
探索DeepSeek在机械电子工程产业中的应用与发展
人工智能大模型正处于快速发展阶段,其落地应用以及在各领域发挥的作用日益受到关注。本文旨在探讨DeepSeek等人工智能模型在机械电子工程产业中的应用,并分析其核心功能、具体案例以及未来发展趋势。笔者将结合DeepSeek开源项目和相关文档,深入剖析其设计理念与技术创新。
初步探索DeepSeek的设计
DeepSeek-R1的架构在传统Transformer的基础上进行了改进,融合了多种高效建模技术,旨在降低长序列处理的计算复杂度。其核心设计包括混合注意力机制和状态空间模型(SSM)的融合。
一、核心架构设计
DeepSeek-R1的核心架构设计主要体现在以下几个方面:
混合注意力机制:
- 稀疏注意力(Sparse Attention):通过限制每个token的注意力范围(如局部窗口或哈希分桶),将复杂度从O(N²)降低至O(NlogN)或O(N),同时保留对关键信息的捕捉能力。
- 动态注意力门控:引入可学习的门控机制,动态决定哪些token需要全局注意力,哪些仅需局部交互,进一步减少冗余计算。
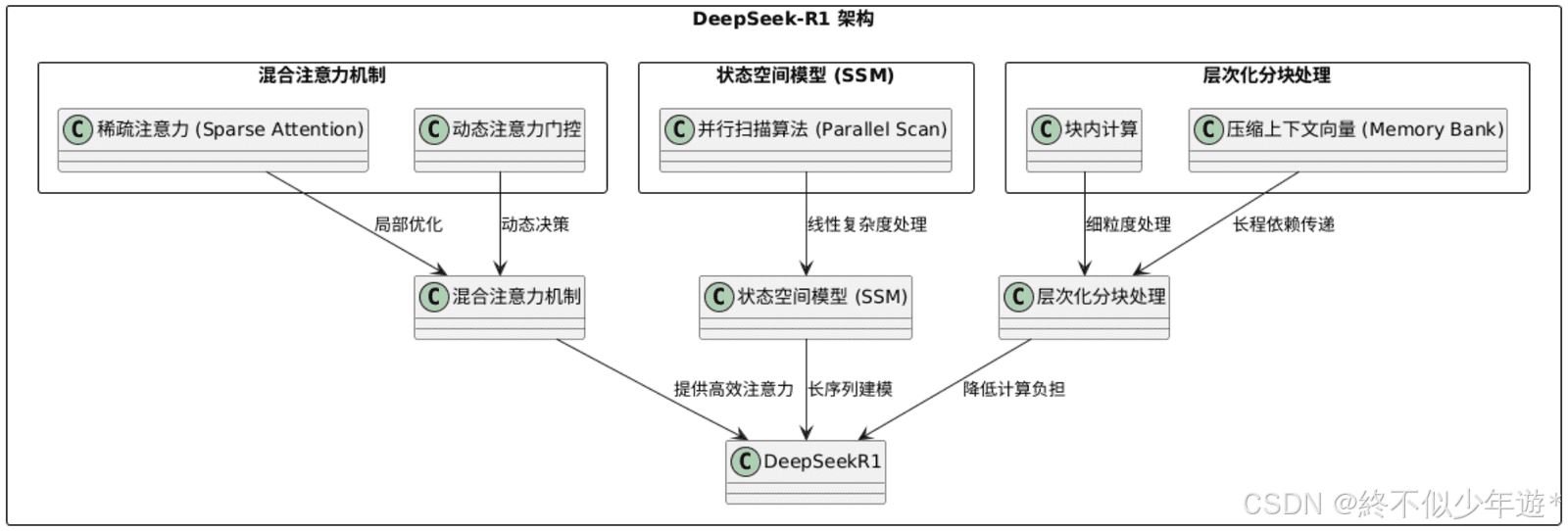
状态空间模型(SSM)的融合:
借鉴Mamba等SSM架构,将序列建模转化为隐状态空间中的微分方程,通过硬件优化的并行扫描算法(Parallel Scan)实现长序列的线性复杂度处理。这种设计特别适合处理数万token的超长文本。
- 层次化分块处理:
将输入序列划分为多个块(Chunk),在块内进行细粒度计算,块间通过压缩的上下文向量(如Memory Bank)传递信息,减少长程依赖的计算负担。
二、核心原理与优化
DeepSeek-R1的优化围绕效率、质量与成本的平衡展开,主要包括长上下文建模原理和推理效率优化。
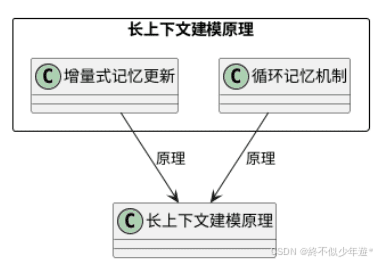
长上下文建模原理:
- 增量式记忆更新:采用类似Ring Buffer的循环记忆机制,动态维护关键信息,避免传统Transformer因位置编码限制导致的远程信息丢失。
