
《瞬悉1.0:中科院类脑脉冲大模型如何革新超长序列处理与国产AI生态?》
5
颠覆性创新:SpikingBrain-1.0类脑脉冲大模型深度解析\n\n在人工智能飞速发展的今天,大模型已成为驱动技术革新的核心引擎。然而,传统基于Transformer架构的大模型在处理超长序列数据时,常常面临计算资源消耗巨大、推理效率低下等瓶颈。为了突破这些局限,中国科学院自动化研究所(CASIA)历经数年攻关,隆重推出了SpikingBrain-1.0(瞬悉1.0)——一款基于类脑脉冲神经网络(SNN)的划时代大模型。该模型不仅在技术架构上实现了创新,更在国产算力平台上完成了全流程训练与推理,为构建我国自主可控的人工智能生态奠定了坚实基础。\n\n
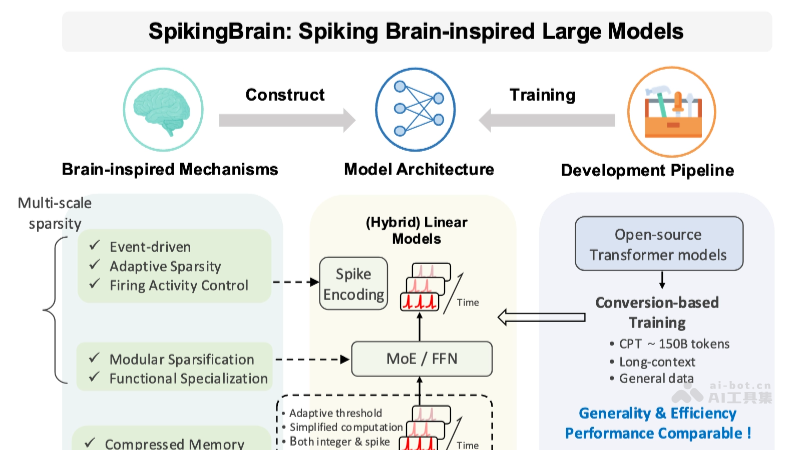 \n\nSpikingBrain-1.0的问世,标志着人工智能领域正从传统的“深度学习”范式向更接近生物智能的“类脑计算”范式迈进。它摆脱了Transformer的束缚,通过模拟生物神经元的脉冲信号传递机制,实现了对信息处理方式的根本性变革,从而在高效率、低能耗的道路上迈出了关键一步。\n\n### SpikingBrain-1.0的核心优势与技术突破\n\nSpikingBrain-1.0的强大能力源于其独特的架构设计和多项创新技术。其核心优势体现在以下几个方面:\n\n* 超长序列处理能力: 传统Transformer模型在处理长序列时,由于自注意力机制的平方复杂度,计算量随序列长度呈指数级增长。SpikingBrain-1.0则巧妙地避开了这一瓶颈,其新型非Transformer架构使其能够高效、稳定地处理超长序列数据,例如数万字的文章、长时间的音频流或复杂的交易数据序列,这在多模态理解和复杂任务处理中具有不可估量的价值。它不再受限于固定上下文窗口,极大地拓展了模型的应用边界。\n* 极低数据量高效训练: 在当今数据爆炸的时代,高质量、大规模标注数据依然是稀缺资源。SpikingBrain-1.0凭借其类脑脉冲神经网络的特性,展现出在极低数据量下进行高效学习的能力。这得益于SNN固有的事件驱动和稀疏激活机制,使其能够从有限样本中捕获更深层次的特征和规律,从而显著降低了模型的训练成本和对大规模数据集的依赖,为中小企业和科研机构提供了普惠的AI开发途径。\n* 推理效率数量级提升: SpikingBrain-1.0的推理过程相较于传统大模型具有数量级的效率提升。SNN的脉冲式计算特性使得模型在推理时能够更快速地收敛,并且在硬件层面上具有更低的功耗需求。这种高效性对于大规模部署和实时应用场景至关重要,例如在边缘设备上的AI推理、高并发的智能客服系统或需要即时响应的自动驾驶决策系统,都能展现出显著的性能优势。\n* 国产自主可控生态构建: SpikingBrain-1.0在全国产GPU算力平台上完成了从模型训练到推理的全流程验证。这一里程碑式的成就,不仅彰显了我国在核心AI技术领域的自主创新能力,更为构建一个完全自主可控的类脑大模型生态系统奠定了坚实基础。它有助于打破国外技术垄断,保障国家在人工智能战略发展中的信息安全和技术独立性,是推动国产AI硬件与软件协同发展的重要一步。\n\n### 深入探究SpikingBrain-1.0的技术原理\n\nSpikingBrain-1.0之所以能够实现上述突破,离不开其深厚的技术原理支撑:\n\n* 类脑脉冲神经网络(SNN): SpikingBrain-1.0的核心是类脑脉冲神经网络。与传统的基于连续激活值的深度学习网络不同,SNN模拟生物神经元通过离散的“脉冲”(spikes)进行信息传递。这种事件驱动的计算模式具有时间编码和稀疏激活的特点,使得信息处理更加高效和节能。它能够更好地捕捉动态时序信息,尤其适用于处理序列数据。