
近年来,人工智能领域的发展速度令人瞩目,尤其是在大型语言模型(LLMs)的推动下,AI的能力边界被不断拓宽。然而,这种进步往往伴随着模型参数的爆炸式增长,从千亿到万亿的量级,这无疑带来了巨大的计算资源消耗、高昂的训练成本以及日益增长的环境足迹。业界普遍存在一种观念,即“参数越多,模型越强大”,这在一定程度上推动了模型规模的竞赛。然而,这种追求极致规模的路径,是否是实现高级智能的唯一或最优解?
微软研究院近期开源的rStar2-Agent模型,正以其仅140亿参数的“轻量”姿态,在AI数学推理这一高度复杂的任务上,展示出超越参数量达6710亿的巨型模型的惊人实力。这一突破性成果不仅挑战了“参数即性能”的传统认知,更预示着智能体强化学习(Agentic Reinforcement Learning)作为一种高效、自适应的训练范式,将重新定义AI处理复杂问题的能力,尤其是在需要严谨逻辑推理和外部工具协作的场景。
rStar2-Agent的核心突破:智能体强化学习范式革新
rStar2-Agent的成功并非偶然,其核心在于对传统AI推理方法的颠覆性创新。与依赖生成式思维链(Chain-of-Thought, CoT)方法的模型不同,rStar2-Agent采纳了一种更为动态和交互式的智能体强化学习框架。传统CoT方法通常通过逐步生成中间思考步骤来解决问题,但其内在的黑箱特性可能导致错误累积,一旦某个中间步骤出错,后续推理就可能偏离正确轨道。
告别思维链:自主规划与工具驱动的交互机制
rStar2-Agent则巧妙地摒弃了这种单向的生成模式,转而构建了一个能够自主规划、行动、观察和反思的智能体。该模型的核心工作流程是:首先,它对给定的数学问题进行深入理解和分析,自主生成一个初步的推理计划。其次,智能体具备调用外部工具,特别是Python代码执行器进行计算和验证的能力。当Python工具返回结果后,智能体并非盲目接受,而是会根据这些反馈信息,评估当前推理路径的有效性。如果发现偏差或错误,它会主动调整其规划和推理步骤,形成一个闭环的迭代优化过程。这种“试错-反馈-学习”的交互机制,显著增强了模型的自我修正能力,有效避免了传统CoT方法中常见的错误传播问题,使其在处理复杂的数学问题时表现出前所未有的鲁棒性和准确性。
实战表现:在顶级数学赛事中力压群雄
rStar2-Agent的性能并非纸上谈兵,而是在一系列权威的数学基准测试中得到了有力验证。这些测试不仅考量了模型纯粹的计算能力,更深入评估了其逻辑推理、问题分解以及与工具协同工作的综合能力。
AIME基准测试中的卓越成就
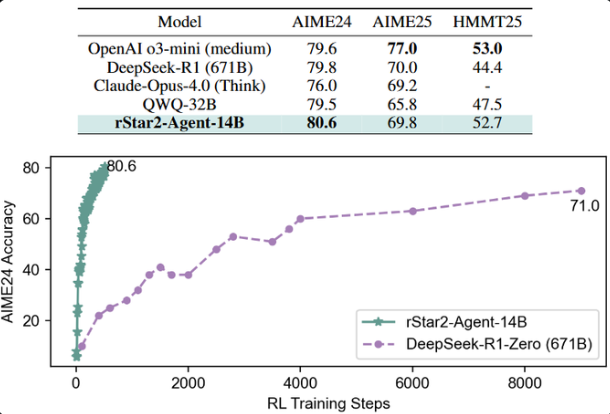
最具代表性的表现来自于美国数学邀请赛(AIME)基准测试。AIME是一项面向高中生的全球性高难度数学竞赛,其题目涵盖代数、几何、数论和组合数学等多个领域,要求参赛者具备深厚的数学基础和灵活的解题策略。在AIME24数据集上,rStar2-Agent的pass@1准确率(即模型首次尝试就给出正确答案的比例)达到了惊人的80.6%。这一成绩不仅超越了DeepSeek-R1(79.8%)、o3-mini(79.6%)等参数量远超自身的模型,甚至领先于Claude Opus4.0(77.0%)等业界领先的商业大模型。
在AIME25测试中,rStar2-Agent也取得了69.8%的准确率,而在更具挑战性的HMMT25测试中,其准确率达到了52.7%。这些数据充分证明了rStar2-Agent在复杂数学推理任务上的强大实力,也印证了智能体强化学习在这一领域具备的巨大潜力。
推理效率与训练成本的革命性优化