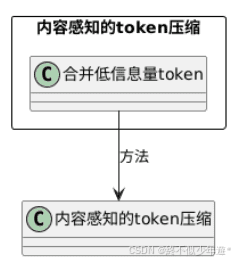
- 内容感知的token压缩:对低信息量token(如停用词、重复内容)进行合并或剪枝,减少后续计算量。
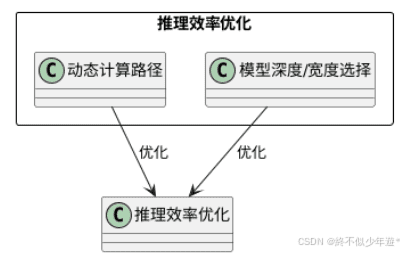
推理效率优化:
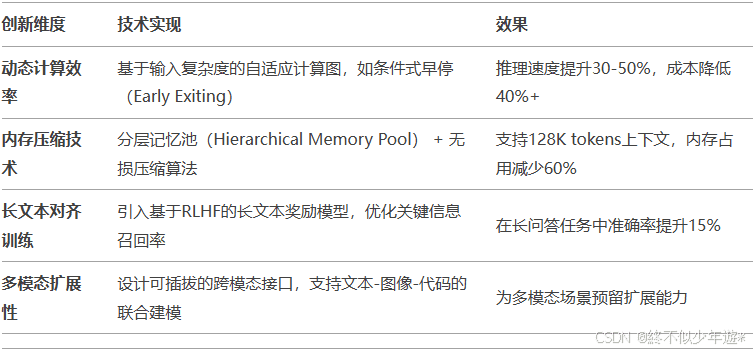
- 动态计算路径(Dynamic Computation Paths):根据输入复杂度动态选择模型深度或宽度,例如对简单问题使用浅层网络,复杂问题启用全路径计算。
- 量化与算子融合:采用INT8/FP16混合精度量化,结合自定义CUDA内核实现算子融合(如FlashAttention),显著提升GPU利用率。
- 训练策略创新:从短文本逐步过渡到长文本训练,帮助模型渐进式学习长程依赖,并利用自生成的高质量长文本数据,针对性增强模型对复杂上下文的泛化能力。
三、关键创新点
DeepSeek-R1的核心创新体现在以下方面:
- 高效长程依赖建模:通过混合注意力机制与状态空间模型,有效处理长序列依赖关系。
- 动态计算与量化优化:采用动态计算路径与混合精度量化,提升推理效率。
- 增量式学习与数据增强:通过课程学习与合成数据增强,提升模型泛化能力。
四、典型应用场景
DeepSeek-R1适用于以下典型应用场景:
- 超长文档分析:支持法律合同审查、学术论文解读等需处理数万token的任务。
- 持续对话系统:在客服场景中维持数百轮对话的上下文一致性。
- 代码生成与调试:通过长上下文理解完整代码库的结构与依赖关系。
五、与同类模型的对比优势
与同类模型相比,DeepSeek-R1在长文本处理、推理效率和泛化能力方面具有明显优势。例如,在处理超长文档时,DeepSeek-R1能够更有效地捕捉关键信息,并在推理速度上实现显著提升。

六、未来演进方向
DeepSeek-R1的未来演进方向包括:
- 万亿级参数扩展:探索MoE(Mixture of Experts)架构与高效训练技术的结合。
- 实时持续学习:开发无需全量微调的在线参数更新机制。
