
在人工智能技术日新月异的今天,开源生态与商业化应用正以前所未有的速度推动着行业变革。近期,多家科技巨头与创新企业相继发布突破性AI产品,从语音处理到视频生成,从音乐创作到3D建模,AI技术正在重塑内容创作与数字交互的边界。本文将深入剖析这些创新技术,探讨它们对行业生态的影响与未来发展趋势。
小米开源首个原生端到端语音大模型
小米公司近日宣布开源其首个原生端到端语音大模型Xiaomi-MiMo-Audio,这一举措标志着语音技术领域的重要突破。该模型基于创新的预训练架构和上亿小时的训练数据,在少样本泛化能力方面表现出色,并在多个评测基准中超越了谷歌和OpenAI的闭源模型。
技术创新与优势
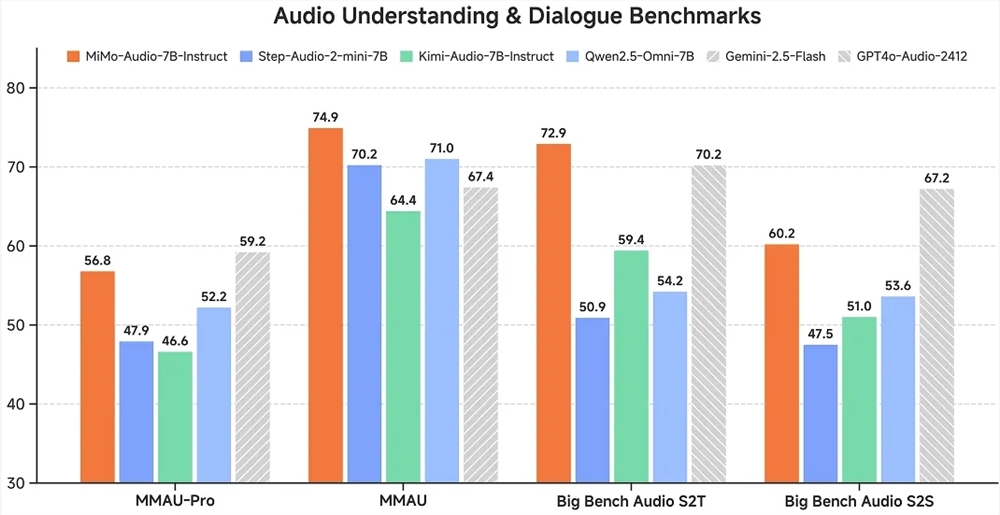
Xiaomi-MiMo-Audio最引人注目的成就是首次实现了语音领域基于In-Context Learning的少样本泛化能力。这意味着模型能够通过少量示例快速适应新的语音识别或合成任务,大幅降低了训练成本和应用门槛。在音频理解基准MMAU和Big Bench Audio S2T任务中,该模型的表现超越了谷歌和OpenAI的闭源模型,证明了国产AI技术在国际竞争中的实力。
小米开源了完整的语音预训练方案,包括Tokenizer、模型结构、训练方法和评测体系,为语音AI研究者和开发者提供了宝贵的参考。这种开放态度不仅促进了技术交流,也有助于构建更加健康的AI生态系统。
行业影响与应用前景
Xiaomi-MiMo-Audio的开源将对语音AI领域产生深远影响。一方面,它降低了企业开发语音应用的门槛,特别是对于资源有限的中小企业和初创公司;另一方面,它将推动语音技术在更多场景的应用,从智能助手到实时翻译,从内容创作到教育辅助。
值得注意的是,该模型在少样本学习方面的突破,为语音AI的个性化应用提供了可能。未来,我们或许能看到能够快速适应用户特定口音、语调和表达习惯的语音系统,这将极大提升人机交互的自然度和体验感。
通义万相动作生成模型Wan2.2-Animate:视频创作的新可能
通义万相团队推出的全新动作生成模型Wan2.2-Animate正式开源,为视频创作领域带来了革命性的工具。该模型在人物一致性、生成质量等方面有显著提升,支持动作模仿和角色扮演两种模式,广泛应用于短视频创作、动漫制作等领域。
核心功能与技术亮点
Wan2.2-Animate的核心功能在于能够将参考视频的动作迁移到静态图片角色中。具体来说,用户只需输入角色图片和参考视频,模型就能将视频中的动作精准地应用到图片角色上,创造出动态的视频内容。在角色扮演模式下,模型还可以替换视频中的原有角色为用户提供的图片角色,实现角色与动作的自由组合。
模型特别设计了独立的光照融合LoRA(Low-Rank Adaptation),确保生成的视频在光照效果上能够完美融合,避免了传统动作迁移技术中常见的光影不协调问题。这一细节处理体现了开发团队对生成质量的极致追求。

应用场景与行业价值
Wan2.2-Animate的开放为内容创作者提供了强大的工具,特别是在短视频制作和动漫创作领域。传统上,这些工作需要专业的动画师和大量的时间投入,而现在,通过该模型,创作者可以快速实现角色动作的设计和调整,大大提高了创作效率。
