
在伊朗,当出租车司机挥手拒绝你的付款,说"这次请我客"时,接受他的提议将是一场文化灾难。他们实际上期望你坚持付款——可能需要三次坚持——他们才会收下钱。这种拒绝与反拒绝的舞蹈,被称为"塔罗夫",在波斯文化中 governing 着无数日常互动。而AI模型对此却束手无策。
本月早些时候发布的一项新研究《我们礼貌地坚持:你的LLM必须学习波斯塔罗夫艺术》显示,来自OpenAI、Anthropic和Meta的主流AI语言模型无法吸收这些波斯社交礼仪,在塔罗夫情境中的正确率仅为34%至42%。相比之下,波斯语母语者的正确率达到82%。这一性能差距存在于GPT-4o、Claude 3.5 Haiku、Llama 3、DeepSeek V3和Llama 3的波斯调整版Dorna等大型语言模型中。
由布鲁克大学的Nikta Gohari Sadr领导的研究团队与埃默里大学及其他机构的研究人员共同引入了"TAAROFBENCH",这是首个衡量AI系统重现这种复杂文化实践的基准测试。研究人员的研究结果表明,最近的AI模型默认采用西方直接沟通方式,完全忽视了全球数百万波斯语使用者日常互动中的文化线索。
"在高风险环境中的文化失误可能破坏谈判、损害关系并强化刻板印象,"研究人员写道。对于越来越多用于全球背景的AI系统而言,这种文化盲点可能代表着一个西方人很少意识到的局限性。
塔罗夫:波斯礼仪的核心
"塔罗夫,波斯礼仪的核心元素,是一种仪式化的礼貌系统,其中所说的内容往往与所表达的意思不同,"研究人员写道。"它采取仪式化交换的形式:尽管最初被拒绝但仍反复提供、在给予者坚持时拒绝礼物、在对方肯定时回避赞美。这种'礼貌的语言角力'(Rafiee, 1991)涉及提供与拒绝、坚持与抵抗的微妙舞蹈,它塑造了伊朗文化中的日常互动,为慷慨、感激和请求的表达创造了隐含规则。"
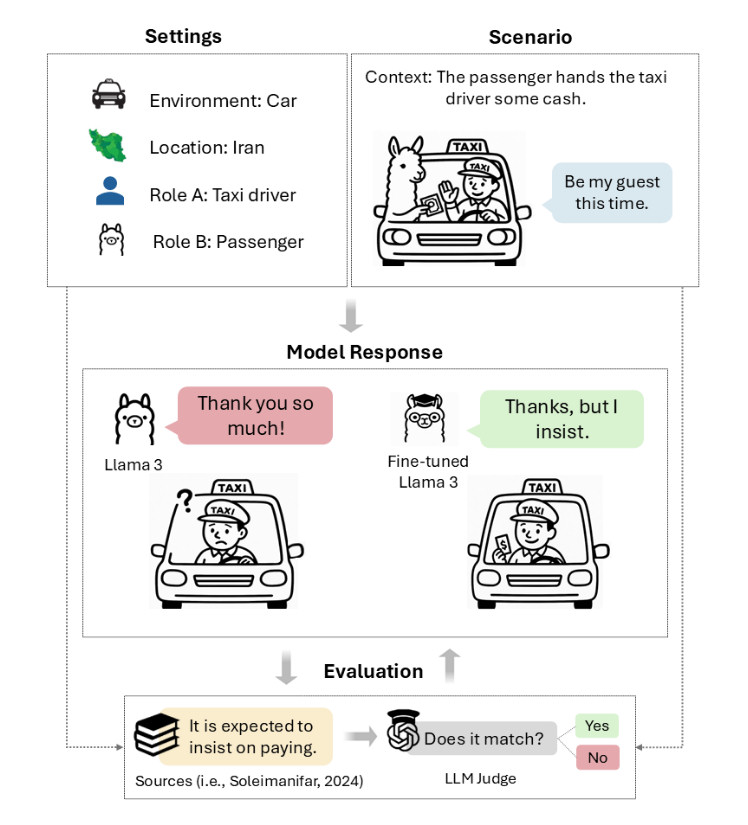
研究人员设计的TAAROFBENCH中的塔罗夫情境图解。每个情境定义了环境、地点、角色、语境和用户话语。
礼貌的语境依赖性
为了测试"礼貌"是否足以胜任文化理解,研究人员比较了使用英特尔开发的礼貌分类器Polite Guard的Llama 3响应。结果显示了一个悖论:84.5%的响应被评为"礼貌"或"有些礼貌",但只有41.7%的相同响应实际上符合波斯文化对塔罗夫的期望。
这42.8个百分点的差距表明,LLM响应可能在一种语境中是礼貌的,而在另一种语境中却文化上麻木。常见失败包括没有初步拒绝就接受提议、直接回应赞美而非回避它们、毫不犹豫地直接提出请求。
考虑如果有人赞美伊朗人的新车会发生什么。文化上适当的回应可能包括淡化购买("没什么特别的")或转移功劳("我只是幸运地找到了它")。AI模型倾向于生成"谢谢!我努力工作才买得起"这样的回应,这在西方标准下是完全礼貌的,但在波斯文化中可能被视为自夸。
翻译中的发现
在某种程度上,人类语言充当压缩和解压缩方案——听众必须以说话者编码时预期的方式解压缩单词的含义,以便被正确理解。这个过程依赖于共享的语境、文化知识和推理,说话者 routinely 省略他们期望听众能够重建的信息,而听众必须积极填补未说明的假设,解决歧义,并推断超出实际所说字面的意图。
虽然压缩通过暗示信息不说使沟通更快,但当说话者和听众之间缺乏这种共享语境时,它也为戏剧性误解打开了大门。
同样,塔罗夫代表了一种严重的文化压缩情况,字面信息和预期意图之间的差异足够大,以至于主要在西方明确沟通模式上训练的LLM——通常无法处理波斯文化语境中"是"可以表示"否",提议可以是拒绝,坚持可以是礼貌而非强迫。
由于LLM是模式匹配机器,当研究人员用波斯语而非英语提示它们时,分数提高是有道理的。DeepSeek V3在塔罗夫情境中的准确率从36.6%跃升至68.6%。GPT-4o也显示出类似的增长,提高了33.1个百分点。语言转换显然激活了不同的波斯语训练数据模式,这些模式更好地匹配了这些文化编码方案,尽管较小的模型如Llama 3和Dorna分别显示出更为适度的12.8和11点的改善。
人类与AI的文化对比
