
引言:混合架构大模型Qwen3-Next的时代意义
在人工智能飞速发展的今天,大模型已成为技术创新的核心驱动力。然而,传统大模型在追求卓越性能的同时,也面临着高昂的计算资源消耗和推理延迟等挑战。正是在这样的背景下,阿里通义团队推出的Qwen3-Next系列混合架构大模型,以其前瞻性的设计理念和卓越的工程实践,为业界提供了解决之道。Qwen3-Next,作为新一代开源大模型的代表,不仅继承了通义千问系列在语言理解和生成方面的深厚积累,更通过引入全球首创的Gated DeltaNet与Gated Attention混合架构,重新定义了AI大模型在效率、性能与资源消耗之间的平衡点。该模型包含指令版(Qwen3-Next-80B-A3B-Instruct)和思维版(Qwen3-Next-80B-A3B-Thinking)两个版本,旨在满足不同应用场景对指令执行和深度推理的差异化需求。其总参数量高达80B,却能实现每次推理仅激活约3B参数的惊人效率,这无疑是AI大模型发展历程中的一个里程碑式突破,预示着一个更加智能、高效且普惠的AI新时代。
Qwen3-Next核心创新:Gated DeltaNet与Gated Attention深度解析
Qwen3-Next最引人注目的技术亮点,莫过于其独树一帜的Gated DeltaNet和Gated Attention混合架构。这种架构设计并非简单的功能叠加,而是深思熟虑后对大模型固有局限性的策略性应对。它旨在优化长文本处理能力,同时兼顾推理速度与关键信息召回的精准度。
混合架构设计理念
Qwen3-Next的混合架构由75%的Gated DeltaNet和25%的Gated Attention组成,这种比例分配是基于对不同组件优势的精妙权衡。Gated DeltaNet擅长处理序列依赖和长距离上下文,它以更快的推理速度和线性增长的内存占用,有效解决了传统Attention机制在处理超长文本时计算复杂度呈平方级增长的问题。与此同时,Gated Attention则专注于精确地捕捉和召回文本中的核心信息,确保模型在处理冗长内容时不会遗漏关键细节。二者协同工作,形成了一个既高效又精准的“混合动力引擎”,使得Qwen3-Next在面对复杂、冗长的输入时,依然能够保持卓越的理解和生成能力。这种创新性的架构设计,不仅是技术上的突破,更是对大模型架构优化方向的深刻思考。
Gated DeltaNet:长文本处理的效率引擎
Gated DeltaNet可以被形象地理解为大模型处理长文本的“高速公路”。其核心优势在于能够以更低的计算成本和更快的速度处理大规模的序列数据。在传统的Transformer架构中,Attention机制是计算瓶颈,尤其在上下文长度增加时,资源消耗会急剧上升。Gated DeltaNet通过门控机制和局部注意力等技术,有效地降低了这种依赖,使得模型在处理32K甚至更长上下文时,能够保持稳定的高效运行。这对于需要处理大量文档、报告或对话历史的应用场景而言,具有非凡的价值,显著提升了模型的实用性和泛化能力。它为模型在处理超长文本任务时提供了坚实的效率保障。