除了卓越的准确率,rStar2-Agent在推理效率上也展现出了显著优势。在AIME24测试中,其平均响应长度约为9340个token,而在AIME25中约为10943个token。这一数字仅为DeepSeek-R1模型平均响应长度的一半左右。更短的响应长度意味着更低的计算资源消耗、更快的推理速度以及更低的运营成本,对于实际应用场景而言,具有不可估量的价值。尤其是在企业级部署和大规模服务中,token消耗的减少直接对应着成本的节约和效率的提升。
在训练效率方面,rStar2-Agent同样表现出色。该模型仅需一周时间,利用64块MI300X GPU即可完成510个强化学习步骤的训练。其强大的强化学习基础设施支持每步高达4.5万个并发工具调用,而平均延迟仅为0.3秒。这种高效的训练能力,使得研究人员能够更快地迭代模型、验证新想法,从而加速AI技术的创新步伐。对于资源有限的研究团队和初创公司而言,这意味着他们能够以更低的门槛参与到AI大模型的研发和应用中来,实现“小而精”的逆袭。
技术深度解析:GRPO-RoC算法与泛化能力
rStar2-Agent的成功离不开其背后精妙的算法设计。在智能体强化学习的过程中,如何处理代码执行中可能存在的环境噪声和不确定性,是提升模型性能的关键。
噪声环境下的精确推理保障
为了解决代码执行中的环境噪声问题,rStar2-Agent引入了GRPO-RoC(Generalized Policy Optimization with Resample on Correct)算法。传统强化学习算法在面对复杂的外部工具和多步交互时,容易受到中间步骤错误或不确定性的干扰。GRPO-RoC算法的核心思想是“正确时重采样”策略:当智能体通过调用工具获得了正确或高质量的推理轨迹时,系统会对其进行重点关注和重复采样,从而在训练过程中强化这些正确的决策路径。这使得模型能够更有效地从成功经验中学习,降低了错误反馈对学习过程的负面影响,极大地提升了模型在嘈杂环境下的推理准确性和稳定性。
超越特定任务:智能体模型的通用智能潜力
rStar2-Agent的泛化能力同样令人瞩目。除了在数学推理任务上表现优异,它在GPQA-Diamond科学推理基准上超越了DeepSeek-V3,并在BFCL v3工具使用任务以及IFEval、Arena-Hard等通用测试中也展现出良好的性能。这表明,智能体强化学习所培养的不仅仅是针对特定任务的模式识别能力,更是一种解决问题的通用方法论。通过学习如何规划、执行、验证和修正,rStar2-Agent能够将这种高级的思维过程迁移到不同类型的推理任务中,从而展现出更接近人类智能的通用解决问题的潜力。这对于实现真正的通用人工智能(AGI)具有深远的启示意义。
展望未来:AI发展的新范式与开源力量
微软rStar2-Agent的发布,无疑在AI领域投下了一颗重磅炸弹。它不仅仅是一个高性能的模型,更是一个具有里程碑意义的信号,预示着人工智能的发展正在迈向一个新阶段。
挑战“大即是强”:效率与创新引领未来
这一成果有力地挑战了长期以来“参数越多性能越好”的传统观念,清晰地表明了训练方法、算法创新和架构优化在AI发展中的关键作用。未来的AI研究可能不再仅仅追求模型规模的无限扩张,而是会更加关注如何通过更智能的训练策略、更精巧的模型架构,以及更高效的资源利用,来释放AI的潜力。对于行业而言,这意味着未来发展将更注重效率、专用性和可持续性,为更多创新者提供了参与和贡献的可能。
开源赋能: democratizing AI研究
微软已将rStar2-Agent的代码和训练方法开源,基于VERL框架实现多阶段强化学习训练。这一举措无疑将极大地推动AI研究的民主化进程。通过开放代码和详细的训练方法,全球的研究者和开发者都能深入理解其原理、复现其成果,并在此基础上进行二次开发和创新。这不仅能够加速智能体强化学习领域的整体进步,也将为资源有限的研究者和开发者提供强大的工具,使他们能够以较小的投入实现媲美甚至超越巨型模型的性能,共同探索人工智能的无限可能。rStar2-Agent的成功案例,为AI领域指明了一条通往更高效、更普惠、更具创新力的发展道路。