\n* 新型非Transformer架构: 为了克服Transformer架构在处理超长序列时的计算复杂度和内存占用问题,SpikingBrain-1.0采用了全新的非Transformer架构。这种架构可能借鉴了循环神经网络(RNN)或卷积神经网络(CNN)的优势,并与SNN的特性深度融合,设计出能够有效处理长距离依赖关系、同时保持计算效率的新型拓扑结构。这避免了自注意力机制带来的二次复杂度瓶颈。\n* 内生复杂性原理: SpikingBrain-1.0基于内生复杂性原理进行设计。这意味着模型通过神经元之间的动态交互和自适应调整,而不是简单地堆叠层级,实现复杂功能的涌现。这种原理使得模型能够在学习过程中自我组织、自我演化,从而在有限的数据下展现出更强的泛化能力和鲁棒性,更接近生物大脑的学习机制。\n* 国产GPU算力平台: 模型的全流程训练和推理均在国产GPU算力平台上完成。这不仅验证了SpikingBrain-1.0在国产硬件上的卓越兼容性和性能表现,也促进了国产AI芯片和框架的成熟与发展。在硬件层面的自主可控是实现整个AI生态系统自主可控的关键一环,为国家的数字基础设施安全提供了有力保障。\n\n### SpikingBrain-1.0的广阔应用前景与深远影响\n\nSpikingBrain-1.0的创新技术使其在多个行业领域展现出巨大的应用潜力和深远的社会影响:\n\n* 自然语言处理(NLP): 在智能客服、文本摘要、机器翻译等领域,SpikingBrain-1.0能够快速理解和处理用户的超长文本输入,例如法律文书、科研论文或医学报告,显著提升了信息抽取和语义理解的深度与效率。它能更精准地把握长篇对话的上下文,提供更连贯、更个性化的交互体验。\n* 语音处理与识别: 在智能语音助手、会议转录、实时翻译等应用中,SpikingBrain-1.0能够准确识别和理解长时间的语音指令或对话内容。其高效的时序处理能力使其能够更好地捕捉语速变化、语气情感等细微特征,从而大幅提升语音识别的准确率和自然度,广泛应用于智能家居和车载系统。\n* 金融科技: 在风险评估、市场预测和量化交易等场景中,通过分析长周期的金融数据,如股票走势、交易记录和宏观经济报告,SpikingBrain-1.0能够洞察更深层次的潜在风险和市场趋势。它能够从海量非结构化数据中提取关键信号,为投资决策和风控管理提供更为精准、实时的支持。\n* 智能交通: 在交通流量预测、智能信号灯控制和自动驾驶路径规划上,SpikingBrain-1.0能够分析长周期的历史交通数据、实时路况以及天气信息。其强大的序列建模能力有助于精准预测交通拥堵模式、优化路线规划,甚至辅助自动驾驶车辆在复杂环境中做出更安全、更高效的决策。\n* 医疗健康: 在疾病诊断、药物研发和个性化治疗方案制定过程中,通过分析患者长期的医疗记录、基因组数据、生理信号(如心电图、脑电图),SpikingBrain-1.0能够辅助医生进行早期疾病预警和精准诊断。它能够识别病理模式中的微弱信号,为医生提供更全面的参考,从而提升医疗服务的质量和效率。\n\n### 展望:类脑计算引领AI新纪元\n\nSpikingBrain-1.0的发布,不仅是一项重大的技术成就,更是对未来人工智能发展方向的一次深刻探索。它以类脑脉冲神经网络为核心,成功地在超长序列处理、低数据量训练和高效率推理方面取得了突破,展示了类脑计算在解决传统深度学习瓶颈方面的巨大潜力。随着类脑计算理论的不断完善和硬件技术的持续发展,我们有理由相信,以SpikingBrain-1.0为代表的类脑大模型将逐步成为推动人工智能向前发展的重要力量。它将不仅仅是计算工具的革新,更是对智能本质理解的深化,预示着一个更高效、更节能、更智能的AI新范式的到来。未来,我们期待SpikingBrain-1.0能在更多领域开花结果,为构建万物智联的社会贡献中国智慧和力量。
