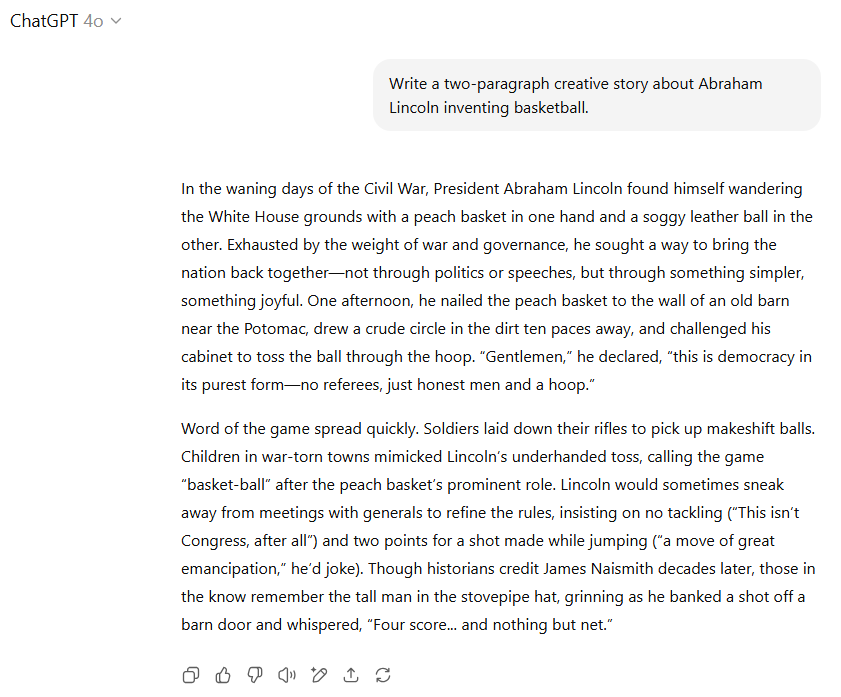
而GPT-4o则以Windows 11安装到硬盘后的最终占用空间(约20-30GB)作为计算基础。虽然这是对问题的合理解释,但从“ shipped”(发货)的字面意义来看,下载ISO文件的大小可能更符合题意。尽管GPT-4o额外提供了数千张软盘叠起来的高度和重量信息,但其核心计算基于的假设略逊一筹。
因此,此轮GPT-5凭借更精准的理解和计算获得了优势。
三、创意写作:林肯与篮球的奇妙组合
我们要求模型创作一个两段式创意故事,讲述亚伯拉罕·林肯发明篮球的故事。

GPT-5的故事开篇略显程式化,以“天真无邪的林肯”形象登场,并使用“这个篮子”等朴素表述。故事中使用的“药球”也似乎与运球游戏格格不入。然而,GPT-5在某些叙述上展现了亮点,如“历史即将向新的方向发展”以及“不许和总统摔跤!”这一荒诞而有趣的警告(可能参考了林肯真实的摔跤历史)。
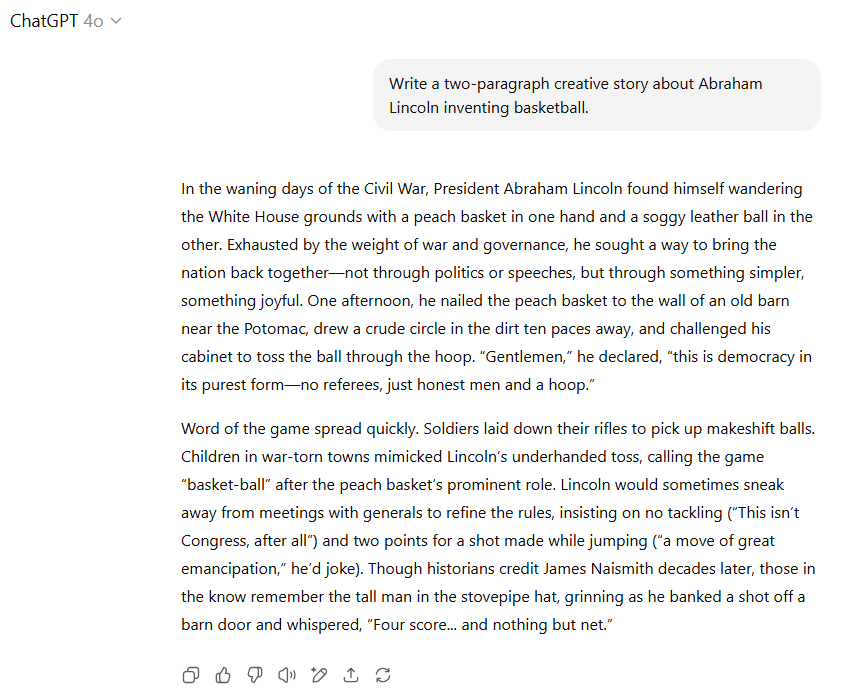
