

在AI技术飞速发展的今天,从云端向边缘侧、端侧设备的下沉已成为不可逆转的趋势。随着消费者对设备本地运行AIGC的需求爆发性增长,一场围绕端侧AI算力的"军备竞赛"已经打响。智能手机、AI PC、智能汽车等终端设备正面临如何在功耗、散热和成本都受到严格限制的情况下,高效运行动辄数十亿参数大模型的严峻挑战。正是在这一行业背景下,安谋科技(Arm China)于11月13日在上海正式发布"周易"X3 NPU IP,不仅标志着其"All in AI"产品战略的正式启动,更试图将端侧AIGC算力提升10倍,打造计算效率的新标杆。
前瞻布局:面向AI未来的架构设计
半导体IP行业的一个共识是,产品研发必须"面向未来5年进行前瞻布局"。安谋科技Arm China产品研发副总裁刘浩在发布会上强调,公司将持续加大投入,以"前瞻性视野整合顶尖研发资源",并秉持"开放合作理念",为伙伴提供从硬件到软件的端到端解决方案。
"周易"X3正是这一前瞻性布局的产物。安谋科技Arm China NPU产品线负责人兼首席架构师舒浩博士指出,X3的产品优势源于其"通用、灵活、高效且软硬协同的系统架构设计"。这种前瞻性首先体现在架构上——"周易"X3采用了一种专为大模型而生的最新DSP+DSA架构,在设计之初就深刻理解了AI模型的演进趋势,即从传统的CNN(卷积神经网络)全面转向Transformer(大模型的基础架构)。
因此,X3采用了"兼顾CNN与Transformer的通用架构设计",使其既能高效处理传统的AI任务,也能从容应对未来几年的Gen AI(生成式AI)、Agentic AI(代理AI)与Physical AI(具身智能)的端侧落地需求。这种新架构带来的另一个关键转变,是对浮点运算的强力支持。传统AI运算(如安防)大多使用定点计算,而大模型推理则高度依赖浮点(FP)运算。X3全面增强了浮点运算(FLOPS)能力,支持从定点到浮点计算的关键转变,为承载大模型奠定了技术基石。
性能突破:解码10倍AIGC算力跃升
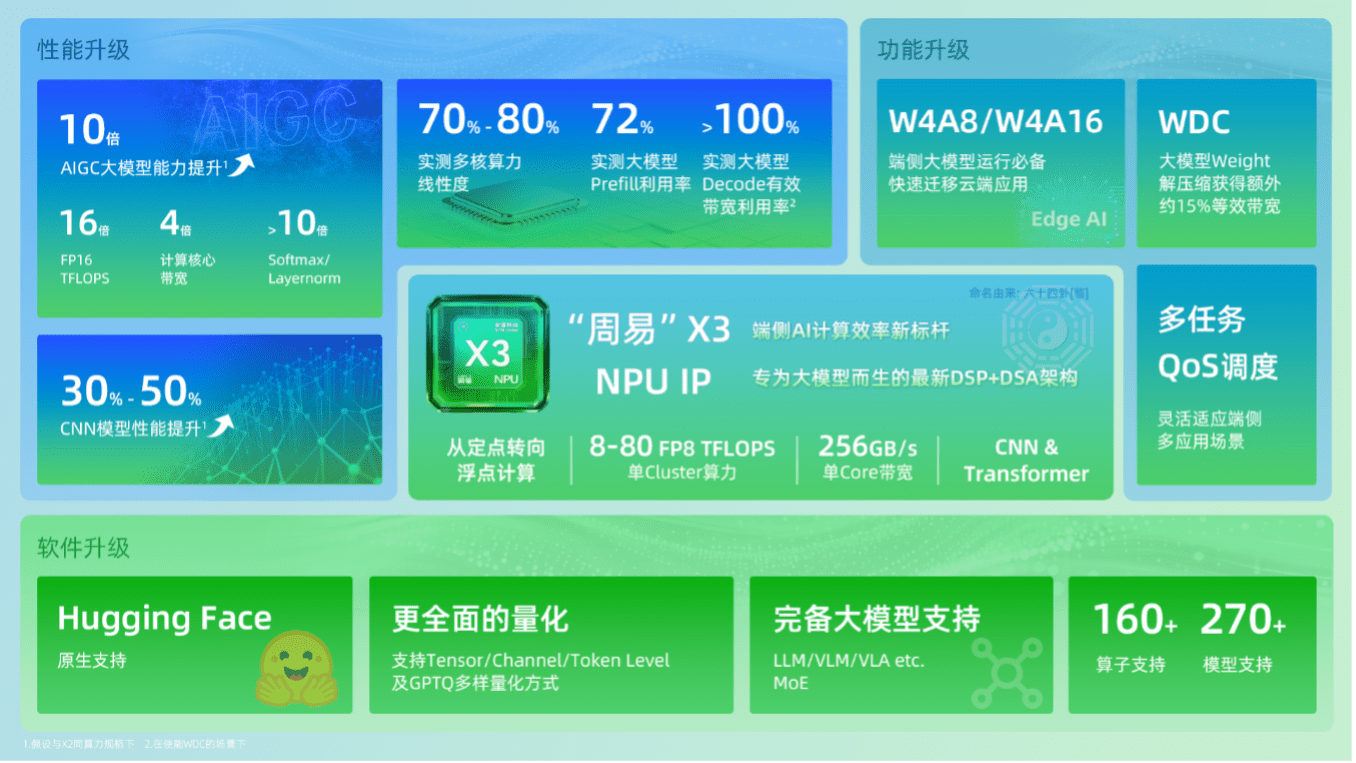
如果说架构是蓝图,那么性能数据就是最直观的成果。相较于上一代产品,"周易"X3在AIGC大模型能力上实现了高达10倍的增长。这一惊人的跃升并非单一因素造就,而是由16倍的FP16 TFLOPS(每秒万亿次半精度浮点运算)、4倍的计算核心带宽,以及超过10倍的Softmax和LayerNorm(均为大模型关键算子)性能提升共同驱动的。
在具体规格上,"周易"X3的单Cluster(集群)最高支持4个Core(核心),可提供8至80 FP8 TFLOPS(每秒万亿次8位浮点运算)的算力,并且支持灵活配置。其单核带宽高达256GB/s。即使在传统的CNN模型上,其性能也比X2提升了30%~50%。
但对于大模型而言,峰值算力(TFLOPS)只是"入场券",如何真正在运行中把算力用起来,即"算力利用率",才是核心难题。安谋科技Arm China给出一组基于Llama2 7B(70亿参数)大模型的实测数据:"周易"X3在Prefill(处理提示词)阶段的算力利用率高达72%,这是一个远超行业平均水平的数字,意味着NPU在处理用户输入时没有"出工不出力"。