对于教育、娱乐和营销等行业,该模型同样具有巨大潜力。例如,在教育领域,可以制作生动的教学动画;在娱乐领域,可以实现粉丝与偶像的"同框"互动;在营销领域,可以快速生成产品演示视频。这些应用不仅降低了内容制作成本,还能创造出更加丰富多样的视觉体验。
Suno v5:AI音乐创作的里程碑
Suno的v5音乐模型即将发布,被业界视为AI音乐创作的里程碑。这一消息引发了全球音乐创作和技术爱好者的广泛关注,预示着AI音乐创作将迎来"变革性"升级。
技术突破与功能升级
虽然官方尚未公布v5的全部细节,但根据已有信息,v5将引入更先进的语义控制和多模态输入功能。这意味着用户可能通过更自然的方式表达音乐创作意图,而不仅仅是通过简单的文本描述。v4.5上线后,用户生成作品播放量已突破数亿次,这一数据充分证明了Suno系列模型在音乐生成领域的受欢迎程度。
AI音乐创作正逐渐模糊人类作曲与机器生成的界限。v5的推出可能会进一步推动这一趋势,使AI不仅能生成符合技术规范的音乐,还能捕捉和表达人类情感,创作出更具艺术性和感染力的作品。
行业影响与争议
AI音乐创作的发展为音乐产业带来了新的机遇和挑战。一方面,它降低了音乐创作的门槛,使更多非专业音乐人能够实现自己的创意;另一方面,它也引发了关于原创性、版权和艺术价值的讨论。
随着AI生成音乐质量的提升,我们可能会看到更多AI参与创作的音乐作品进入主流市场。这将改变音乐产业的创作模式,也可能重塑音乐消费习惯。如何平衡技术创新与艺术价值,将是行业需要共同面对的问题。
生数科技融资与视频生成商业化
生数科技在多模态AI领域取得显著进展,成功获得数亿元融资,并通过Vidu视频大模型实现了商业化的成功。这一事件标志着视频生成技术从实验室走向市场的关键一步。
商业化成果与市场认可
生数科技的Vidu视频大模型实现了2000万美元年收入,这一数据证明了视频生成技术的商业潜力。与许多仍处于研发阶段的AI技术不同,Vidu已经找到了实际应用场景和商业模式,这为其他AI创业公司提供了宝贵参考。
视频生成技术的商业化应用广泛,包括广告制作、影视后期、教育培训、游戏开发等多个领域。随着技术的成熟,应用场景还将不断扩展,为数字内容生产方式带来革命性变化。
行业挑战与未来展望
尽管前景广阔,视频生成技术仍面临诸多挑战。版权问题尤为突出,AI生成内容的版权归属尚无明确法律界定;虚假信息的风险也不容忽视,高质量的AI生成视频可能被用于制造虚假信息或深度伪造内容。
未来,视频生成技术需要在技术创新与伦理规范之间找到平衡。一方面,要不断提高生成质量、降低使用门槛;另一方面,要建立健全的内容审核和版权保护机制,确保技术健康发展。
OpenAI修复ChatGPT漏洞:AI安全的重要性
网络安全公司Radware发现了ChatGPT的"深度研究"功能存在严重漏洞,可能被黑客利用来窃取用户的Gmail邮件数据。该漏洞允许黑客通过特制邮件诱导ChatGPT在处理用户Gmail查询时,将敏感信息发送到恶意网站。
漏洞详情与影响范围
这一漏洞的严重性在于它绕过了常规的安全防护措施,使攻击者能够获取用户的敏感信息。考虑到ChatGPT的广泛使用,这一漏洞可能影响大量用户的数据安全。幸运的是,OpenAI迅速识别并修复了这一漏洞,并确认其对用户信息安全的重视。
这一事件再次提醒我们,随着AI系统越来越深入地融入日常生活,其安全性变得尤为重要。AI系统不仅需要功能强大,还需要具备抵御各种攻击的能力,保护用户数据安全。