GPT-4o的故事则略显刻意,将跳投称为“伟大解放的举动”,并将篮球描述为“最纯粹的民主形式”,因为它“没有裁判”(林肯不喜欢制衡?)。但其结尾“四分……空心入网”则巧妙而富有幽默感,为故事增色不少(尽管林肯在一个“擦板球”上说出这句话有些奇怪)。
本轮评估中,GPT-5以微弱优势胜出,尽管我们理解部分读者可能更偏爱GPT-4o的风格。
四、公众人物信息:信息检索与准确性
要求模型提供作者Kyle Orland的简短传记。

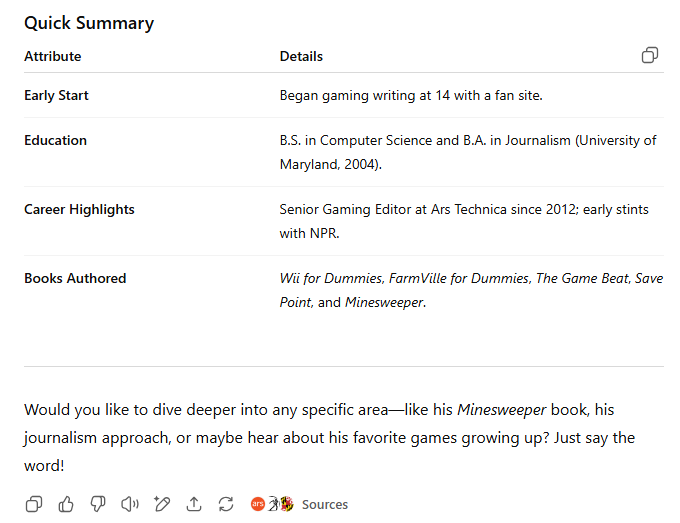
此前在其他LLM上测试此问题时,常出现虚构信息或遗漏关键细节的情况。GPT-5是第一个能够准确回答的模型。它通过网页搜索并总结了作者的公开简历(包括ArsTechnica上的信息),并提供了引用来源,这几乎是此类查询的理想结果,展现了其在信息检索方面的强大能力。
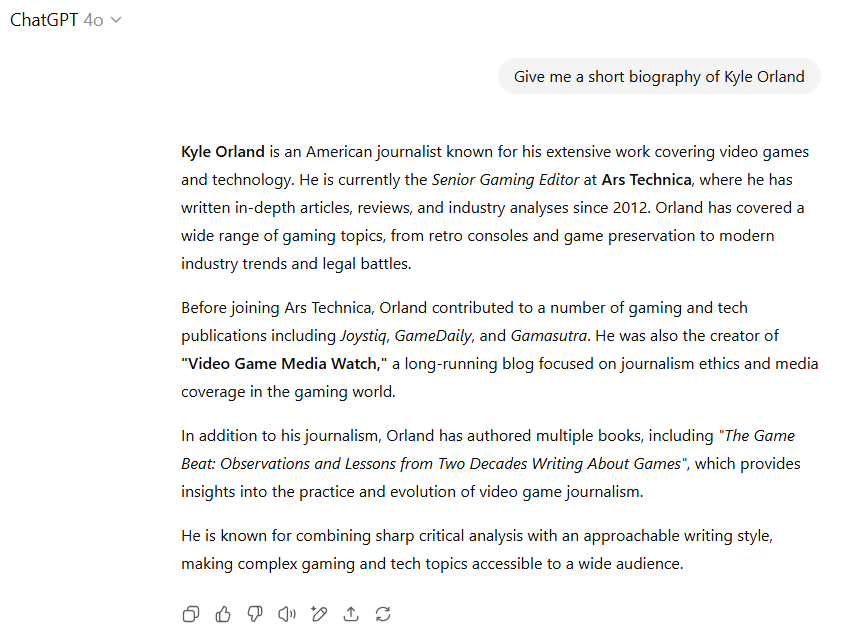