\n\nSpikingBrain-1.0的问世,标志着人工智能领域正从传统的“深度学习”范式向更接近生物智能的“类脑计算”范式迈进。它摆脱了Transformer的束缚,通过模拟生物神经元的脉冲信号传递机制,实现了对信息处理方式的根本性变革,从而在高效率、低能耗的道路上迈出了关键一步。\n\n### SpikingBrain-1.0的核心优势与技术突破\n\nSpikingBrain-1.0的强大能力源于其独特的架构设计和多项创新技术。其核心优势体现在以下几个方面:\n\n* 超长序列处理能力: 传统Transformer模型在处理长序列时,由于自注意力机制的平方复杂度,计算量随序列长度呈指数级增长。SpikingBrain-1.0则巧妙地避开了这一瓶颈,其新型非Transformer架构使其能够高效、稳定地处理超长序列数据,例如数万字的文章、长时间的音频流或复杂的交易数据序列,这在多模态理解和复杂任务处理中具有不可估量的价值。它不再受限于固定上下文窗口,极大地拓展了模型的应用边界。\n* 极低数据量高效训练: 在当今数据爆炸的时代,高质量、大规模标注数据依然是稀缺资源。SpikingBrain-1.0凭借其类脑脉冲神经网络的特性,展现出在极低数据量下进行高效学习的能力。这得益于SNN固有的事件驱动和稀疏激活机制,使其能够从有限样本中捕获更深层次的特征和规律,从而显著降低了模型的训练成本和对大规模数据集的依赖,为中小企业和科研机构提供了普惠的AI开发途径。\n* 推理效率数量级提升: SpikingBrain-1.0的推理过程相较于传统大模型具有数量级的效率提升。SNN的脉冲式计算特性使得模型在推理时能够更快速地收敛,并且在硬件层面上具有更低的功耗需求。这种高效性对于大规模部署和实时应用场景至关重要,例如在边缘设备上的AI推理、高并发的智能客服系统或需要即时响应的自动驾驶决策系统,都能展现出显著的性能优势。\n* 国产自主可控生态构建: SpikingBrain-1.0在全国产GPU算力平台上完成了从模型训练到推理的全流程验证。这一里程碑式的成就,不仅彰显了我国在核心AI技术领域的自主创新能力,更为构建一个完全自主可控的类脑大模型生态系统奠定了坚实基础。它有助于打破国外技术垄断,保障国家在人工智能战略发展中的信息安全和技术独立性,是推动国产AI硬件与软件协同发展的重要一步。\n\n### 深入探究SpikingBrain-1.0的技术原理\n\nSpikingBrain-1.0之所以能够实现上述突破,离不开其深厚的技术原理支撑:\n\n* 类脑脉冲神经网络(SNN): SpikingBrain-1.0的核心是类脑脉冲神经网络。与传统的基于连续激活值的深度学习网络不同,SNN模拟生物神经元通过离散的“脉冲”(spikes)进行信息传递。这种事件驱动的计算模式具有时间编码和稀疏激活的特点,使得信息处理更加高效和节能。它能够更好地捕捉动态时序信息,尤其适用于处理序列数据。\n* 新型非Transformer架构: 为了克服Transformer架构在处理超长序列时的计算复杂度和内存占用问题,SpikingBrain-1.0采用了全新的非Transformer架构。这种架构可能借鉴了循环神经网络(RNN)或卷积神经网络(CNN)的优势,并与SNN的特性深度融合,设计出能够有效处理长距离依赖关系、同时保持计算效率的新型拓扑结构。这避免了自注意力机制带来的二次复杂度瓶颈。\n* 内生复杂性原理: SpikingBrain-1.0基于内生复杂性原理进行设计。这意味着模型通过神经元之间的动态交互和自适应调整,而不是简单地堆叠层级,实现复杂功能的涌现。这种原理使得模型能够在学习过程中自我组织、自我演化,从而在有限的数据下展现出更强的泛化能力和鲁棒性,更接近生物大脑的学习机制。