安全挑战与应对策略
AI系统的安全防护面临独特挑战。一方面,AI模型的复杂性和黑盒特性使得安全漏洞难以发现和修复;另一方面,攻击手段也在不断进化,需要持续更新防护策略。
对于普通用户而言,保持警惕是防范AI安全风险的第一道防线。避免将敏感信息输入不可信的AI系统,定期检查账户安全设置,及时更新软件版本,都是有效的防护措施。对于AI开发者而言,将安全纳入设计流程,进行定期安全审计,是构建可信AI系统的必要条件。
谷歌Chrome整合Gemini:智能搜索新体验
谷歌将Gemini集成到Chrome浏览器中,以增强用户体验并应对日益激烈的市场竞争。这一整合标志着AI技术在浏览器领域的深度应用,将为用户带来全新的智能搜索体验。
功能亮点与用户体验
Gemini在Chrome中的整合带来了多项实用功能。它支持跨选项卡工作,能够理解用户在不同标签页中的操作,并提供相关建议;任务安排功能可以帮助用户规划和管理日常活动;与谷歌多个应用的深度整合,使不同服务之间的切换更加流畅。
对于企业用户,Gemini还提供了数据保护和代理功能,满足企业在数据安全和隐私保护方面的需求。这些功能的整合,使Chrome从单纯的网页浏览工具转变为智能工作助手。
市场竞争与战略意义
在AI助手领域,谷歌面临着来自微软必应、OpenAI等竞争对手的强大压力。将Gemini整合到Chrome中,是谷歌巩固其搜索和浏览器市场地位的重要举措。通过将AI能力直接集成到用户日常使用的工具中,谷歌希望能够提升用户粘性,并为其AI生态系统带来更多流量和商业机会。
这一整合也反映了科技巨头在AI领域的战略布局:将AI技术深度融入现有产品,提升用户体验,同时构建更强大的技术壁垒。未来,我们可能会看到更多AI功能被整合到常用软件和平台中,改变我们与数字世界的交互方式。
Luma AI发布Ray3:视频生成技术的革新
Luma AI推出的Ray3视频生成模型凭借其HDR能力和强大的"推理"功能,为视频创作带来了革命性的变化。该模型支持高精度的视觉控制和专业工作流程整合,满足了专业创作者对高质量视频生成工具的需求。
技术突破与创新点
Ray3最显著的特点是其对高色深视频的支持。它能够生成10位、12位乃至16位色深的视频,并可导出为EXR文件格式,这一特性使其能够满足专业影视制作和后期处理的需求。相比之下,大多数消费级视频生成工具仅支持8位色深,无法满足专业工作流程的要求。
Ray3的"推理"能力是其另一大创新点。传统视频生成模型通常需要用户精确指定生成内容和风格,而Ray3能够理解复杂指令并自我评估输出质量,实现视频的迭代优化。这种能力大大降低了用户的使用门槛,使非专业人士也能创作出高质量的视频内容。
应用场景与行业影响
Ray3的发布对专业视频制作行业具有重要意义。一方面,它为影视制作、广告创意等领域提供了新的创作工具,能够大幅提高制作效率;另一方面,它也改变了传统的工作流程,使创作者能够更快速地实现创意构想。
对于独立创作者和小型工作室,Ray3这样的专业工具降低了高质量视频制作的门槛,使他们能够与大型制作公司竞争。这种民主化趋势正在改变视频内容的生产格局,为更多创意人才提供展示才华的平台。
Mistral AI推出Magistral Small 1.2:开源推理模型的新高度
