
Qwen3-ASR-Flash:洞察未来智能语音识别的核心驱动力
在数字化浪潮与人工智能技术飞速发展的当下,语音识别(ASR)技术已成为连接人与机器、实现高效信息交互的关键桥梁。从智能家居的语音助手到企业级会议的自动转录,ASR技术的精度与鲁棒性直接影响着用户体验和业务效率。阿里通义作为AI领域的领军者,最新发布的Qwen3-ASR-Flash模型,无疑为这一领域注入了强大的创新活力。它不仅仅是Qwen3系列在语音识别上的延展,更是一项集高精度、多语种、歌声识别、定制化与高鲁棒性于一体的综合性解决方案,旨在应对当前语音技术面临的诸多复杂挑战。
Qwen3-ASR-Flash的核心技术优势解析
Qwen3-ASR-Flash的诞生,标志着语音识别技术在多维度性能上实现了显著跃升。其核心优势在于对复杂声学环境和多样化语言模式的卓越处理能力,为各类应用场景提供了坚实的技术支撑。
1. 高精度多语种与多方言语音识别
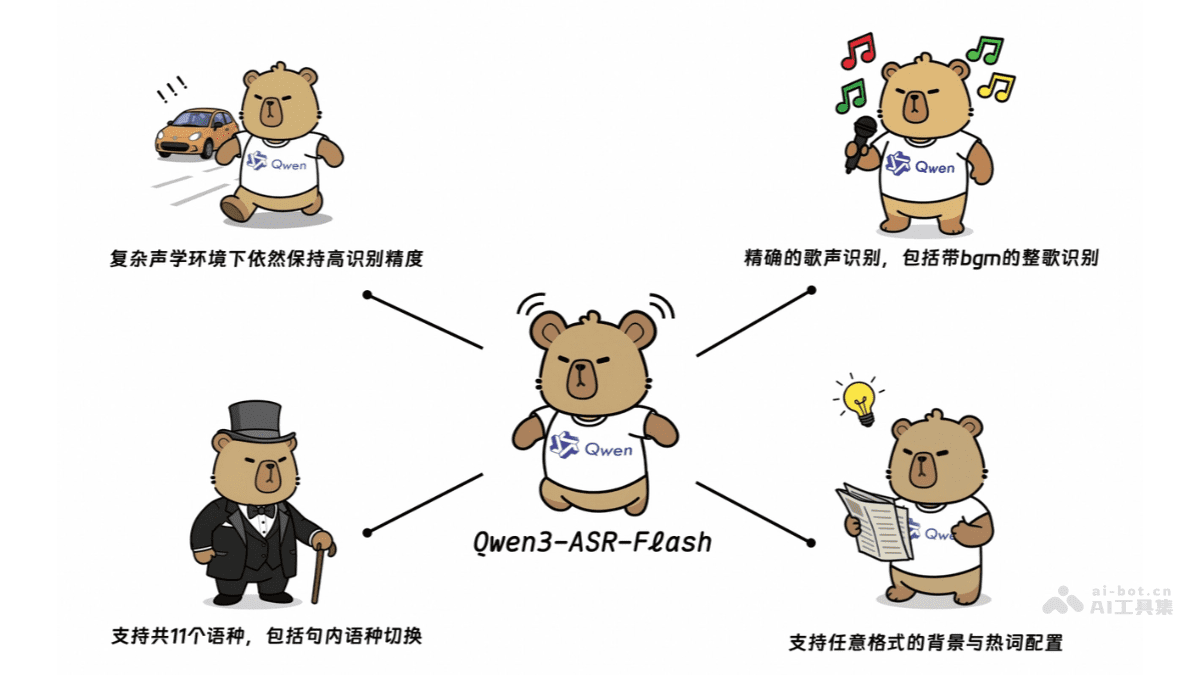
该模型在多种语言和方言的语音识别任务中表现出行业领先的准确性。它能够精准转录包括普通话、四川话、闽南语、吴语、粤语等在内的主要中文方言,以及英式、美式等多种英语口音,同时全面覆盖法语、德语、俄语、西班牙语、日语、韩语、葡萄牙语、意大利语、印尼语等9种其他主流语言。这种广泛的语种和方言支持,极大地拓宽了其应用范围,尤其对于全球化业务和跨文化交流场景具有不可估量的价值。传统ASR模型在处理方言和口音时常遇到瓶颈,而Qwen3-ASR-Flash通过其深厚的训练基础,有效克服了这些挑战,使得不同语言背景的用户都能享受到高质量的语音转写服务。
2. 突破性歌声识别能力
歌声识别一直是ASR领域的一大难点。由于歌声的音高变化、韵律节奏以及往往伴随的复杂背景音乐,使得将其准确转换为文本的挑战远超日常语音。Qwen3-ASR-Flash在此方面取得了突破性进展,不仅支持清唱的精确识别,还能在带有背景音乐的整歌识别中保持极高的准确性,实测错误率低于8%。这不仅为音乐创作、版权管理、卡拉OK应用等带来了新的可能,也展现了模型在处理非传统语音模式上的强大泛化能力。
3. 智能定制化识别:上下文语境的深度利用
在特定专业领域,准确识别专有名词、行业术语或特定人名地名至关重要。Qwen3-ASR-Flash通过引入定制化识别功能,允许用户提供任意格式的背景文本,如关键词列表、段落或完整文档。模型能够智能地利用这些上下文信息,进行命名实体匹配和其他关键术语的识别,从而输出高度定制化、更加符合特定语境的识别结果。这种能力显著提升了在医疗、法律、科技等专业场景下的识别精度与实用性,有效避免了误识和漏识,是实现垂直领域高效语音应用的关键一步。
4. 精准语种识别与非人声拒识
在实际应用中,语音数据往往夹杂着多种语言、静音片段或背景噪声。Qwen3-ASR-Flash具备精确分辨语音语种的能力,能够自动识别并标记出录音中的语言类型,这对于跨语言交流和多语言内容处理极为有用。同时,其非人声拒识功能能够智能过滤掉静音、背景音乐、环境噪声等非语音片段,确保输出的文本内容纯净且专注于有效信息,极大地提高了数据处理效率和文本质量。
5. 高鲁棒性:应对复杂声学环境与文本模式
真实世界的语音数据往往充满挑战:嘈杂的会议室、行进中的车辆、带有口音的讲话、复杂的长难句,甚至是口误和重复词语。Qwen3-ASR-Flash展现出卓越的高鲁棒性,在面对这些复杂声学环境(如车载噪声、多种类型噪声)和困难文本模式(如长难句、句中语言切换、重复词语)时,仍能保持高准确率。这得益于其海量多模态训练数据所赋予的强大抗干扰能力和语境理解能力,确保模型在各种严苛条件下都能稳定可靠地工作。
Qwen3-ASR-Flash的技术架构深层剖析
Qwen3-ASR-Flash之所以能实现上述突破,其背后是阿里通义在基础模型和数据训练上的深厚积累与创新。
