
在人工智能快速发展的今天,数据隐私问题日益凸显。科技公司为了构建更强大的AI模型,不断寻找更多高质量训练数据,这一过程中可能涉及大量敏感用户信息。面对这一挑战,Google Research团队近日推出了一项创新成果——VaultGemma,这是谷歌首个采用隐私保护技术的大语言模型(LLM),为AI行业的数据隐私保护树立了新标杆。
隐私泄露:AI模型的隐忧
大语言模型(LLMs)具有非确定性输出的特点,这意味着即使输入相同内容,模型也可能产生不同的回答。然而,模型有时会"复述"其训练数据中的内容,这带来了严重的隐私风险。如果训练数据包含个人信息,模型在输出中重现这些内容就可能构成用户隐私泄露。同样,当版权数据意外或有意地进入训练数据集时,模型输出中出现的这些内容也会给开发者带来法律风险。
Google Research团队指出,随着科技公司不断从网络中搜集更多数据来训练模型,这种隐私泄露风险正在加剧。传统的差分隐私技术通过在训练阶段引入校准噪声来防止此类记忆问题,但这一技术长期以来面临着准确性和计算需求的挑战。
差分隐私:平衡隐私与性能
差分隐私技术通过在训练数据中添加随机噪声,使得模型无法精确记忆任何特定训练样本。这种方法理论上可以防止模型输出中的隐私信息泄露,但同时也带来了模型性能下降和计算资源需求增加的问题。
在VaultGemma项目中,Google Research团队首次系统性地研究了差分隐私对AI模型扩展定律的影响。他们假设模型性能主要受噪声批次比(noise-batch ratio)的影响,这一指标比较了随机噪声量与原始训练数据量的大小。
通过在不同模型大小和噪声批次比条件下进行实验,团队建立了差分隐私扩展定律的基本理解,这需要在计算预算、隐私预算和数据预算之间取得平衡。简单来说,更多的噪声会导致输出质量下降,除非通过更高的计算预算(FLOPs)或数据预算(tokens)来抵消。
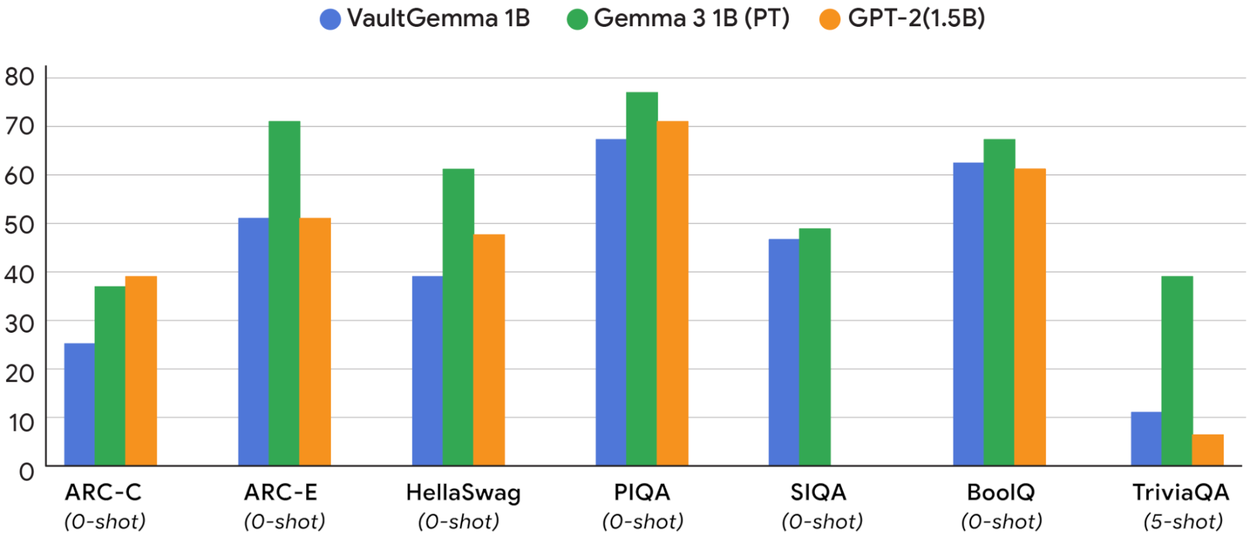
VaultGemma与同等规模非隐私AI模型的性能对比
VaultGemma:理论与实践的结合
基于差分隐私的研究成果,Google推出了名为VaultGemma的新开源模型。这一模型基于Gemma 2基础模型构建,虽然只有10亿参数,规模并不大,但Google Research表示其性能可与同规模的非隐私模型相媲美。
团队利用从初始测试中得出的扩展定律,以最优差分隐私技术训练了VaultGemma。这一模型不仅展示了隐私保护技术的可行性,也为开发者提供了参考,帮助他们更高效地分配资源来训练隐私AI模型。
值得注意的是,研究结果表明差分隐私技术在小规模LLM上效果更好,这些专用模型通常用于驱动特定的AI功能。对于规模最大、能力最强的通用模型而言,性能仍然是首要考虑因素,因此差分隐私技术可能不会立即改变这些顶级模型的运作方式。
开源与限制:VaultGemma的使用许可
用户现在可以从Hugging Face和Kaggle平台下载VaultGemma模型。与其他Gemma模型一样,VaultGemma采用开放权重,但并非完全开源。虽然谷歌允许用户修改和分发Gemma模型,但使用者必须同意不将这些模型用于恶意目的,并且在分发任何修改版本时必须附上Gemma许可证副本。