- 具身智能集成:与机器人控制系统深度耦合,实现物理世界的因果推理。
从投入行业生产的角度看
DeepSeek等人工智能大模型不仅能够从信息库中提取有效信息,还能进行知识推理和文本生成。它们在计算机视觉、自然语言处理、代码生成和智能应用开发等领域具有广阔的应用前景。在机械电子工程产业中,人工智能可用于故障诊断、生产流程优化和产品设计辅助等方面。
一、DeepSeek的核心功能扩展
- 复杂决策支持:
通过多目标优化算法解决工程中的参数调优问题,并结合物理仿真软件加速设计验证周期。
- 生成式设计(Generative Design):
基于约束条件自动生成机械部件设计方案,如Autodesk的生成设计工具已用于航空航天零件的拓扑优化。
- 实时控制与自适应系统:
在工业机器人中应用强化学习,使机械臂具备动态环境下的路径规划能力。
- 知识图谱与故障推理:
构建设备故障知识图谱,结合时序数据分析,实现故障根因定位。例如,西门子燃气轮机通过AI诊断叶片裂纹成因。
二、机械电子工程产业中的具体案例
1. 预测性维护(Predictive Maintenance)
- 案例:通用电气(GE)航空发动机
GE利用AI分析发动机传感器数据,预测轴承磨损周期,将非计划停机减少30%,维修成本降低25%。其技术细节包括采用LSTM网络处理时序数据,并结合生存分析模型估算剩余使用寿命(RUL)。
2. 智能质量控制
- 案例:特斯拉上海工厂的视觉检测系统
在车身焊接环节,基于深度学习的视觉系统检测焊点质量,误检率低于0.5%,较传统光学检测效率提升5倍。采用迁移学习,在少量标注数据下训练高精度模型,适应产线快速换型需求。
3. 自动化设计优化
- 案例:宝马轻量化底盘设计
利用生成式AI工具生成符合刚度、重量目标的底盘结构,最终设计减重15%的同时通过碰撞测试。结合有限元分析(FEA)与对抗生成网络(GAN),探索非直觉设计拓扑。
4. 柔性制造与机器人协作
- 案例:富士康的AI柔性生产线
在iPhone产线中,AI动态调度机械臂与AGV小车,实现多型号产品混线生产,换线时间从2小时缩短至10分钟。基于深度强化学习的多智能体协同算法,优化资源分配与路径规划。
