
HunyuanWorld-Voyager:AI驱动的单图3D世界构建新范式
近年来,人工智能在内容创作领域的突破令人瞩目,尤其是在图像和视频生成方面。然而,让AI理解并构建具备空间深度和一致性的3D世界,始终是该领域的一大挑战。近期,腾讯HunyuanWorld-Voyager模型的发布,为这一难题提供了令人振奋的解决方案,它能够将一张普通的静态图片转化为一个可供“探索”的3D视频序列,极大地拓宽了我们对虚拟内容创作的想象空间。
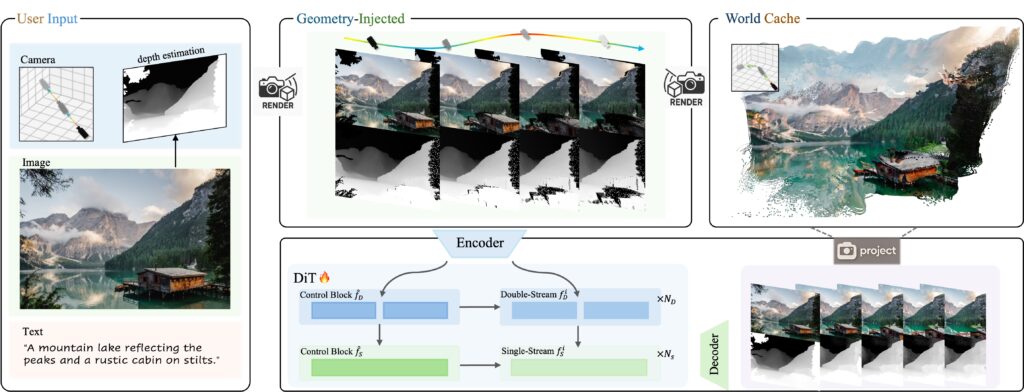
Voyager模型的创新之处在于其独特的工作机制。它并非直接生成一个传统意义上的3D模型,而是通过高精度的2D视频帧序列来模拟3D世界的运动和视角变化。用户只需提供一张起始图片,并定义好虚拟摄像机的移动路径(如前进、后退、左右平移或旋转),Voyager便能实时生成一段具有高度空间连贯性的视频。在这段视频中,场景中的物体会随着摄像机视角的移动,保持正确的相对位置和透视关系,仿佛摄像机正穿梭于一个真实的三维空间之中。


技术核心:深度与世界缓存
Voyager之所以能实现如此逼真的3D效果,离不开其两大核心技术支柱。首先,模型在生成RGB视频帧的同时,也同步生成了精确的深度信息。这意味着对于视频中的每一个像素,AI都“知道”它距离摄像机有多远。这种同步生成确保了视频的视觉内容与深度数据之间完美匹配,为后续的3D重建打下了坚实基础。尽管输出是带有深度图的视频,但这些数据可以进一步转换为3D点云,用于更深层次的3D重建工作。
其次,Voyager引入了一种名为“世界缓存”(World Cache)的机制。这是一个不断增长的3D点云集合,由模型根据先前生成的帧信息构建。当AI需要生成新的视频帧时,这个点云会从新的摄像机视角被重新投影到2D平面上,形成一个包含历史空间信息的参考图像。模型随后将这些投影作为几何一致性检查的依据,确保新生成的帧能够与之前的内容在空间上无缝衔接,避免了传统视频生成模型中常见的物体漂移或形变问题。
几何反馈循环:超越简单模式匹配
传统的AI视频生成模型,如OpenAI的Sora,通常侧重于生成逐帧之间视觉上连贯且逼真的画面,但在长时间序列或复杂视角变化下,往往难以保持精确的3D空间一致性。它们更多依赖于对训练数据中模式的模仿,而非对场景几何结构的“理解”。Voyager通过其独特的几何反馈循环机制,显著提升了空间一致性。
具体来说,Voyager在生成每一帧时,会将其输出转换为3D点,然后将这些点重新投影回2D平面,作为后续帧生成的参考。这种方法迫使模型将其学习到的模式与自身先前输出的几何一致性投影进行匹配。这虽然仍是一种基于模式匹配的方法,但通过引入强化的几何约束,极大地提高了生成视频的3D连贯性。这也是为什么Voyager可以在一定程度上维持数分钟的连贯性,但在处理360度全景旋转等极端视角变化时,仍可能因累积的微小误差而出现挑战。
训练策略:大规模数据与自动化流程
Voyager的卓越性能离不开其大规模的训练数据和高效的自动化训练流程。研究人员利用了超过10万个视频片段进行训练,这些数据不仅包含真实世界的录像,还融入了大量来自虚幻引擎(Unreal Engine)等计算机生成场景。这种混合数据集的策略,有效地教会了模型如何模拟摄像机在真实及虚拟3D环境中的运动模式,使其能够泛化到更广泛的场景。
为了高效处理如此庞大的数据,腾讯开发了一套自动化软件,能够自动分析现有视频,提取摄像机运动轨迹并计算每一帧的深度信息,从而省去了人工标注数千小时视频的繁重工作。这种数据处理的自动化,是实现大规模高质量AI模型训练的关键一环。
行业格局与应用前景
Voyager的发布,进一步丰富了世界生成模型的生态系统。此前,谷歌的Genie 3和Dynamics Lab的Mirage 2等模型也展示了各自在交互式世界生成方面的能力。Genie 3专注于生成用于AI智能体训练的交互式世界,而Mirage 2则致力于通过浏览器为用户提供图像转可玩环境的功能。相较而言,Voyager的独特之处在于其RGB-深度输出能力,使其在视频制作、电影后期制作以及3D重建等专业工作流中具有显著优势。
尽管Voyager展示了令人印象深刻的技术实力,但其对计算资源的需求也相当严苛。运行540p分辨率的模型至少需要60GB的GPU显存,而推荐配置则高达80GB。这表明,目前该模型主要面向具备高性能计算能力的专业用户和研究机构。不过,腾讯已经公开了模型权重,并提供了支持单GPU和多GPU并行推理的代码,通过xDiT框架,八个GPU的并行处理速度比单GPU快6.69倍,这在一定程度上缓解了性能瓶颈。
展望未来,Voyager这类技术无疑是构建更真实、更具交互性的虚拟世界的重要基石。虽然实现长时间、完全无瑕疵的实时交互体验仍需时日,但我们正目睹着一场由生成式AI引领的、全新的交互式艺术形式和内容创作模式的早期萌芽。随着硬件算力的提升和模型效率的优化,AI将持续重塑我们感知和创造数字内容的方式。

