
AI技术前沿:创新浪潮席卷多领域
当前,人工智能技术正以惊人的速度演进,不断突破传统边界,渗透至内容创作、工业制造、服务体验等各个领域。本周,一系列具有里程碑意义的进展再次证明了AI的巨大潜力和变革力量。从多模态AI的深度融合,到3D内容生成的平民化,再到大模型训练范式的优化和机器人硬件的升级,这些创新不仅提升了现有系统的性能,更为未来的智能应用奠定了坚实基础。
多模态AI的融合与创新
多模态人工智能是当前AI研究的热点,旨在让AI能够理解和生成多种类型的数据,如文本、图像、音频、视频等。本周的进展在这一领域展现了显著的融合趋势。
突破边界:音视频同步生成新里程碑
阿里通义万相团队预告的Wan 2.2-S2V模型,标志着AI在视频与音频同步生成方面取得了重大突破。该模型能够深度融合视觉与听觉信息,生成连贯且具有表现力的AI视频,甚至可以包含唱歌音频,这远超传统视频生成模型的单一模态限制。这项技术有望彻底改变电影制作、游戏角色动画、虚拟主播乃至数字人交互等领域的创作流程,为内容创作者提供前所未有的自由度和效率,实现更具沉浸感和真实感的数字内容体验。其核心在于通过精密的算法,确保视频中人物的口型、表情与音频内容高度匹配,极大地提升了用户对生成内容的接受度。

超越语言:端侧多模态模型的崛起
面壁智能与清华大学NLP实验室联合推出的MiniCPM-V4.5模型,以其4.1亿的参数量,在端侧多模态大模型领域展现出惊人的性能。该模型在多项基准测试中超越了许多更大规模的模型,尤其在多图理解、视频理解和高分辨率图像处理方面表现卓越,甚至在OCR(光学字符识别)任务上领先主流模型。MiniCPM-V4.5的高效部署能力使其适用于移动设备和离线场景,极大地降低了AI技术普及的门槛。这意味着未来的智能手机、智能穿戴设备等边缘设备将能拥有更强大的视觉和语言理解能力,催生出更多创新的应用和服务,如实时场景理解、智能辅助创作等。

音频革命:长时语音合成的新高度
微软开源的VibeVoice-1.5B模型在语音合成技术上实现了多项重大突破。它支持一次性合成长达90分钟的超长语音,并能模拟最多四位发言人的声音,同时实现了高达3200倍的音频压缩率,却仍能保持高保真语音效果。更值得关注的是,其采用的双tokenizer架构有效解决了传统语音合成中音色与语义不匹配的问题,使得生成的语音更自然、更富有情感。这项技术在有声读物、播客、智能客服、无障碍辅助以及多媒体内容创作等领域具有广阔的应用前景,能够极大提升用户体验和内容生产效率。
3D内容生成与视觉智能的新范式
随着元宇宙和虚拟现实技术的发展,3D内容的创作需求日益增长。AI在3D生成和视觉理解方面的能力提升,正逐步降低创作门槛。
降低门槛:字节跳动3D Model Generator
字节跳动旗下的豆包团队正在内测一款名为“3D Model Generator”的新型3D模型生成工具。这款工具旨在为用户提供可控的大规模生成模型功能,支持基于图像生成3D模型,或结合图像与现有模型文件进行生成。它的出现有望大幅降低3D建模的专业技术门槛,使得更多非专业人士也能轻松创建高质量的3D资产。在游戏开发、AR/VR内容制作、工业设计以及电商展示等领域,该工具的对外开放将为创作者和开发者带来前所未有的便利,加速3D内容的普及和应用。
视觉创作:谷歌Imagen 4的演进
谷歌公司发布了全新的文本转图像生成模型Imagen 4,并通过Gemini API和Google AI Studio平台向用户开放。Imagen 4包含三个版本,分别针对不同需求进行优化:标准版提升了整体图像生成质量和文本渲染准确性;Fast版本专注于快速图像生成和大批量处理任务,将成本降至每次生成0.02美元;Ultra版本则能生成更精细的图像细节,并更准确地遵循复杂的用户文本提示。这些进步为艺术创作、广告设计、产品原型开发等行业提供了强大的工具支持,使创意想法能够更高效、更精准地转化为视觉作品。
大语言模型训练与智能机器人前沿
大型语言模型(LLMs)的训练效率和效果是衡量AI能力的关键指标。同时,机器人技术与AI的结合也正加速智能时代的到来。
优化之道:苹果RLCF方法革新LLM训练
苹果公司研究团队提出了一种名为“基于清单反馈的强化学习(RLCF)”的创新训练方法,旨在提升大语言模型执行复杂指令的能力。RLCF通过用具体任务清单替代传统的人工点赞评分机制,为模型提供了更精确、更具结构化的反馈。该方法在FollowBench、InFoBench等多个评测基准中表现出色,尤其在处理复杂多步骤任务时,性能提升显著,最高可达8.2%。这项技术为LLMs的持续优化开辟了新途径,有助于模型更好地理解并执行用户意图,但在实际应用中,生成大规模检查清单仍需强大的计算资源支持。
智能硬件:英伟达Jetson Thor赋能机器人
英伟达推出了全新的Jetson Thor机器人计算平台,该平台基于Blackwell GPU架构,AI算力高达2070TFLOPS,相较于上一代产品性能提升了7.5倍。Jetson Thor配备128GB超大内存,能够支持多个复杂的AI模型同时运行,处理多任务和复杂场景。此外,它还集成了NVIDIA Isaac仿真平台,为开发者提供了一个从云端到边缘的统一开发环境。这一强大的计算平台将极大地加速工业机器人、自动驾驶、医疗机器人等领域的发展,为构建更智能、更自主的机器人系统提供核心算力支持。

