
大型语言模型推理引擎的痛点:模型权重更新挑战
随着大型语言模型(LLM)的规模持续扩大,其在各个应用领域展现出前所未有的能力。然而,在实际部署和运行中,如何高效、实时地更新这些庞大模型的权重,以适应最新的数据、修复潜在问题或集成新的知识,一直是一个极具挑战性的工程难题。传统的模型更新方式往往涉及停机、重新加载整个模型,这在追求低延迟、高可用性的生产环境中是不可接受的。特别是在强化学习(RL)等需要频繁迭代和策略更新的场景中,模型权重的动态调整对于训练效率和收敛速度至关重要。
当模型参数达到万亿级别时,即使是微小的更新也可能意味着巨大的数据传输和同步开销。每一次完整的模型加载或重启服务都会导致显著的停机时间,从而影响用户体验并增加运营成本。因此,业界长期以来都在寻求一种能够实现模型权重“原地热更新”的解决方案,即在不中断服务的前提下,对模型参数进行高效、原子级的修改。
月之暗面“Checkpoint Engine”:革新性中间件的诞生
面对这一关键技术瓶颈,人工智能领域的创新力量月之暗面(MoonshotAI)近期发布了一款名为“Checkpoint Engine”的革命性中间件。该工具专为大型语言模型推理引擎设计,旨在彻底改变模型权重的管理和更新范式。Checkpoint Engine的核心价值在于其能够实现模型权重的原地热更新,显著提升了模型迭代的灵活性和效率。
万亿参数的极速同步能力
Checkpoint Engine最令人瞩目的成就之一,是其在性能方面的突破。根据月之暗面公开的数据,该中间件能够在仅仅约20秒内,完成对拥有万亿参数的Kimi-K2模型进行权重同步。更令人惊叹的是,这一高效过程可以在数千个GPU上同时进行,展现出卓越的分布式处理能力。这意味着,即便面对超大规模的模型和集群,Checkpoint Engine也能确保模型权重更新的快速响应,大幅缩短了强化学习训练过程中所需的停机时间,从而显著提升了整体的训练和部署效率。这种级别的性能,为LLM在实时应用中的快速适应性奠定了坚实基础。
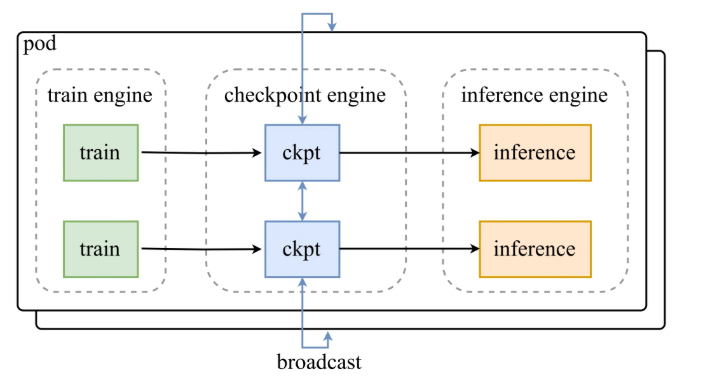
开放性与兼容性:构建AI生态的关键
除了卓越的性能,Checkpoint Engine在设计上还充分考虑了开放性和兼容性。目前,该中间件已经与vLLM深度集成。vLLM作为当前流行的LLM推理框架,以其高效的注意力机制和批处理能力而闻名。Checkpoint Engine与vLLM的无缝协作,意味着开发者可以在不牺牲vLLM原有性能优势的前提下,获得模型权重热更新的能力。这对于已经在vLLM生态中构建应用的团队来说,无疑是一个巨大的利好。
此外,Checkpoint Engine的接口设计非常灵活和通用,方便未来扩展到其他主流的LLM推理框架,例如SGLang。这种前瞻性的设计理念,不仅体现了月之暗面在推动技术进步方面的雄心,也为整个AI社区提供了一个可插拔、可扩展的基础设施组件。通过支持更广泛的框架,Checkpoint Engine有望成为AI推理引擎权重管理领域的通用解决方案,促进不同技术栈之间的互操作性。
技术深度剖析:Checkpoint Engine如何实现高效热更新?