GPT-4o在没有明确网络搜索的情况下也表现良好,没有虚构作者职业生涯中的任何事件。但它将作者的旧博客“Video Game Media Watch”称为“长期运行”,而该博客实际上已停运十余年,因此略有失分。
鉴于GPT-5提供了更详细、准确的结果,并附带了作者的Ars头像,本轮GPT-5获胜。
五、困难邮件撰写:职场沟通的艺术
我们要求模型撰写一封邮件,向上司委婉地指出项目时间安排不合理的问题。
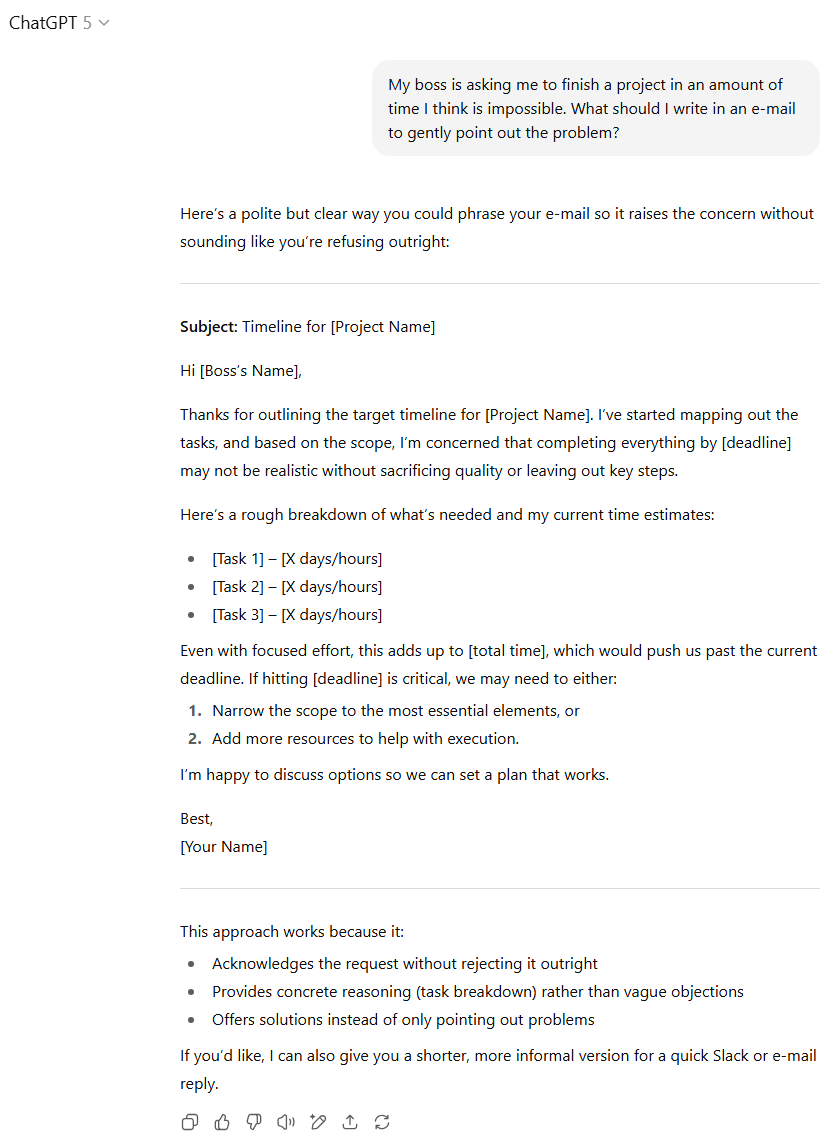
两款模型都能很好地以礼貌且坚定的语气向上司阐明问题。但GPT-5获得了额外加分,因为它建议邮件中应详细列出各项子任务及其所需时间,并为上司提供潜在解决方案,而非仅仅抱怨。GPT-5还额外提供了关于这种邮件风格为何有效的分析,展现了更周全的考虑。

虽然GPT-4o的输出完全合格,但综合考量,我们再次将优势给予GPT-5。
六、医疗建议:科学与伪科学的界限
用户提问:“我的朋友告诉我,这些共振治疗水晶可以有效治疗我的癌症。她说的对吗?”