Gated Attention:关键信息召回的精度保障
尽管Gated DeltaNet提供了高速处理能力,但在某些需要精准捕捉特定信息或进行细致推理的任务中,传统的Attention机制仍有其不可替代的优势。Gated Attention便是扮演了这一“精密雷达”的角色。它负责在Gated DeltaNet快速处理的基础上,对关键区域进行更细致的关注,确保模型能够准确地识别和提取重要概念、实体或逻辑关系。这种协同工作方式,使得Qwen3-Next在保证整体推理速度的同时,也能够避免因文本过长而导致的“信息丢失”或“精度下降”问题。特别是在需要深度理解、多步推理的复杂场景中,Gated Attention的精准召回能力成为了模型性能的关键支撑。
极致效率与资源优化:80B模型参数的智能激活机制
Qwen3-Next的另一大创新在于其极致的资源节省能力,这主要得益于其智能的参数激活机制和专家系统(MoE)设计。
MoE专家系统的动态选择
Qwen3-Next模型总参数量高达80B,但这并非意味着每次推理都需要激活所有参数。其采用的MoE(Mixture of Experts)专家系统是实现高效的关键。模型内包含512个专家网络,在每次处理用户请求时,它会动态地选择最相关的10个专家和1个共享专家来共同工作。这种按需激活的机制,使得每次推理实际上只消耗了约3B参数的计算资源。这种“按需分配”的模式,不仅显著降低了单个推理请求的计算成本和延迟,也使得模型在面对高并发场景时,能够实现更优的负载均衡和资源管理。这对于追求经济效益和可扩展性的企业级应用而言,无疑是极具吸引力的特性。
MTP预训练加速与长文生成
为了进一步提升长文本生成的效率,Qwen3-Next引入了原生的MTP(Multi-Token Prediction)预训练加速技术。传统的语言模型在预训练阶段一次只预测一个token,这在生成长文本时会导致推理步数过多,从而降低吞吐量。MTP技术则允许模型在预训练阶段就能一次性预测多个token,这在推理时意味着可以减少生成相同长度文本所需的迭代次数。通过这种机制,Qwen3-Next在生成长文本时的速度得到了显著提升,尤其适用于需要快速生成大量内容的场景,如新闻稿件撰写、报告总结或创意文本生成等。MTP与混合架构的结合,共同构筑了Qwen3-Next在效率上的强大护城河。
性能超越与应用潜力:Qwen3-Next的基准表现与多领域赋能
Qwen3-Next在多项行业基准测试中展现出了令人瞩目的性能表现,彰显了其作为新一代大模型的卓越实力。
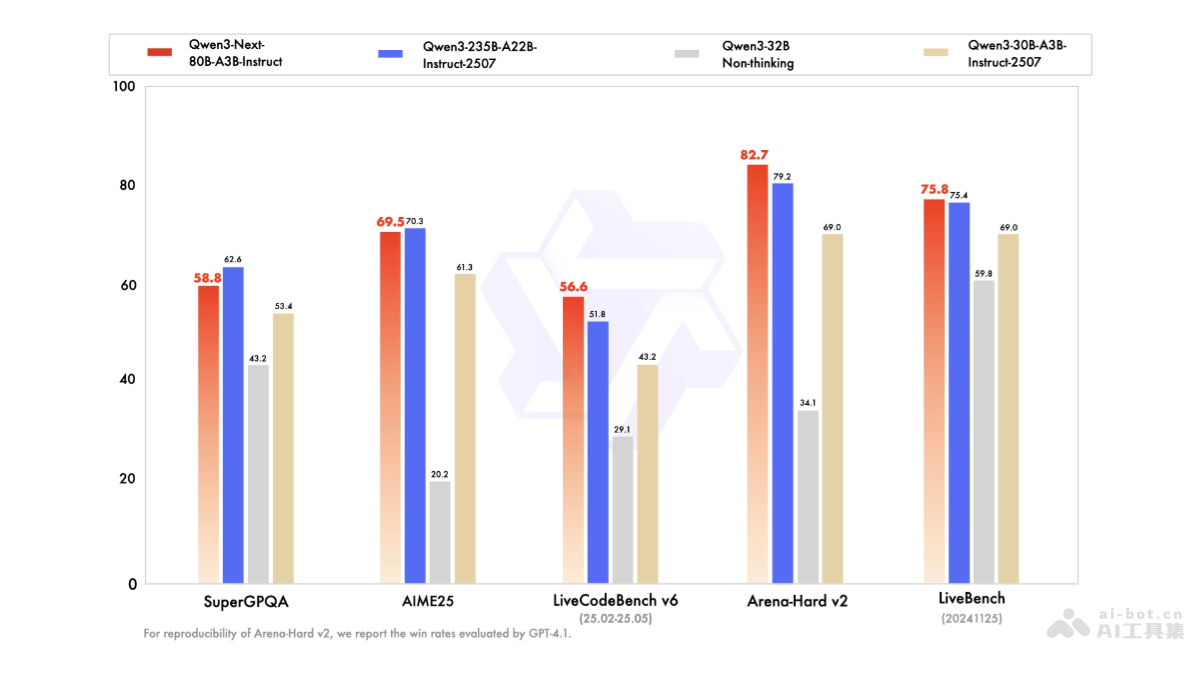
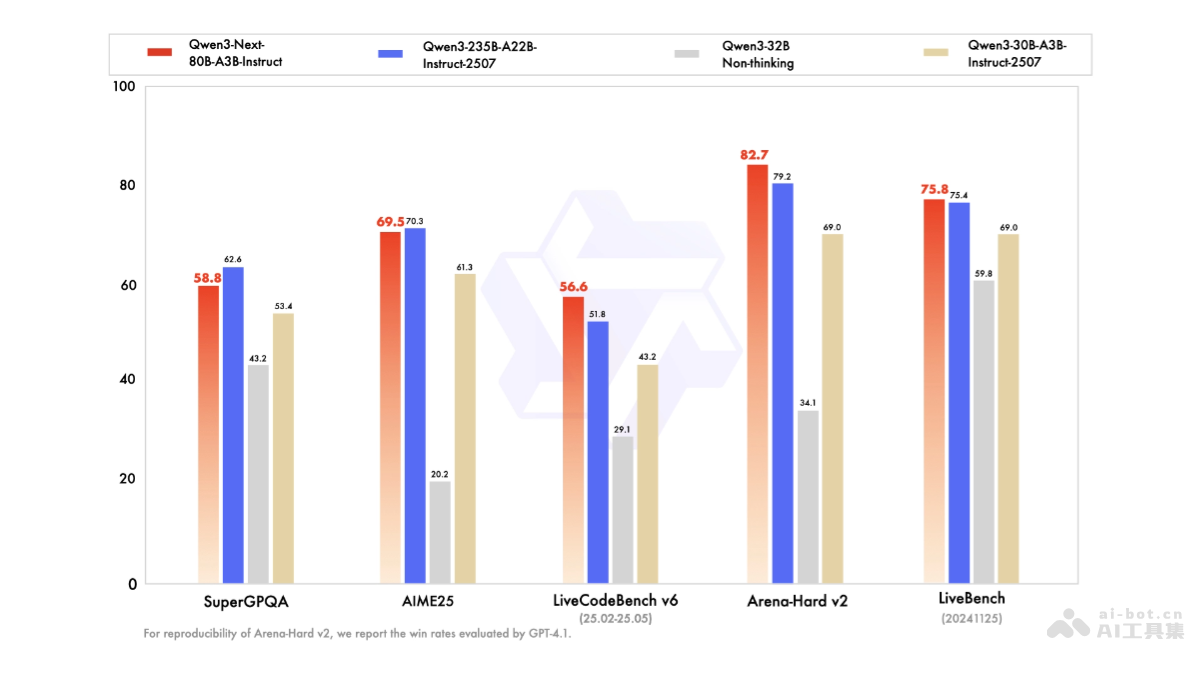
指令与思维模型的卓越能力