这种许可模式反映了开源社区与商业公司之间的平衡,既促进了技术创新和协作,又保护了公司的商业利益和伦理责任。
隐私保护AI的未来展望
VaultGemma的推出标志着隐私保护AI技术的重要进展。随着AI模型在各个领域的广泛应用,数据隐私保护将成为技术发展的核心考量因素之一。Google Research团队的这一工作不仅为行业提供了实用工具,也为未来AI伦理和安全标准的制定奠定了基础。
从长远来看,差分隐私技术可能会成为AI模型训练的标准组成部分,特别是在处理敏感数据的应用场景中。随着技术的不断成熟和优化,我们有望看到更多在保护隐私的同时保持高性能的AI模型出现。
此外,VaultGemma项目也展示了学术界与产业界合作的价值。通过将理论研究与实际应用相结合,Google Research不仅解决了当前的技术挑战,也为未来的研究方向提供了启示。
技术挑战与解决方案
尽管差分隐私技术为AI模型隐私保护提供了有效途径,但实施过程中仍面临诸多挑战。首先是计算资源的需求增加,添加噪声需要更多的计算能力来维持模型性能。其次是准确性的权衡,更强的隐私保护通常意味着模型输出质量的下降。
Google Research团队通过系统性的实验和分析,为这些挑战提供了量化的解决方案。他们建立的差分隐私扩展定律为开发者提供了一个理论框架,帮助他们在隐私保护、计算成本和模型性能之间做出明智的权衡。
对于小型专用模型,差分隐私技术的成本效益比更高,这使得特别适合在医疗、金融等对隐私要求极高的领域应用。而对于大型通用模型,可能需要结合其他隐私保护技术,如联邦学习、安全多方计算等,来实现全面的隐私保护。
行业影响与标准制定
VaultGemma的推出可能会对整个AI行业产生深远影响。首先,它为其他科技公司提供了一个隐私保护AI的参考实现,加速了行业最佳实践的形成。其次,它可能促使监管机构制定更明确的AI数据隐私标准和指南。
随着AI技术的普及,数据隐私问题已成为公众关注的焦点。VaultGemma等项目展示的技术进步,有助于增强用户对AI系统的信任,推动AI技术的负责任发展和应用。
此外,开源的VaultG模型为研究人员和开发者提供了一个实验平台,可以进一步探索和改进隐私保护技术。这种开放创新模式可能会催生更多突破性的研究成果,推动整个领域向前发展。
结论
Google Research团队推出的VaultGemma代表了隐私保护AI技术的重要里程碑。通过系统性地研究差分隐私对AI模型扩展定律的影响,团队不仅解决了当前的技术挑战,也为行业提供了实用的解决方案和理论指导。
VaultGemma的成功表明,隐私保护与模型性能并非不可兼得。随着技术的不断进步和优化,我们有望看到更多在保护用户隐私的同时保持高性能的AI模型出现。这不仅有助于增强用户对AI系统的信任,也将推动AI技术在更多敏感领域的应用和发展。
未来,随着隐私保护技术的进一步成熟和标准化,AI系统将能够更好地平衡创新与责任,为人类社会带来更大的价值。Google Research的这项工作,正是迈向这一目标的重要一步。