更令人瞩目的是Decode(生成token)阶段的数据。安谋科技Arm China宣称,在自研解压硬件WDC的加持下,X3实现了"Decode阶段有效带宽利用率超100%"。"有效带宽超100%"听起来有悖常理,但这背后是安谋科技Arm China解决端侧带宽瓶颈的"独门武器"。这个名为WDC的自研解压硬件,允许大模型的权重(Weights)以软件无损压缩的形式存储。在NPU运算需要调用这些权重时,WDC硬件会实时进行解压。这一过程对软件透明,却能带来15%~20%的等效带宽提升。换言之,它让有限的物理带宽"跑"出了远超其物理限制的数据量,从而极大满足了大模型解码阶段对高吞吐量的渴求。
技术创新:从硬件到软件的全链路支持
"周易"X3不仅仅是一块高性能的硬件IP,它还配套了一个名为"Compass AI"的软件平台。安谋科技Arm China产品总监鲍敏祺指出,X3遵循"软硬协同、全周期服务与成就客户"的准则,旨在提供从硬件、软件到售后服务的全链路支持。
在AI落地过程中,软件开发的"适配难、周期长、门槛高"是长期存在的痛点。"Compass AI"平台的目标,就是通过"软硬一体"的协同设计,让开发者从"好用"进阶到"用好"。
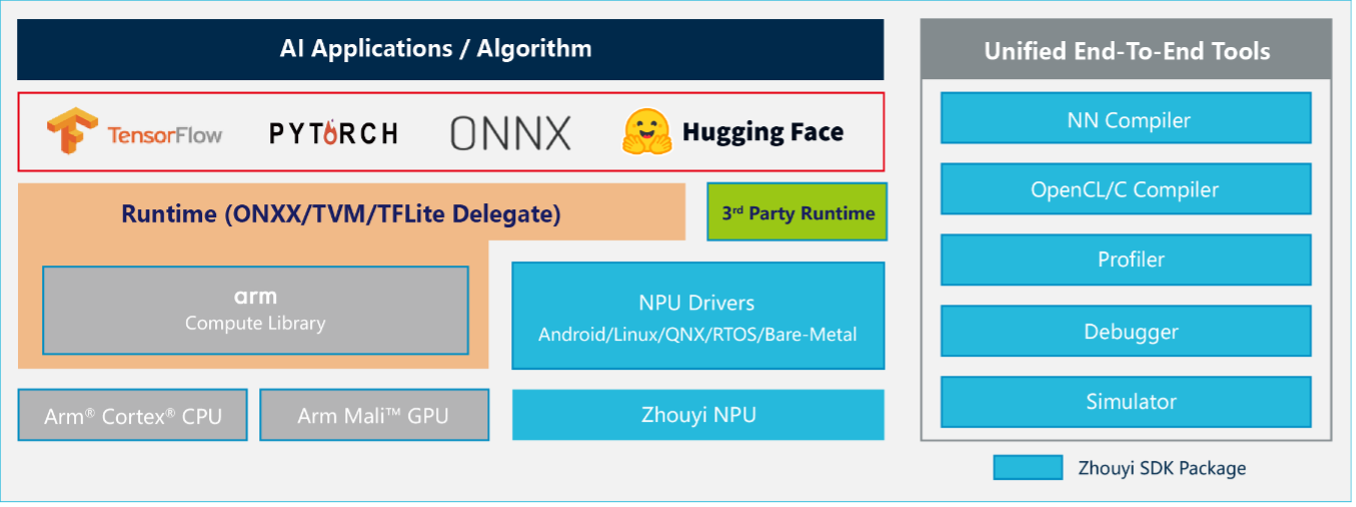
该平台的核心是NN Compiler(神经网络编译器)。它支持TensorFlow、ONNX、PyTorch等主流AI框架,兼容超过160种算子和270种模型。对于当前火热的大模型生态,"Compass AI"平台提供了一个极具吸引力的功能:通过其AIPULLM工具链,可直接支持Hugging Face格式模型,实现"一站式"转化与部署。Hugging Face是全球最大的AI模型集散地,这一功能意味着开发者可以极低门槛地将社区的前沿模型快速部署到"周易"X3上。
该平台还具备先进的模型推理优化能力,包括业界领先的大模型动态shape支持(能高效处理任意长度的输入序列),并支持GPTQ等主流量化方案,以及对LLM(大语言模型)、VLM(视觉语言模型)和MoE(混合专家模型)的高性能支持。
更重要的是,安谋科技Arm China选择了"开放生态"路线。Compass平台中的Parser(模型解析)、Optimizer(优化器)、Linux Driver(驱动)等核心组件已相继开源。这为开发者提供了"白盒"部署的可能,他们可以利用丰富的调试工具和Bit精度软件仿真平台进行深度性能调优。有能力的客户甚至可以利用平台提供的工具和接口,开发自定义算子,乃至打造出"属于自己的模型编译器",从而实现产品差异化。
这种"软硬协同"贯穿了X3的设计始终。例如AIFF模块,硬件团队通过增大总线带宽、增加DMA(直接内存访问)的outstanding等方式提升数据搬运效率;软件团队则针对性设计专属使用模式,如对模型进行合理切分,以充分发挥多核并行优势。在系统兼容性上,Compass平台也做到了全面覆盖,支持Android、Linux、RTOS、QNX等多种操作系统,并通过TVM/ONNX实现SoC异构计算。