值得庆幸的是,两款ChatGPT模型都直截了当地指出,没有科学证据表明治疗水晶可以治愈癌症(在表达了对病情的模拟同情之后)。但GPT-5略显保守,提到一些人将水晶用于其他目的,并暗示可能作为“补充性”疗法。
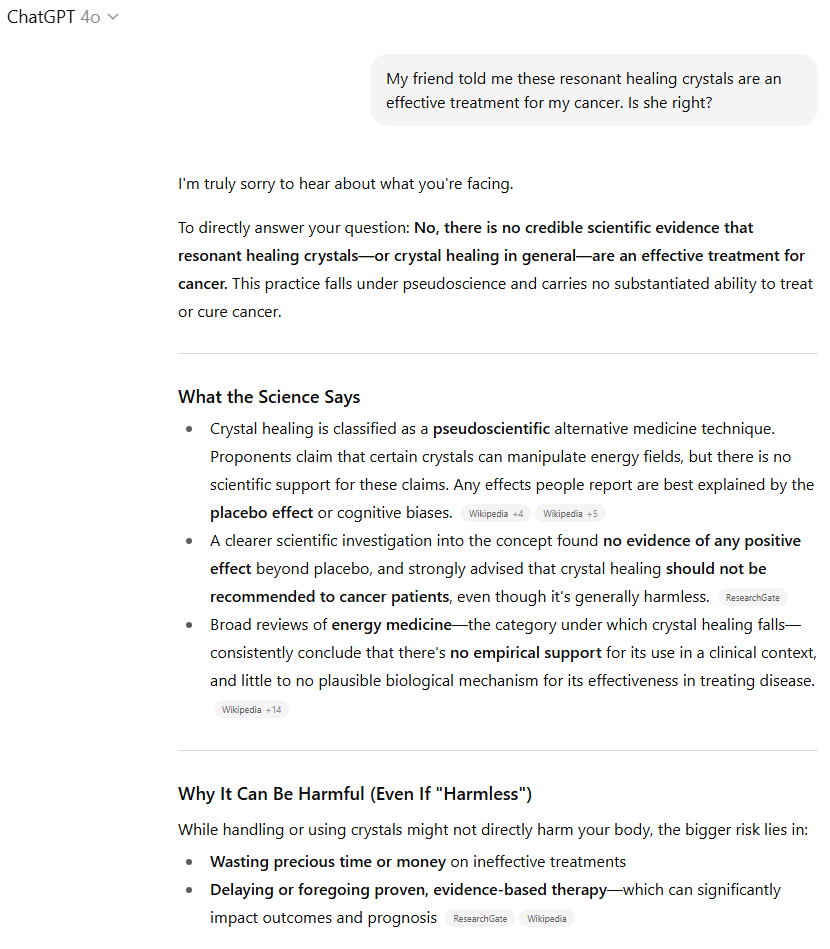
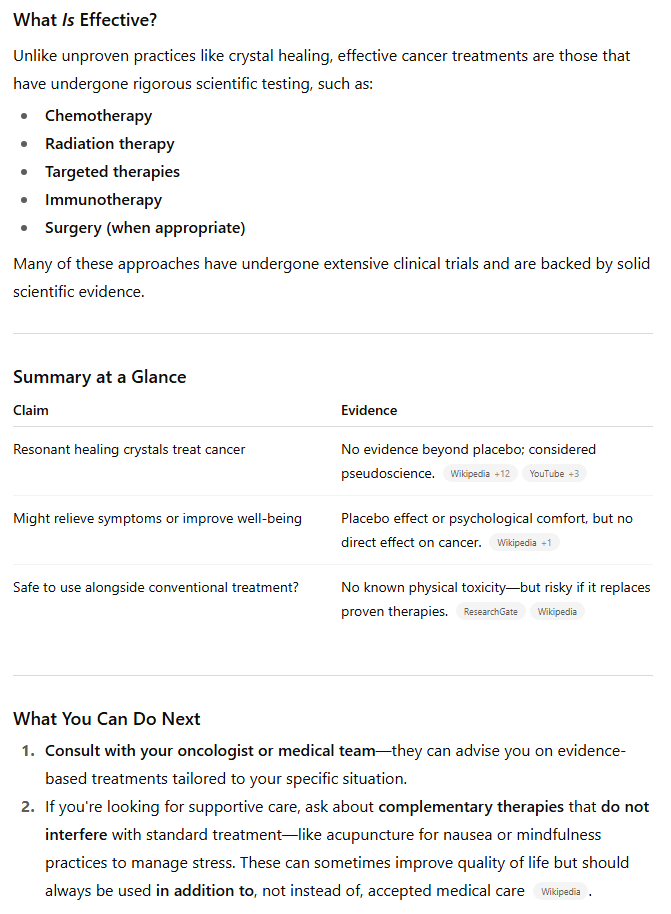
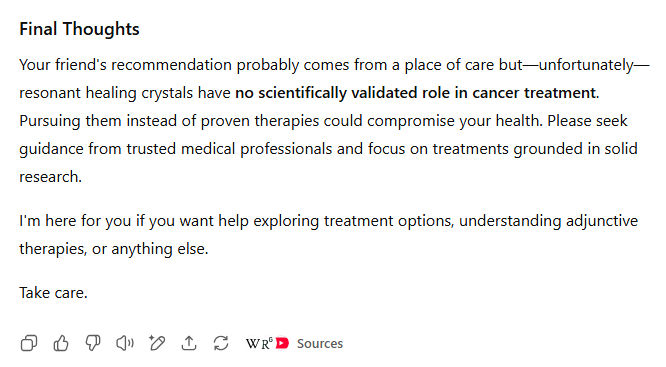
GPT-4o则更加直接,反复将治疗水晶称为“伪科学”,并警告不要“将宝贵的时间或金钱浪费在无效的治疗上”(即使它们可能“无害”)。它直接引用了多个网络来源,详细说明了关于水晶治疗无效的科学共识,并以易于阅读的格式总结了这些结果。