实现万亿参数模型的原地热更新,绝非易事。Checkpoint Engine背后的技术原理必然涉及多个层面的创新。尽管官方尚未公布详尽的技术白皮书,但我们可以基于其宣称的性能指标,推断其可能采用的关键技术路径:
- 增量式权重更新:而非每次都传输和加载整个模型,Checkpoint Engine很可能采用了一种增量更新机制。它只识别并同步模型中发生变化的参数部分,而非所有参数。这极大地减少了数据传输量和处理时间。
- 分布式快照与同步:在数千个GPU上同步万亿参数,需要一个高度优化的分布式系统架构。Checkpoint Engine可能利用分布式一致性算法和高效的数据传输协议(如RDMA)来确保所有GPU上的模型副本能够快速且一致地更新。它可能不是对所有参数进行检查点,而是针对特定层或模块进行快照,并通过优化的网络拓扑进行广播。
- 内存管理与I/O优化:模型权重通常存储在GPU显存中。实现热更新需要精妙的内存管理策略,例如双缓冲(double buffering)或异步加载,以避免在更新过程中阻塞推理任务。同时,高效的磁盘I/O和内存映射技术也能加速权重数据的载入。
- 无锁或弱锁机制:为了最大限度地减少更新过程中的性能开销,Checkpoint Engine可能采用了无锁(lock-free)或弱锁(weakly consistent)的数据结构和算法,允许推理任务在权重更新的并行进行,或在极短的停顿后恢复。对于LLM推理而言,这可能意味着在极短的时间窗口内切换到新权重,从而达到“原地”和“热”的效果。
- 元数据管理:高效地跟踪模型权重的版本、变化历史以及在分布式系统中的分布状态,对于确保更新的正确性和可回溯性至关重要。Checkpoint Engine必然包含一个健壮的元数据管理系统。
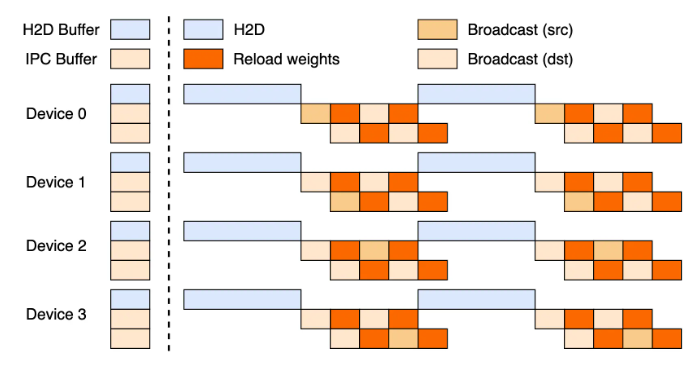
Checkpoint Engine的深远影响与未来展望
月之暗面开源Checkpoint Engine,不仅是对LLM推理技术的一次重大贡献,更是对整个AI生态系统的一次积极推动。其影响将是多方面的:
1. 加速强化学习与持续学习进程
在强化学习中,智能体通过与环境的交互来学习策略,这需要策略模型能够频繁地更新。Checkpoint Engine的出现,将极大缩短每次策略更新造成的停机时间,使得RL训练能够以更高的频率、更低的延迟进行。这将加速RL算法的研发与落地,尤其是在机器人控制、自动驾驶、金融交易等对实时性要求极高的领域。
此外,对于大型模型的持续学习(Continual Learning)和在线微调(Online Fine-tuning),Checkpoint Engine也提供了强有力的支持。模型可以根据新的数据流或用户反馈,实时地调整其内部权重,而无需中断服务。这使得LLM能够更好地适应动态变化的现实世界,保持知识的新鲜度和准确性。
2. 优化MloPs与模型部署流程
对于MLOps(机器学习运维)团队而言,Checkpoint Engine将极大地简化模型部署和维护的复杂性。它消除了传统模型更新带来的停机窗口和复杂的版本回滚策略,使得A/B测试、灰度发布等操作更为顺畅。运维人员可以更自信地进行模型更新,降低因更新导致的潜在风险和运维成本。
3. 促进AI基础设施的标准化与开放
作为开源项目,Checkpoint Engine的发布有望吸引全球开发者社区的参与。社区的贡献将加速其功能的完善、性能的优化以及对更多框架的支持。这不仅有助于CheckEngine自身的发展,更可能推动LLM推理引擎中权重管理模块的标准化,为整个AI基础设施的构建提供一个通用的、高性能的解决方案。
4. 驱动AI应用场景的创新
高效的模型热更新能力,将直接赋能一系列新兴的AI应用。例如,个性化AI助手可以实时学习用户的偏好并调整其行为;智能推荐系统能够即时响应市场变化并更新推荐策略;工业自动化系统可以根据实时传感器数据,快速调整控制模型。这些应用都对模型的实时适应性提出了极高要求,而Checkpoint Engine正是实现这一目标的关键技术之一。
结语:迈向更加智能、灵活的AI未来
月之暗面“Checkpoint Engine”的开源,不仅仅是技术上的进步,更是对AI未来发展路径的一次重要指引。它解决了长期困扰大规模语言模型部署的核心难题,使得AI模型能够以更快的速度、更低的成本、更灵活的方式进行迭代和适应。我们有理由相信,这项创新将为人工智能领域注入新的活力,加速各种智能应用的落地,共同推动AI技术迈向一个更加智能、灵活、实用的新阶段。