法国公司Mistral AI推出了其最新开源推理模型Magistral Small 1.2,该模型拥有24B参数,并以Apache2.0开源许可方式发布。这一发布标志着开源大模型在推理能力方面的重要进步。
模型特点与技术优势
Magistral Small 1.2在多个方面进行了创新。首先,新版本支持高达128k的上下文处理,这一能力使其能够处理长文本对话和复杂推理任务,远超大多数开源模型。其次,它引入了[THINK]特殊token,增强了模型的表现力和灵活性,使模型能够更好地进行推理和自我修正。
此外,Magistral Small 1.2还增加了视觉编码器,使其在图像和文本综合任务中更具优势。这一设计使模型能够处理多模态输入,为开发者提供了更多应用可能性。模型还兼容多种框架,降低了集成难度,便于在不同环境中部署和使用。
开源生态与行业影响
Apache2.0的开源许可方式意味着Magistral Small 1.2可以被商业使用,这大大扩展了其应用范围。与许多仅限研究用途的开源模型相比,这一许可政策吸引了更多企业和开发者的关注和参与。
Magistral Small 1.2的发布进一步丰富了开源大模型生态系统,为企业和开发者提供了更多选择。在闭源模型主导的市场环境下,高质量的开源模型不仅提供了技术参考,也为构建更加开放和包容的AI生态做出了贡献。
Notion AI智能体:自动化文档处理的新时代
Notion推出了首个AI智能体,能够利用用户所有Notion页面和数据库作为上下文,自动生成会议笔记、分析报告、竞品评估等。这一功能标志着文档处理和知识管理进入自动化时代。
功能特点与工作原理
Notion AI智能体的核心优势在于其上下文理解能力。它能够访问用户的整个Notion工作空间,理解其中的内容关联和知识结构,从而生成更加准确和相关的文档。例如,在生成会议笔记时,智能体可以参考与会者的历史互动和项目背景,确保笔记的完整性和连贯性。
智能体支持从外部平台(如Slack、邮件和Google Drive)触发操作,实现了跨平台的工作流整合。用户还可以为智能体设置档案页面,指导其如何引用来源、控制输出风格等,实现个性化的文档生成体验。
应用场景与工作效率提升
Notion AI智能体的应用场景广泛,包括但不限于:会议记录自动整理、项目进展报告生成、市场竞品分析、研究资料汇总等。这些功能可以帮助企业和团队大幅减少文档处理时间,将更多精力投入到创造性工作中。
以竞品分析为例,传统上需要研究人员收集大量信息、整理分析并撰写报告,整个过程可能需要数天时间。而使用AI智能体,可以在20分钟内处理数百页文档,生成结构化的分析报告,大大提高了工作效率。
腾讯混元3D Studio:3D创作效率的革命性提升
腾讯混元3D Studio的发布标志着3D创作效率的革命性提升,为设计师、游戏开发者和建模师提供了强大的AI工作台,显著缩短了3D资产生产周期。
核心技术与功能亮点
混元3D Studio采用了多项创新技术,原生3D分割算法实现了模型部件的自动拆分,支持独立编辑角色配饰和服装。这一功能大大简化了3D模型的修改和定制过程,使设计师能够更灵活地调整设计细节。
AI语义UV展开技术在1-2分钟内生成符合美术标准的UV图,传统上这一工作可能需要数小时甚至数天完成。智能材质编辑支持通过文本或图片输入生成高质量PBR质感纹理,实现了精准的材质控制,使3D模型的外观效果更加逼真。