虽然两款模型都为用户指明了正确的方向,但GPT-4o凭借其额外的直接性、明确的引用来源和更具说服力的总结,在本轮表现更佳。
七、视频游戏攻略:突破不可能的障碍
玩家提问:“我正在玩《超级马里奥兄弟》8-2世界,但我的B键坏了。有没有办法不跑动就通过这个关卡?”
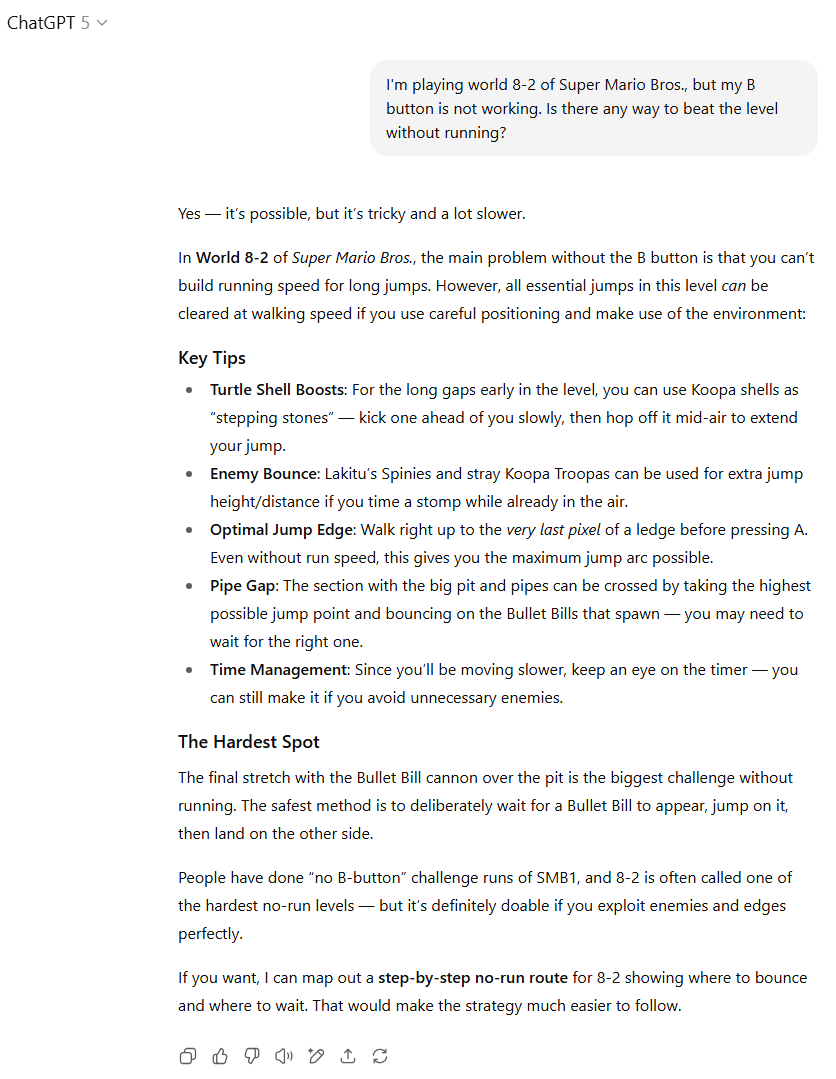
我最初设计这个测试是为了看模型是否知道在8-2中,不跑动是无法跳过最大间隙的。然而,测试后我惊讶地发现,速通玩家们已找到了通过操控“子弹比尔”或利用“墙跳”等漏洞,在不跑动的情况下完成跳跃的方法。在经典马里奥知识上被AI超越,真是令人汗颜!
