
腾讯混元图像2.1:高分辨率与文本生成的新里程碑
腾讯混元团队近日发布了其最新生图模型“混元图像2.1(HunyuanImage2.1)”,标志着国产AI图像生成技术迈向了新的高度。该模型最显著的特点在于其原生支持2K分辨率图像生成,极大提升了图像的细节表现力与视觉冲击力。在复杂语义理解方面,HunyuanImage2.1展现出卓越的能力,能够准确捕捉用户指令的细微之处,并将其转化为高质量的图像内容,同时支持中英文输入,拓宽了应用场景。更值得关注的是,该模型还具备高质量文本生成能力,这意味着它不仅能创作视觉艺术,还能在图像中精确嵌入文字信息,这对于广告设计、海报制作等领域具有颠覆性意义。模型已在Hugging Face和GitHub上开源,此举无疑将加速AI图像生成技术在学术界和产业界的普及与创新。通过开放模型,腾讯混元致力于构建一个更开放、更具活力的AI生态系统,赋能全球视觉创作者和开发者。

HunyuanImage2.1的开源,不仅为开发者提供了强大的创作工具,也为未来多模态图像生成模型的研究与开发奠定了坚实基础。其对高清图像和文本生成能力的整合,预示着AI在视觉内容创作领域将发挥越来越核心的作用,从概念草图到精细化设计,AI都能提供高效且创新的解决方案。
爱诗科技获6000万美元B轮融资:视频生成领域的新巨头崛起
在AI视频生成领域,爱诗科技近期完成的6000万美元B轮融资,无疑是行业内的一项里程碑事件。本轮融资由阿里巴巴领投,刷新了国内视频生成领域的最高融资记录,充分展现了市场对爱诗科技技术实力及其未来增长潜力的强烈信心。爱诗科技凭借其自研的视频生成大模型PixVerse V5,在图生视频领域取得了卓越成就,该模型不仅在技术评测中位列第一,用户规模也已突破1亿大关,成为内容创作者和营销人员的强大工具。
公司此番融资后,计划推出开放平台API,旨在将领先的视频生成技术普及化,让更多企业和个人能够便捷地接入并利用AI技术进行视频创作。这一战略举措将极大地推动视频生成技术的规模化应用,降低视频制作门槛,从而激发更广泛的创意表达与商业价值。通过API接口,开发者可以轻松地将PixVerse V5的能力集成到现有应用中,实现从文字到视频、图片到视频的高效转化,进一步革新数字内容创作的生态。
Freepik携手豆包Seedream 4.0:高分辨率图像创作触手可及
全球知名的设计资源平台Freepik近日正式上线了全新的豆包Seedream 4.0图像模型,此举迅速吸引了全球设计师和创作者的广泛关注。该模型在技术层面上进行了显著迭代与提升,核心亮点在于其能够支持生成2K乃至4K超高分辨率图像。这意味着,无论是用于印刷品、数字广告还是高清屏幕展示,设计师都能获得极致清晰、细节丰富的视觉素材,极大地拓宽了创作边界。