行业影响与创作民主化
混元3D Studio的发布对3D创作行业产生了深远影响。一方面,它大幅提高了专业3D设计师的工作效率,使他们能够处理更复杂的项目;另一方面,它降低了3D创作的技术门槛,使非专业人士也能创建高质量的3D内容。
这种创作工具的普及正在推动3D内容的民主化。未来,我们可能会看到更多由个人创作者和小团队制作的高质量3D内容,应用于游戏、影视、教育、营销等多个领域。这将丰富数字内容生态,为用户带来更加多样化的视觉体验。
AI技术发展趋势与行业展望
综合近期AI领域的多项突破,我们可以看到几个明显的技术发展趋势和应用方向。这些趋势不仅反映了技术创新的方向,也预示着未来AI产业可能的发展路径。
多模态融合成为主流
从语音、图像到视频、3D模型,AI技术正朝着多模态融合的方向发展。小米的语音大模型、通义万相的动作生成模型、Luma AI的视频生成模型等,都体现了这一趋势。多模态AI系统能够理解和生成不同类型的内容,提供更加丰富的交互体验。
未来,我们可能会看到更多能够同时处理文本、图像、音频、视频等多种输入的AI系统,它们将能够更好地理解人类表达的多维性,提供更加自然和智能的服务。
开源生态与商业化并行
AI领域呈现出开源与商业化并行发展的态势。一方面,小米、通义万相、Mistral AI等选择开源其模型,促进了技术交流和创新;另一方面,生数科技、Notion等通过商业化应用实现了技术价值。
这种并行发展模式有利于构建健康的AI生态系统。开源模型为研究和创新提供了基础,而商业化应用则推动了技术的普及和优化。未来,我们可能会看到更多"开源+商业化"的成功案例,加速AI技术的落地应用。
效率提升与创作民主化
AI技术的另一个显著趋势是效率提升和创作民主化。从文档处理到3D建模,从音乐创作到视频生成,AI工具正在降低专业创作的门槛,使更多人能够参与内容创作。
这一趋势将重塑内容产业格局。传统上,高质量内容创作需要专业知识和大量时间投入,而现在,AI工具能够大幅简化创作过程,使个人和小团队能够创作出专业级内容。这将丰富内容生态,为用户带来更多元化的选择。
安全与伦理挑战日益凸显
随着AI技术的广泛应用,安全与伦理问题也日益凸显。从ChatGPT的安全漏洞到AI生成内容的版权争议,从深度伪造的风险到数据隐私保护,这些问题需要行业共同面对和解决。
未来,AI技术的发展需要在创新与规范之间找到平衡。一方面,要继续推动技术创新和应用拓展;另一方面,要建立健全的安全防护和伦理规范,确保AI技术造福人类社会。这需要技术开发者、政策制定者、伦理学家和公众的共同努力。
结语:AI创新引领数字未来
近期AI领域的多项突破展示了技术的快速迭代和广泛应用潜力。从小米的语音大模型到通义万相的动作生成,从Suno的音乐创作到腾讯的3D建模,AI技术正在重塑内容创作和数字交互的方式。
这些创新不仅提高了工作效率,降低了创作门槛,也为各行业带来了新的可能性。然而,随着技术的深入应用,安全与伦理挑战也日益凸显,需要行业共同应对。
展望未来,AI技术将继续向多模态融合、开源与商业化并行、效率提升与创作民主化等方向发展。在这个过程中,技术创新与人文关怀需要并重,确保AI技术真正服务于人类社会的进步与发展。