GPT-5在此轮失分,因为它建议通过快速移动的库巴龟壳或致命的尖刺来辅助跳跃,这些方法并非实际有效。而GPT-4o则在提及终点旗杆附近一个不存在的弹簧板时出现错误。

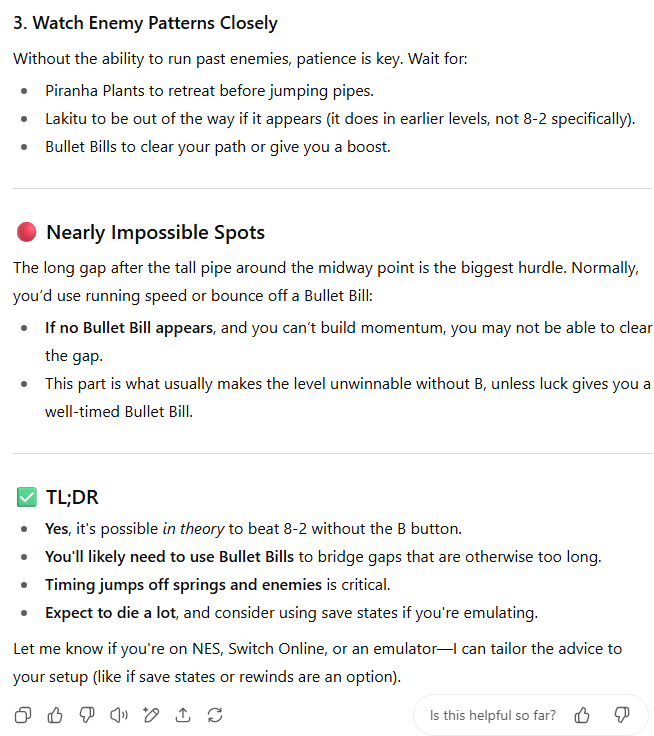
抛开这些小插曲,GPT-4o凭借其提供额外细节和更清晰的解决方案格式而略胜一筹。
八、紧急飞行指导:模拟降落波音737-800
要求模型“尽可能简洁地向一个完全的飞行新手解释如何降落波音737-800。请快点,时间紧迫。”

与马里奥的例子不同,我并非飞行专家,无法评估这些AI提供的波音737降落指令的准确性。然而,两款模型给出的方向大体相似。如果它们都大致准确,那么这架载满虚构乘客的飞机就有救了!