除了分辨率的飞跃,Seedream 4.0还提供了多种纵横比选择,能够灵活适配不同设计项目对构图的需求。Freepik的Premium+和Pro会员将享受到无限图像生成的特权,这无疑将大幅提升用户的工作效率和创作自由度。与此同时,火山引擎也同步推出了Seedream 4.0的API,为企业级用户和开发者提供了大规模图像处理和定制化集成的便利。这一系列的整合与开放,正逐步将先进的AI图像生成技术转化为触手可及的创作工具,赋能创意产业实现效率与质量的双重飞跃。
阿里巴巴通义千问3新模型:参数压缩与推理效率的突破
阿里巴巴通义千问团队近期推出的Qwen3-Next-80B-A3B-Instruct模型,在大型语言模型领域实现了关键性的技术突破。该模型创新性地采用了MoE(Mixture of Experts)专家混合架构,成功地在800亿参数的规模下,将实际激活参数量控制在30亿左右。这一设计理念的引入,实现了高效率与高性能的完美结合,显著降低了运行模型所需的计算成本和资源消耗。
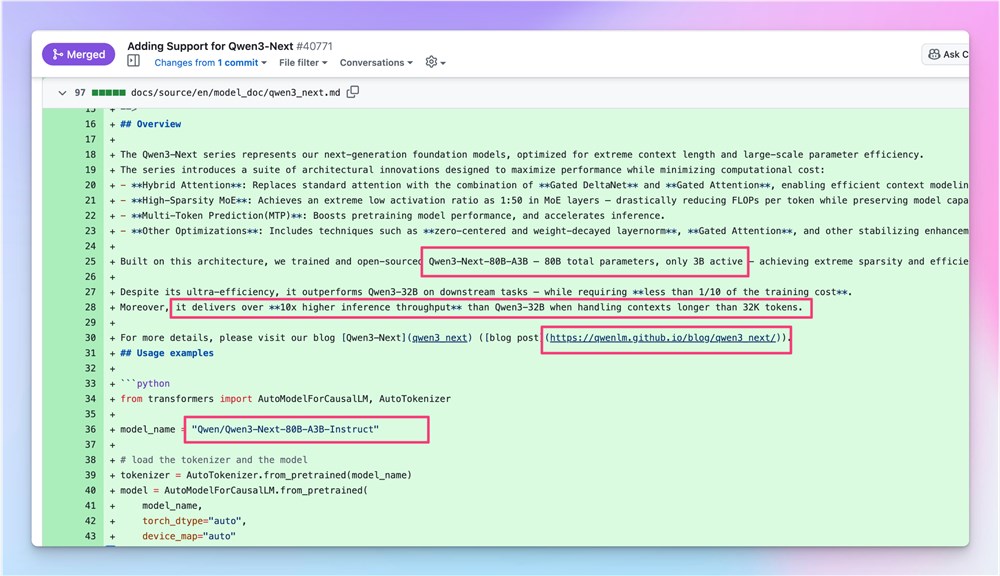
MoE架构的优势在于,它能够根据输入数据的特点,动态地选择性激活模型中的部分“专家”模块进行推理,而非加载全部参数。这使得Qwen3-Next-80B-A3B-Instruct模型的推理速度相较于传统的Qwen3-32B模型提升了10倍以上,尤其在处理长上下文内容时展现出更高的效率。更重要的是,通过参数压缩和优化,模型的训练成本也大幅下降,这对于推动更多研究机构和企业参与到大模型的开发与应用中具有深远意义。该模型的发布,不仅展示了阿里巴巴在大模型优化方面的领先实力,也为AI技术的大规模普及和应用提供了更经济、更高效的解决方案。
微软启动AI供应商多元化策略:Office 365集成Anthropic技术
微软近期在Office 365中引入Anthropic的AI技术,标志着其在人工智能战略上的一个重要转变。这一举措反映了微软对AI供应链多样化的高度重视,旨在减少对单一AI供应商的依赖,并促进内部创新与外部合作的平衡。此前,微软与OpenAI的深度合作广受关注,而此次引入Anthropic的技术,表明微软正寻求通过多方合作,来提升其AI服务的广度与深度,确保技术生态的稳健性与前沿性。
此项合作将Anthropic的AI能力融入到Office 365的核心应用中,预计将进一步增强文档撰写、数据分析、内容生成等多个方面的智能化水平,为用户提供更为强大和多元的辅助功能。微软的这一战略调整,不仅是基于对不同AI技术栈性能的综合考量,也体现了其致力于构建更具韧性的AI技术供应体系。长远来看,这种多元化策略将有助于避免潜在的技术瓶颈或市场垄断风险,鼓励更多AI创新企业参与竞争,从而推动整个AI行业的健康发展。
Fellou CE:首款AI Agent浏览器引领“无缝衔接”的智能体验
Fellou CE的发布,标志着首款AI Agent浏览器正式进入公众视野,它致力于为用户打造前所未有的“无缝衔接”智能体验。Fellou CE不仅仅是一个传统的网页浏览器,更是一个能够理解用户意图、自主执行复杂任务的智能代理。通过自然语言对话,这款浏览器能够帮助用户简化工作流程,例如自动收集信息、整理数据、完成在线表单填写等,从而大幅提升工作效率并激发创造力。