应用场景:从单一感知到复杂认知
"周易"X3的发布,清晰地勾勒出了安谋科技Arm China面向的四大核心领域:基础设施、智能汽车、移动终端和智能物联网。
在发布会现场的demo展示区,安谋科技Arm China展示了"周易"IP家族的演进:从Z1赋能AIoT的人脸识别,到Z2/Z3进入入门级座舱和辅助驾驶,再到X1/X2运行自动泊车、Stable Diffusion文生图。而新旗舰"周易"X3则全面展示了其作为"端侧大模型杀手"的实力,现场演示了运行DeepSeek-R1-Distill-Qwen-1.5B模型的流畅AI对话,以及运行Stable Diffusion v1.5的文生图和MiniCPM v2.6的多模态图文理解。

这一演进路径,清晰地表明端侧AI已从单一的功能感知,迈向了融合多种模型的"复杂认知"新阶段。
智能汽车领域
这是X3的重点目标。它将同时赋能智能驾驶与智能座舱,在ADAS系统中为自动泊车等功能提供AI算力;在IVI(车载信息娱乐系统)中,则支持基于语音和车内外视频的智能互动。随着自动驾驶级别的提升,对端侧算力的需求呈指数级增长,X3的高性能和低延迟特性使其成为这一领域的理想选择。
移动终端领域
在AI PC和AI手机上,X3可用于超分渲染(提升显示效果),并为基于大模型的AI Agent应用提供澎湃算力。随着用户对设备智能化要求的提高,本地运行大模型可以实现更快的响应速度和更好的隐私保护,X3的10倍算力提升将使这些应用成为现实。
基础设施与物联网
在加速卡、智能IPC(网络摄像机)、智能网关等设备中,X3的本地AI推理能力将带来更快的响应速度和更好的隐私保护。对于边缘计算场景,X3的高能比特性可以在有限功耗下提供强大算力,满足实时AI处理的需求。
行业影响:构建AI时代的计算基石
"周易"X3的发布,标志着安谋科技Arm China"All in AI"产品战略的正式启动。在"AI Arm CHINA"的战略发展方向下,安谋科技Arm China正携手生态伙伴,试图加快构建国内"AI+"产业升级的智能计算基石,为千行百业的智能化转型提供更强的IP"核芯"动力。
随着AI大模型从云端向边缘侧、端侧设备下沉,端侧AI算力的重要性日益凸显。安谋科技通过"周易"X3 NPU的发布,不仅解决了当前端侧AI大模型运行的诸多痛点,更为未来AI技术的发展奠定了坚实基础。从"周易"X3的技术创新和应用拓展可以看出,端侧AI正从单一功能感知向复杂认知演进,这一转变将深刻影响智能汽车、移动终端和物联网等领域的发展格局。
在AI技术飞速发展的今天,算力已成为核心竞争力。安谋科技通过"周易"X3 NPU的发布,不仅展示了其在半导体IP领域的技术实力,更体现了其对AI未来发展趋势的深刻洞察。随着"周易"X3的广泛应用,我们有理由相信,端侧AI将迎来更加广阔的发展空间,为人类社会带来更加智能、高效的未来体验。