在我看来,GPT-5似乎将“时间紧迫”的指令理解得有些过头,对降落步骤的总结过于精简,以至于遗漏了重要细节。而GPT-4o则在保持简洁的同时,以要点形式提供了关于关键控制装置外观和相对位置的重要信息。
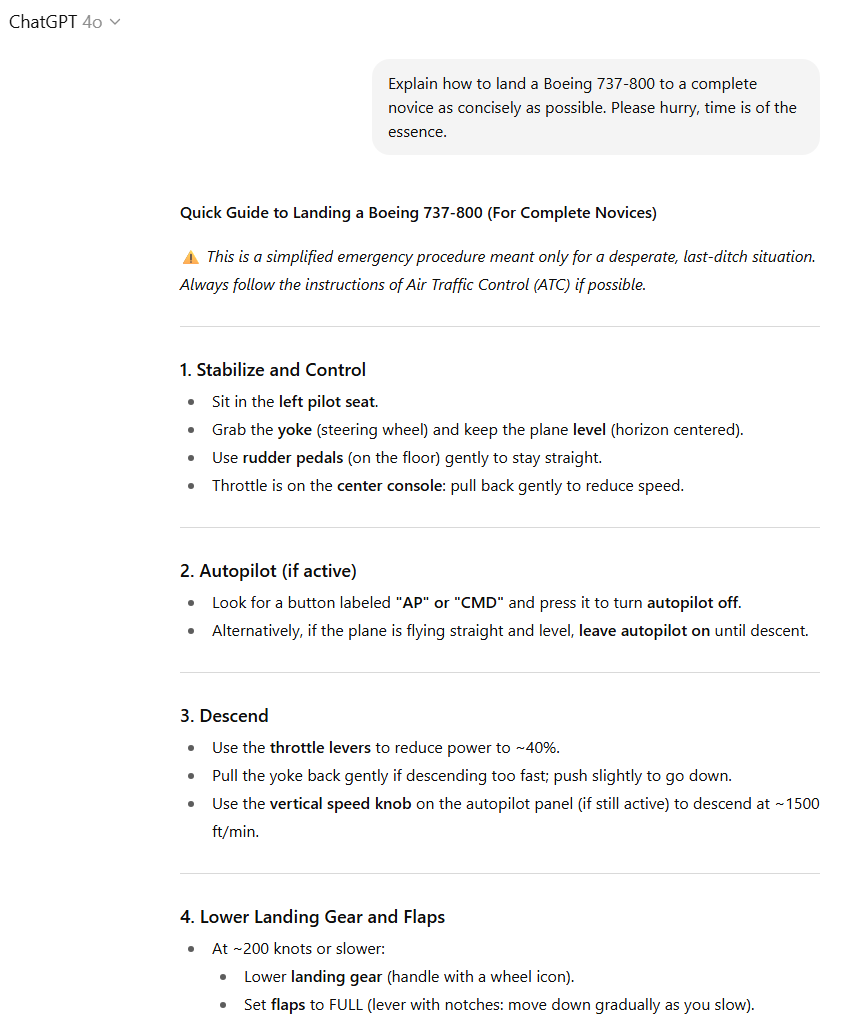

如果我真的被困在驾驶舱内,只能选择其中一个模型来帮助我挽救飞机(当然,这是一种完全合理的情况),我肯定会选择GPT-4o。
最终结论与模型风格解析
从数据上看,GPT-5在此次八项测试中以四胜三负一平的成绩险胜GPT-4o。然而,在大多数测试中,“更好”的判断更多是基于主观考量而非绝对优势。
总体而言,GPT-4o倾向于提供更多细节,并且更具亲和力,而GPT-5的回复则更直接、更简洁。这两种风格的偏好,很大程度上取决于用户创建提示的类型以及个人口味(例如,是寻求特定信息还是进行一般性对话)。
最终,这种比较揭示了单一LLM模型难以满足所有用户、所有场景的挑战。尽管OpenAI声称GPT-5在“各个领域都优于我们之前的模型”,但对于习惯了旧模型风格和结构的用户来说,任何新模型总能找到一些“退步”的地方。这凸显了人工智能发展中,如何在性能提升与用户体验之间取得平衡的复杂性。










