

在数字内容创作领域,虚拟角色的面部动画一直是一项复杂且耗时的工作。传统方法需要专业的动画师逐帧调整,或者依赖昂贵的面部捕捉设备。然而,随着人工智能技术的飞速发展,这一局面正在被彻底改变。英伟达近期开源的Audio2Face模型,正是这一变革的标志性成果,它通过简单的音频输入即可生成高度逼真的面部动画,为游戏、影视和虚拟现实等领域带来了前所未有的创作可能性。
Audio2Face:技术原理与核心优势
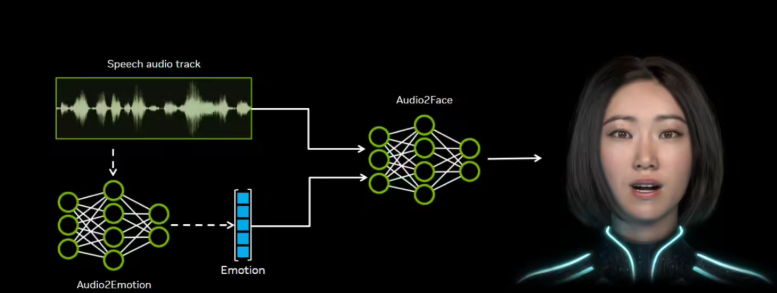
Audio2Face是英伟达开发的一款生成式AI模型,其核心创新在于能够将音频中的声学特征(如音素、语调、节奏等)映射到面部表情和动作上,实现音画同步的自然动画效果。这一技术的突破性在于它不仅能够精确匹配口型,还能捕捉到说话者的情感状态,生成微妙的表情变化,使虚拟角色呈现出前所未有的真实感和表现力。
与传统的面部动画技术相比,Audio2Face具有显著优势:首先,它大幅降低了技术门槛,使不具备专业动画技能的开发者也能创建高质量的虚拟角色;其次,它显著提高了制作效率,将原本需要数小时甚至数天的工作缩短至几分钟;最后,它提供了极高的灵活性和定制性,开发者可以根据特定需求对模型进行微调,适应不同风格和场景的应用。
技术架构:从音频到表情的智能映射
Audio2Face的技术架构建立在深度学习模型的基础上,主要包括音频处理、特征提取和面部动画生成三大核心模块。音频处理模块负责对输入的音频信号进行预处理,提取出关键的声学特征;特征提取模块则利用神经网络将这些特征转换为面部表情的控制参数;最后,面部动画生成模块根据这些参数驱动3D面部模型,生成相应的动画效果。
英伟达在开源Audio2Face时,不仅提供了核心算法,还发布了完整的训练框架,这使得开发者能够使用自己的数据对模型进行定制化训练。这一开放策略极大地促进了技术的普及和创新,为不同行业的应用提供了广阔空间。
双模式运行:离线渲染与实时流式处理
Audio2Face支持两种运行模式,以满足不同应用场景的需求。第一种是针对预录制音频的离线渲染模式,这种模式可以生成最高质量的动画效果,适用于影视制作等对质量要求极高的场景。开发者可以导入已完成的音频文件,系统将生成与音频完美同步的面部动画,然后将其整合到3D场景中。
第二种模式则是支持动态AI角色的实时流式处理,这种模式对计算效率要求更高,但能够实现即时响应,适用于游戏和虚拟现实等交互性强的场景。在这种模式下,虚拟角色可以实时根据用户的语音输入做出表情反应,创造更加沉浸式的体验。
开发者工具链:从SDK到行业插件
为了降低技术门槛,英伟为Audio2Face提供了全面的开发者工具链。首先,Audio2Face SDK允许开发者轻松将模型集成到自己的应用程序中,提供了简单易用的API接口。其次,英伟达还开发了针对行业标准软件的插件,包括适用于Autodesk Maya的本地执行插件,以及针对Unreal Engine 5.5及以上版本的插件。
这些工具极大地简化了开发流程,使动画师和开发者能够在其熟悉的创作环境中直接使用Audio2Face。无论是Maya中的传统3D动画制作,还是Unreal Engine中的实时渲染,都能无缝集成这一技术,实现从音频到面部动画的一站式解决方案。
行业应用案例:从游戏到影视的实践