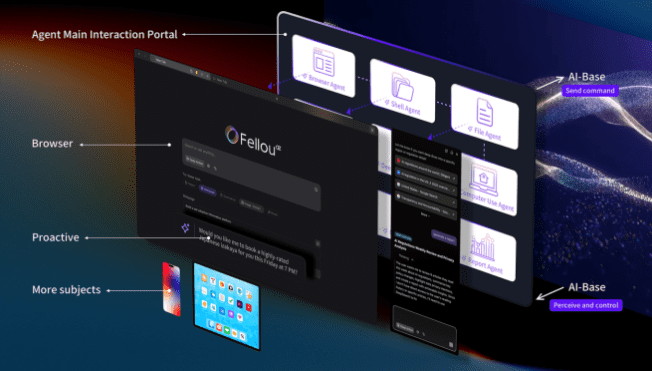
其核心设计理念在于将AI能力深度集成到浏览器的每一个环节,使得用户能够以最直观、最省力的方式与数字世界互动。Fellou CE正积极构建一个开放的智能生态系统,旨在通过持续迭代和社区协作来不断改进用户体验。同时,隐私与数据安全是Fellou团队高度重视的基石,确保用户在使用智能功能的同时,其个人信息得到充分保护。这款AI Agent浏览器有望重新定义人机交互模式,从被动浏览转变为主动协作,开启智能办公和个人生产力的新篇章。
清华团队开源GUAVA:0.1秒实现照片秒变3D数字人
清华大学团队近日开源了GUAVA项目,这项突破性技术能够在短短0.1秒内,将一张普通照片迅速转化为高质量的3D数字人模型,其惊人的速度和逼真的效果引起了广泛关注。GUAVA的核心在于其创新的EHM(Expressive Human Motion)模型与先进的3D高斯泼溅(3D Gaussian Splatting)技术相结合。EHM模型能够精准捕捉并还原照片中人物的表情、姿态等动态细节,而3D高斯泼溅技术则确保了实时、高质量的渲染效果,使得生成的3D数字人不仅立体感强,而且具有高度的真实感和灵活性。

这项技术的应用前景极其广阔,特别是在数字媒体、虚拟现实(VR)、增强现实(AR)、直播带货、电商展示以及教育培训等领域。例如,自媒体创作者可以快速生成个性化的虚拟形象进行内容创作;电商平台能够为商品创建更具交互性的虚拟模特;教育机构可利用3D数字人提供沉浸式的教学体验。GUAVA的开源,不仅展现了清华团队在计算机图形学和AI领域的深厚实力,也为全球开发者提供了一个强大的工具,加速了3D数字人技术的普及与创新应用,有望彻底改变数字内容制作的效率和用户体验。
Claude助手升级:一键生成Excel、PPT、PDF,办公效率革命
Anthropic公司的AI助手Claude近期迎来了一项重磅升级,新增了直接生成和编辑多种办公文件的功能,包括Excel、Word、PPT和PDF。这项功能使得Claude从一个单纯的文本生成工具,跃升为一款强大的数字合作者,能够直接输出符合专业要求的办公文档“现成品”,极大提升了用户的工作效率。这一创新意味着用户可以通过简单的自然语言指令,让Claude快速构建复杂的数据表格、制作演示文稿或生成结构化的报告,省去了大量手动操作的繁琐过程。

目前,该功能已向部分Max、Team和Enterprise版本用户开放预览,Pro用户也将陆续获得权限。Claude作为一款智能数字助手,其能力不仅仅停留在文件生成,它还能执行代码、处理数据,并根据用户需求对生成的文件进行修改和优化。这项功能的推出,标志着AI在深度集成办公场景方面迈出了重要一步,有望彻底改变传统办公模式,让知识工作者能够将更多精力投入到高价值的创意和决策工作中,而非重复性的文档处理。它预示着一个由AI驱动的、更加高效和智能的办公新时代正在加速到来。