1. 基于Qwen3基座模型的强大支撑
Qwen3-ASR-Flash构建于通义千问强大的Qwen3基座模型之上。Qwen3作为一个领先的多模态预训练模型,具备处理文本、语音、图像等多种类型数据的能力。这意味着Qwen3-ASR-Flash在语音识别任务中,能够继承基座模型对高级语义的理解能力,而不仅仅停留在声学特征的匹配,从而更深入地理解语音内容,实现更准确的转录。
2. 海量多模态数据训练的协同效应
模型的卓越性能离不开大规模、高质量的数据训练。Qwen3-ASR-Flash利用海量的多模态数据进行训练,这些数据涵盖了文本、语音、图像等多种类型,使得模型能够学习不同模态信息之间的内在关联。这种多模态训练方法,让模型在处理语音时,能够结合更丰富的背景知识和语境信息,从而提升识别的准确性和鲁棒性。
3. 千万小时规模的ASR数据精益求精
除了多模态数据,Qwen3-ASR-Flash还特别针对自动语音识别任务,进行了千万小时规模的ASR数据训练。这些数据广泛覆盖了多种语言、方言和口音,经过严格筛选和标注,确保了模型在声学模型和语言模型上的深度优化。这种大规模的专项训练,是Qwen3-ASR-Flash能够精准识别各种复杂语音模式的关键保障。
Qwen3-ASR-Flash的变革性应用范式
Qwen3-ASR-Flash的强大功能使其在多个行业和场景中展现出巨大的应用潜力,有望推动相关领域的数字化转型和效率提升。
1. 重塑会议记录与办公效率
在企业会议、学术研讨、政府决策等场景中,Qwen3-ASR-Flash能够实时、高精度地转写多语言会议内容,大幅提升会议纪要的整理效率和准确性。通过自动生成可检索的文本记录,不仅能节省人力成本,还能方便后期查阅和信息回顾,助力企业实现无纸化、智能化办公。
2. 推动在线教育的普惠与个性化
教育内容的传播不再受限于单一语言。Qwen3-ASR-Flash能将在线课程的语音讲解快速转写为文字,并支持多语种输出,满足不同语言背景学生的学习需求。这不仅提升了教育内容的无障碍性,也为学生提供了更加灵活的学习方式,如通过文本检索快速定位知识点,或将语音内容翻译成母语学习。
3. 升级智能客服体验与效率
将Qwen3-ASR-Flash集成到智能客服系统,可实现客户咨询的实时转写和语义分析。客服人员能够即时获取客户需求的关键信息,缩短响应时间,提高服务效率和客户满意度。同时,通过对转写文本的分析,企业可以更深入地洞察客户痛点和产品需求,优化服务流程。
4. 优化新闻采编与媒体传播
对于新闻机构和媒体行业,时效性至关重要。Qwen3-ASR-Flash能够精准、快速地转录采访录音、发布会讲话、直播节目等语音内容,大幅提升新闻报道的采编效率。这使得记者和编辑能够更快地整理素材、撰写稿件,确保新闻的及时发布,增强媒体的竞争力。
5. 提升医疗健康数据管理与辅助诊疗
在医疗领域,医生常常需要口述病历、诊断结果和治疗方案。Qwen3-ASR-Flash能够准确转写医生语音记录,减轻医护人员的文字录入负担,提高病历整理和数据分析的效率。其高精度和定制化能力,对于识别复杂的医学术语和病患口述信息具有重要意义,辅助医生更专注于诊疗本身,提升医疗服务质量。
未来展望:Qwen3-ASR-Flash在AI语音生态中的战略地位
Qwen3-ASR-Flash的发布,不仅展现了阿里通义在人工智能领域的技术实力和创新精神,更预示着语音识别技术正迈向一个更加智能、普惠的新阶段。随着AI技术的持续演进,ASR模型将不再仅仅是简单的语音转文字工具,而是成为深度理解语音内容、实现智能决策和多模态交互的核心引擎。Qwen3-ASR-Flash凭借其在多语种、高精度、定制化和鲁棒性方面的卓越表现,无疑将在构建未来智能语音生态系统中扮演关键角色,推动语音技术在更广阔的领域实现落地应用,最终赋能千行百业的数字化转型与智能化升级。