\n* 国产GPU算力平台: 模型的全流程训练和推理均在国产GPU算力平台上完成。这不仅验证了SpikingBrain-1.0在国产硬件上的卓越兼容性和性能表现,也促进了国产AI芯片和框架的成熟与发展。在硬件层面的自主可控是实现整个AI生态系统自主可控的关键一环,为国家的数字基础设施安全提供了有力保障。\n\n### SpikingBrain-1.0的广阔应用前景与深远影响\n\nSpikingBrain-1.0的创新技术使其在多个行业领域展现出巨大的应用潜力和深远的社会影响:\n\n* 自然语言处理(NLP): 在智能客服、文本摘要、机器翻译等领域,SpikingBrain-1.0能够快速理解和处理用户的超长文本输入,例如法律文书、科研论文或医学报告,显著提升了信息抽取和语义理解的深度与效率。它能更精准地把握长篇对话的上下文,提供更连贯、更个性化的交互体验。\n* 语音处理与识别: 在智能语音助手、会议转录、实时翻译等应用中,SpikingBrain-1.0能够准确识别和理解长时间的语音指令或对话内容。其高效的时序处理能力使其能够更好地捕捉语速变化、语气情感等细微特征,从而大幅提升语音识别的准确率和自然度,广泛应用于智能家居和车载系统。\n* 金融科技: 在风险评估、市场预测和量化交易等场景中,通过分析长周期的金融数据,如股票走势、交易记录和宏观经济报告,SpikingBrain-1.0能够洞察更深层次的潜在风险和市场趋势。它能够从海量非结构化数据中提取关键信号,为投资决策和风控管理提供更为精准、实时的支持。\n* 智能交通: 在交通流量预测、智能信号灯控制和自动驾驶路径规划上,SpikingBrain-1.0能够分析长周期的历史交通数据、实时路况以及天气信息。其强大的序列建模能力有助于精准预测交通拥堵模式、优化路线规划,甚至辅助自动驾驶车辆在复杂环境中做出更安全、更高效的决策。\n* 医疗健康: 在疾病诊断、药物研发和个性化治疗方案制定过程中,通过分析患者长期的医疗记录、基因组数据、生理信号(如心电图、脑电图),SpikingBrain-1.0能够辅助医生进行早期疾病预警和精准诊断。它能够识别病理模式中的微弱信号,为医生提供更全面的参考,从而提升医疗服务的质量和效率。\n\n### 展望:类脑计算引领AI新纪元\n\nSpikingBrain-1.0的发布,不仅是一项重大的技术成就,更是对未来人工智能发展方向的一次深刻探索。它以类脑脉冲神经网络为核心,成功地在超长序列处理、低数据量训练和高效率推理方面取得了突破,展示了类脑计算在解决传统深度学习瓶颈方面的巨大潜力。随着类脑计算理论的不断完善和硬件技术的持续发展,我们有理由相信,以SpikingBrain-1.0为代表的类脑大模型将逐步成为推动人工智能向前发展的重要力量。它将不仅仅是计算工具的革新,更是对智能本质理解的深化,预示着一个更高效、更节能、更智能的AI新范式的到来。未来,我们期待SpikingBrain-1.0能在更多领域开花结果,为构建万物智联的社会贡献中国智慧和力量。 最新文章
最新文章 
SSVAE:智谱AI开源频谱结构化变分自编码器革新视频生成
9小时前
LLaDA 2.0:蚂蚁集团突破性开源离散扩散大语言模型
9小时前
Claude-Mem:重塑AI开发体验的长期记忆插件
9小时前
Gemini TTS深度解析:谷歌AI语音技术的革新与应用
9小时前
OpenScreen:开源屏幕录制工具,打造专业级视频内容
9小时前
Paper2Slides:港大开源AI工具革新学术幻灯片制作
9小时前
Wan-Move:阿里清华开源运动可控视频生成新范式
9小时前
UnityVideo:港科大与快手可灵开源的多模态视频生成革命
9小时前
LightX2V:商汤开源实时视频生成框架的技术突破与应用前景
9小时前
AI技术新突破:视频编辑自动化与多模态模型引领行业变革
9小时前