
AI技术在内容创作领域的迭代速度令人惊叹,其中,腾讯HunyuanWorld-Voyager模型无疑是近期备受瞩目的创新之一。这款开源AI模型能够将单一图片转化为可供用户“探索”的3D风格视频序列,为虚拟场景的生成和互动体验开辟了新的路径。它通过独特的机制,在无需传统3D建模的情况下,实现了对空间一致性的精确模拟,预示着智能内容生成技术在重塑数字世界方面的巨大潜力。
Voyager模型的核心能力在于其能够从一张静态图片出发,生成RGB视频与深度信息并行的序列。这意味着当视频帧显示出某个物体时,同步的深度数据会精确地指示该物体与摄像机的距离。这种一体化生成方式,使得输出的视频在视觉上呈现出仿佛摄像机在真实3D空间中移动的效果,尽管其本质仍是2D视频帧的巧妙组合。生成的每个序列通常包含49帧,约两秒时长,但通过串联多个片段,可延长至数分钟。在这些序列中,物体在相对位置上保持稳定,透视关系也随摄像机运动而正确变化,极大增强了沉浸感。尽管并非真正的3D模型,但这些包含深度信息的视频可以被转换为3D点云,为后续的3D重建工作提供了直接支持。
实现这种高度空间一致性的关键在于Voyager独特的工作流。系统接收一张输入图像和一个由用户定义的摄像机轨迹——例如前进、后退、左右移动或旋转。在此基础上,Voyager结合图像、深度数据以及一个高效的“世界缓存”(world cache)来生成视频序列。世界缓存是一个不断增长的3D点云集合,由之前生成的帧创建。当生成新帧时,这个点云会从新的摄像机视角重新投影回2D平面,形成一个“预期视图”,指示基于前序帧应该看到什么。模型随后利用这些投影作为一致性检查,确保新生成的帧与之前的内容在几何上完美对齐。
相较于多数依赖Transformer架构的AI模型,Voyager在处理空间一致性方面展现了显著的进步。传统的Transformer模型擅长模仿训练数据中的模式,但在应用于训练数据未包含的新颖场景时,其泛化能力会受到限制,尤其在视频生成中常常难以维持帧间的空间逻辑。例如,像Sora这样的多数AI视频生成器,虽然能生成逼真的连续帧,但通常不会主动追踪或维持场景的严格空间一致性。Voyager则通过引入几何反馈循环,迫使模型将自身学习到的模式与几何一致的、来自其自身此前输出的投影进行匹配。这种机制极大地提升了空间连贯性,使其能够维持数分钟的场景一致性。然而,这也并非完美无瑕。例如,在全360度旋转等复杂运动中,模式匹配中的微小误差会随着帧数累积,最终可能导致几何约束难以维持整体连贯性。这进一步强调了尽管技术先进,模型仍基于模式学习,而非真正的三维“理解”。
Voyager的训练过程也体现了其创新性。研究人员开发了一套自动化数据处理流程,能够自动分析现有视频,计算每一帧的摄像机运动和深度信息,从而省去了人工标注大量素材的繁重工作。该系统处理了超过10万个视频片段,这些数据源自真实世界录像和虚幻引擎(Unreal Engine)渲染的计算机生成场景。通过对虚幻引擎数据的学习,模型能够模仿摄像机在3D游戏环境中的移动方式,从而有效地捕捉和再现3D空间的动态模式。此模型也是腾讯“混元”(Hunyuan)生态系统的重要组成部分,该生态系统还包括用于文本到3D生成的Hunyuan3D-2模型和视频合成的HunyuanVideo模型,共同构建了一个全面的智能内容创作平台。
在与其他世界生成模型的对比中,Voyager展现了独特的定位。例如,Google在2025年8月发布的Genie 3世界模型,能够从文本提示生成720p分辨率、24fps的实时交互式世界,并支持数分钟的实时导航。而Dynamics Lab的Mirage 2则提供基于浏览器的世界生成服务,允许用户上传图片并利用实时文本提示将其转化为可玩环境。虽然Genie 3主要面向AI代理训练且未公开,Mirage 2侧重用户生成内容和游戏体验,Voyager则凭借其RGB-深度输出能力,更专注于视频制作和3D重建工作流,填补了这一领域的空白。
尽管技术先进,Voyager的部署和运行仍面临显著挑战。该模型对计算能力要求极高,运行540p分辨率至少需要60GB的GPU显存,而腾讯官方建议使用80GB以获得更优效果。这使得其在消费级硬件上的普及存在障碍。此外,模型附带的许可限制也值得关注:它禁止在欧盟、英国和韩国使用,并且针对每月活跃用户超过1亿的商业部署需要单独向腾讯申请授权。这些限制可能会影响其在全球范围内的推广和应用。
在斯坦福大学研究人员开发的WorldScore基准测试中,Voyager的整体得分高达77.62,超越了WonderWorld的72.69和CogVideoX-I2V的62.15。具体而言,它在物体控制(66.92)、风格一致性(84.89)和主观质量(71.09)方面表现出色,而在摄像机控制(85.95)上略低于WonderWorld的92.98。WorldScore基准综合评估了世界生成方法的3D一致性和内容对齐度等多个标准,这些结果证实了Voyager在多个维度上的领先地位。为了应对高算力需求,系统支持使用xDiT框架在多GPU设置下进行并行推理,例如在八块GPU上运行可将处理速度提升6.69倍。

图:Voyager生成视频序列静止画面。来源:腾讯

图:Voyager生成视频序列静止画面。来源:腾讯
尽管目前Voyager仍需强大的计算资源,且在生成长时间、高度连贯的“世界”方面存在局限,但它代表了人工智能在生成交互式数字内容方面迈出的重要一步。这种将单张图片转化为可探索3D风格视频的能力,不仅在视觉效果上令人印象深刻,更在底层技术上探索了空间一致性和几何约束的新范式。随着未来硬件性能的提升和算法的进一步优化,我们有理由相信,类似于Voyager这样的技术将逐渐克服当前的挑战,并在电影制作、游戏开发、虚拟现实体验以及建筑可视化等多个领域催生出全新的交互式、生成式艺术形式,彻底改变我们与数字内容互动的方式。这不仅仅是技术进步,更是一场关于如何感知和构建虚拟世界的深刻变革。
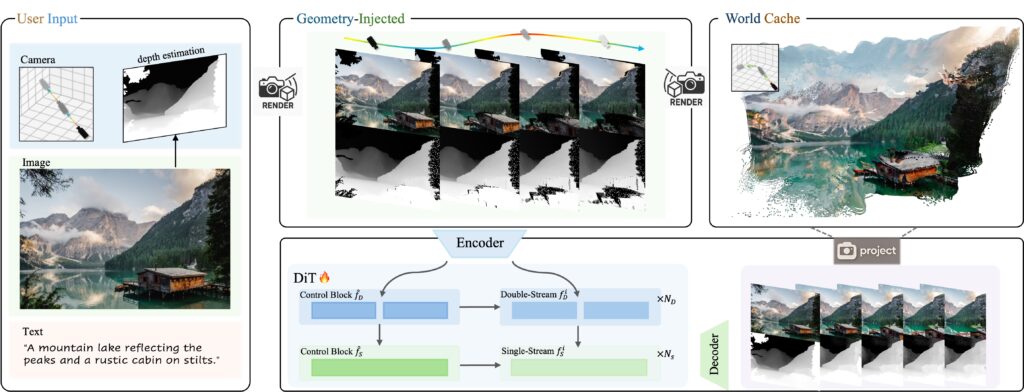
图:Voyager世界创建流程图。来源:腾讯