AI应用创新与伦理治理
AI技术的广泛应用不仅带来了效率和便利,也引发了对伦理、安全和社会责任的思考。
设计革命:Genspark AIDesigner的品牌全案能力
Genspark推出的AI Designer是一款革命性的AI设计工具,能够一键生成完整的品牌设计方案。该工具支持多模态输入,并能生成矢量图标、3D渲染和动画视频等多种设计资产,涵盖了Logo、包装、网站设计等多个领域。通过自然语言指令,AI Designer能完成复杂的品牌设计任务,极大地降低了设计门槛,并为创作者和企业提供了高效且经济的解决方案。它重新定义了品牌设计流程,预示着AI在创意产业中的深远影响力。

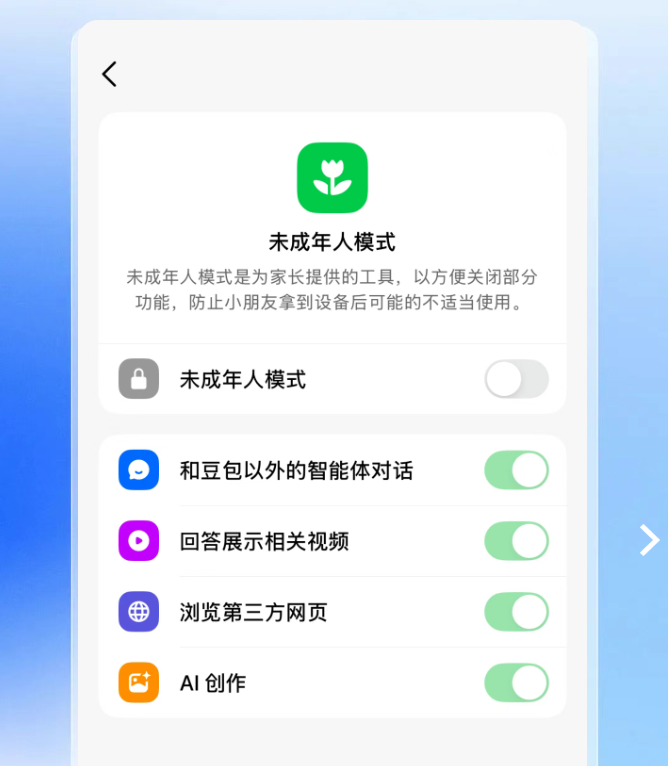
责任与守护:豆包未成年人保护模式
字节跳动旗下的豆包团队推出了未成年人保护模式,旨在帮助家长有效管理孩子使用AI产品。在该模式下,部分功能如推荐视频、第三方网页浏览等默认关闭,以避免不适宜内容对未成年人的影响。然而,翻译和深入研究等有助于学习和探索的功能仍可正常使用。这项措施体现了AI产品开发者在推动技术进步的同时,对社会责任和用户保护的重视,特别是对青少年健康成长的关注,有助于构建更安全、更健康的AI使用环境。
人才流动:字节跳动AI核心人才离职影响分析
字节跳动Seed大模型视觉基础研究团队的核心负责人冯佳时正式离职,这一事件引发了业界对AI领域人才竞争与流动的广泛关注。冯佳时在计算机视觉领域拥有深厚的学术背景和丰富的经验,曾为字节跳动在多模态基础模型和生成模型等前沿技术的研究做出重要贡献。核心人才的流失,无疑会对公司的AI战略布局和未来技术创新带来一定影响,也反映出AI行业对顶尖人才的激烈争夺。
展望未来:AI生态的演进与挑战
本周的AI进展描绘了一个日益成熟且多元化的智能生态系统。多模态能力的深化使得AI能够更全面地理解和交互世界;3D生成技术的民主化将释放海量创意潜力;大模型训练的优化确保了AI能力的持续提升;而强大的机器人硬件则将AI带入物理世界,实现更复杂的自主操作。然而,伴随技术快速发展而来的是伦理、隐私、数据安全和算法公平性等一系列挑战。构建一个负责任、可持续的AI生态,需要技术创新者、政策制定者、学者和公众的共同努力,以确保AI技术真正造福于人类社会,推动文明进步。