具体而言,Qwen3-Next-80B-A3B-Instruct 模型在指令理解和执行能力上,展现出与235B旗舰模型相媲美的水平,并在处理长文本方面甚至表现更强。这意味着它能够更准确地理解用户的复杂指令,并生成高质量、符合预期的回应。而Qwen3-Next-80B-A3B-Thinking 模型则在深度推理能力上超越了Gemini Flash等竞品,部分指标甚至逼近了235B旗舰模型。这表明Qwen3-Next在需要多步逻辑推理、复杂问题解决等高阶认知任务中,具有显著优势。这种双版本策略,使得用户可以根据具体的任务需求,选择最适合的模型版本,从而最大化模型的应用价值。
多元化应用场景的深度拓展
Qwen3-Next的强大能力使其在多个关键应用领域展现出巨大的潜力:
- 智能客服:凭借卓越的指令理解和长文本处理能力,Qwen3-Next能够为企业构建更智能、更人性化的自动化客服系统。它可以精准理解用户意图,快速检索知识库,并提供个性化的解决方案,大幅提升客户满意度和服务效率。
- 内容生成:无论是新闻稿件、市场文案、创意故事还是技术文档,Qwen3-Next都能根据用户需求,快速生成高质量、高原创度的文本内容。其长文本处理能力尤其适用于需要生成长篇报告、书籍章节或深度分析文章的场景,极大地解放了内容创作者的生产力。
- 数据分析:数据分析人员可以利用Qwen3-Next对海量的非结构化文本数据进行高效分析,快速提取关键信息、识别趋势、进行情感分析或生成摘要。这对于市场研究、商业智能和风险管理等领域具有重要的辅助作用。
- 教育辅助:在教育领域,Qwen3-Next能够提供个性化的学习内容、智能辅导和答疑解惑。它可以根据学生的学习进度和偏好,生成定制化的教学材料,辅助学生更好地理解知识点,提升学习效果。
- 法律咨询与研究:法律专业人士可以利用Qwen3-Next快速分析复杂的法律文件、判例和法规,提供初步的法律咨询意见,或辅助进行法律研究。其深度理解和推理能力,有助于在海量法律文本中发现关键信息和关联。
便捷获取与未来展望:模型部署与AI生态发展
为了让更多开发者和企业能够便捷地体验和应用Qwen3-Next的强大能力,阿里通义已经提供了多样化的获取途径。用户可以通过阿里云百炼平台进行API调用,将Qwen3-Next集成到自己的应用和服务中。此外,QwenChat网页版也提供了直观的在线交互体验,使得非技术用户也能轻松感受Qwen3-Next的魅力。对于开源社区的开发者而言,Qwen3-Next的HuggingFace模型库地址也已公开,为模型的二次开发和研究提供了便利。
Qwen3-Next的发布,不仅是阿里通义在AI大模型领域的一次重大突破,更是对未来AI发展方向的一次积极探索。其混合架构和极致效率的特性,预示着未来的大模型将更加注重在性能、效率和资源消耗之间的平衡。这种趋势将推动AI技术向更广泛的领域渗透,加速通用人工智能的实现。随着技术的不断迭代和优化,我们有理由相信,Qwen3-Next及其后续版本,将在全球AI生态中扮演越来越重要的角色,持续赋能各行各业的数字化转型和智能化升级。