Audio2Face技术已经在多个领域展现出巨大潜力。在游戏行业,多家领先开发商已成功应用这一技术,显著提升了开发效率和角色表现。游戏开发公司Survios在其作品《异形:侠盗入侵进化版》中集成了Audio2Face,大幅简化了口型同步与面部捕捉的流程,使团队能够将更多精力投入到游戏玩法和故事创作中。
Farm51工作室在其作品《切尔诺贝利人2:禁区》中的应用同样令人印象深刻。通过音频直接生成细腻的面部动画,该工作室节省了大量制作时间,同时提升了角色的真实感和沉浸体验。创新总监Wojciech Pazdur将这一技术称为"革命性突破",认为它正在重新定义游戏角色创作的标准。
在影视制作领域,Audio2Face同样展现出巨大潜力。对于预算有限的独立电影制作人来说,这项技术提供了一种经济高效的方式来创建高质量的角色动画。而对于大型制片厂,它可以作为传统面部捕捉技术的补充,提高制作效率并降低成本。
技术局限与未来发展方向
尽管Audio2Face取得了显著成就,但技术仍有改进空间。目前,模型在处理极端情感或特殊口音时可能表现不够理想,且对音频质量有一定要求。此外,对于某些高度风格化的艺术风格,可能需要额外的训练和调整才能达到最佳效果。
未来,Audio2Face的发展可能集中在几个方向:首先是提高模型的泛化能力,使其能够更好地处理各种音频输入和艺术风格;其次是增强实时性能,降低对硬件的要求,使其能够在更广泛的设备上运行;最后是扩展功能范围,例如添加更多情感表达或支持多语言处理。
对数字内容创作行业的深远影响
Audio2Face的开源对数字内容创作行业产生了深远影响。首先,它降低了高质量虚拟角色创作的门槛,使更多创作者能够参与这一领域。其次,它加速了工作流程,缩短了从创意到成品的时间周期。最后,它提高了内容质量标准,推动整个行业向更高水平的视觉表现力发展。
对于独立开发者和小型工作室而言,这项技术尤其具有革命性意义。它提供了一种经济高效的方式来创建专业级的虚拟角色,使它们能够与大型开发商竞争。而对于教育机构,Audio2Face则为数字艺术和动画教学提供了强大的工具,帮助学生掌握前沿技术。
实战指南:如何开始使用Audio2Face
对于希望尝试Audio2Face的开发者,英伟达提供了详细的文档和教程。首先,访问英伟达的Audio2Face页面(https://build.nvidia.com/nvidia/audio2face-3d)下载必要的组件和SDK。根据项目需求选择合适的运行模式,离线渲染或实时流式处理。
对于Unreal Engine用户,安装官方插件后,可以直接在编辑器中导入音频文件并生成面部动画。Maya用户则可以通过本地执行插件将Audio2Face集成到现有工作流中。对于需要高度定制化的场景,可以利用开源训练框架使用自己的数据对模型进行微调。
结语:AI赋能下的创意新纪元
英伟达开源Audio2Face模型标志着AI技术在内容创作领域的又一重要里程碑。它不仅展示了人工智能如何简化复杂的工作流程,更揭示了人机协作的无限可能。随着这项技术的普及和进步,我们可以期待看到更加生动、真实的虚拟角色出现在各种数字内容中,为用户带来前所未有的沉浸体验。
对于内容创作者而言,Audio2Face不仅是一种工具,更是一种赋能,它释放了创意的潜力,使艺术家能够专注于故事和情感的表达,而非技术细节的繁琐处理。在这个AI赋能的新时代,数字内容创作正迎来一个充满无限可能的未来。