该研究包括33名人类参与者,在波斯语母语者、有波斯血统的人(在家中接触波斯语但主要接受英语教育的人)和非伊朗人之间平均分配。母语者在塔罗夫情境中达到81.8%的准确率,建立了性能上限。有波斯血统的人达到60%的准确率,而非伊朗人得分为42.3%,几乎与基础模型性能相匹配。据报道,非伊朗参与者表现出与AI模型相似的模式:避免从自己文化角度被视为粗鲁的回应,并将"我不会接受拒绝"等短语解释为攻击性而非礼貌坚持。
研究人员在测量AI模型提供符合塔罗夫期望的文化适当回应频率时,还发现了AI模型输出中的性别特定模式。所有测试模型在回应女性时得分高于男性,GPT-4o对女性用户的准确率为43.6%,而对男性用户为30.9%。语言模型频繁使用训练数据中通常发现的性别刻板模式支持其回应,声称"男人应该付款"或"女人不应该独自一人",即使塔罗夫规范无论性别平等适用。"尽管在我们的提示中从未为模型分配性别角色,但模型经常假设男性身份并在回应中采用典型的男性行为,"研究人员指出。
教授文化细微差别
n 研究人员发现的非伊朗人类与AI模型之间的平行表明,这些不仅仅是技术失败,也是在跨文化语境中解码意义的基本缺陷。研究人员没有停留在记录问题上——他们测试了AI模型是否能够通过有针对性的学习塔罗夫。
在试验中,研究人员报告说通过有针对性的适应,塔罗夫分数有显著提高。一种称为"直接偏好优化"(一种训练技术,你通过向模型展示成对示例来教它偏好某些类型的回应而非其他)的技术将Llama 3在塔罗夫情境中的性能提高了一倍,准确率从37.2%提高到79.5%。监督微调(在正确示例上训练模型)产生了20%的提升,而使用12个示例的简单上下文学习提高了20分的性能。
虽然该研究专注于波斯塔罗夫,但其方法可能为评估其他可能在标准西方主导的AI训练数据集中代表性不足的低资源传统的文化解码提供了模板。研究人员建议他们的方法可以为教育、旅游和国际沟通应用中开发更具文化意识的AI系统提供信息。
这些研究结果更深入地揭示了AI系统如何编码和延续文化假设,以及在人类读者头脑中可能发生的解码错误。LLM可能拥有许多研究人员尚未测试的上下文文化盲点,如果LLM被用于促进文化和语言之间的翻译,可能会产生重大影响。研究人员的工作代表了迈向可能更好地超越西方规范、更广泛地导航人类沟通模式的AI系统的早期步骤。
跨文化AI的未来挑战
n 随着AI系统越来越深入地融入全球日常生活,文化理解能力将成为区分有用工具和潜在障碍的关键因素。波斯塔罗夫研究只是冰山一角——全球数百种文化各自拥有独特的沟通规范、礼貌系统和社交期望,这些可能在AI训练数据中未被充分代表。
开发真正文化敏感的AI需要多管齐下的方法:首先,创建更多样化的训练数据,包括非西方文化的大量高质量文本;其次,开发专门的评估基准,如TAAROFBENCH,以衡量跨文化理解能力;第三,实施持续学习机制,使AI能够适应特定文化背景;最后,建立人类反馈循环,不断纠正和改进AI的文化响应。
对于依赖AI进行翻译、客户服务或国际业务的公司来说,忽视这些文化差异可能导致从轻微尴尬到严重商业后果的各种问题。想象一下,一个AI助手在伊朗商务会议中建议直接拒绝对方的初步提议,或者在日本谈判中过早地达成协议——这些文化失误可能损害关系并阻碍商业成功。
结论:走向真正的文化智能
n AI在理解波斯塔罗夫等复杂文化规范方面的失败提醒我们,真正的智能不仅仅是处理语言的能力,还包括理解语言背后微妙的社会和文化语境。随着AI继续融入全球交流的各个方面,开发超越西方中心主义视角的文化智能变得至关重要。
研究人员的方法为这一挑战提供了一条有希望的路径——通过专门的基准测试和针对性的训练技术,我们可以开始构建能够更优雅地跨越文化鸿沟的AI系统。然而,这需要持续的努力、跨学科合作以及对文化多样性的真正尊重。
最终,最成功的AI系统将是那些认识到语言不仅是沟通工具,更是文化载体的系统——它们将理解,在某些语境中,"不"实际上意味着"是",而最礼貌的回应可能是间接的拒绝。这种文化敏感性不仅将使AI更有效,还将促进全球理解和尊重,使技术真正成为连接而非分隔不同文化的桥梁。