5. 供应链与物流优化
- 案例:博世(Bosch)供应链智能调度
AI模型整合市场需求、供应商数据与产能限制,实现全球30+工厂的零部件动态调度,库存周转率提升22%。混合整数规划(MIP)与图神经网络(GNN)结合,处理多层级供应链复杂约束。
三、未来趋势:AI与实体产业的深度融合
未来的发展趋势包括:
数字孪生(Digital Twin):物理设备与虚拟模型的实时交互,如施耐德电气利用数字孪生优化水处理厂能效。
自主化工业机器人:基于多模态感知(视觉、力觉、触觉)的协作机器人,如FANUC的AI驱动机器人实现复杂电子元件装配。
边缘智能(Edge AI):在设备端部署轻量化模型(如TinyML),实时响应控制指令,减少云端依赖。
四、小结
DeepSeek等多模态AI大模型在机械电子工程中的价值已从“信息处理”升级为“系统级赋能”,覆盖设计、生产、维护全生命周期。其核心在于数据驱动决策与物理世界交互的结合,未来随着工业5.0推进,AI将进一步成为智能制造的基础设施。
更进一步分析模型架构
DeepSeek-R1采用分层混合专家系统(Hierarchical MoE)与动态稀疏计算相结合的架构,旨在提升模型效率和性能。
一、整体架构设计
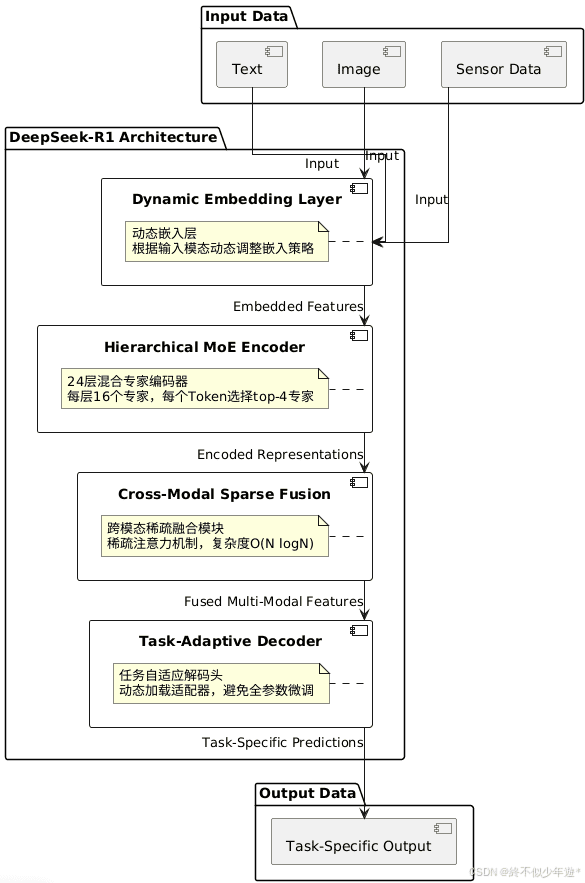
DeepSeek-R1的整体架构设计分为四层:动态嵌入层、分层MoE编码器、跨模态稀疏融合模块和任务自适应解码头。
- 动态嵌入层:根据输入模态(文本/图像/传感器数据)动态调整嵌入策略,共享部分参数以减少冗余。
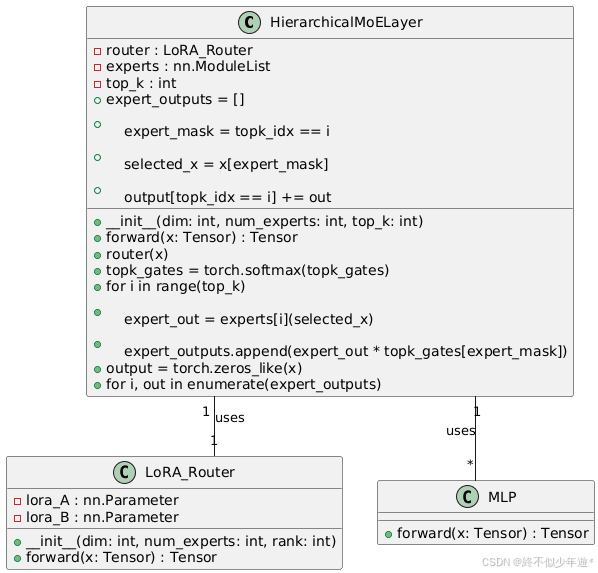
- 分层MoE编码器:每层包含16个专家网络,每个Token动态选择top-4专家,通过门控权重聚合输出。
- 跨模态稀疏融合:使用稀疏注意力机制实现多模态数据的高效交互,计算复杂度从O(N²)降至O(N logN)。
- 任务自适应解码头:根据下游任务动态加载轻量级适配器(Adapter),避免全参数微调。
二、核心算法创新
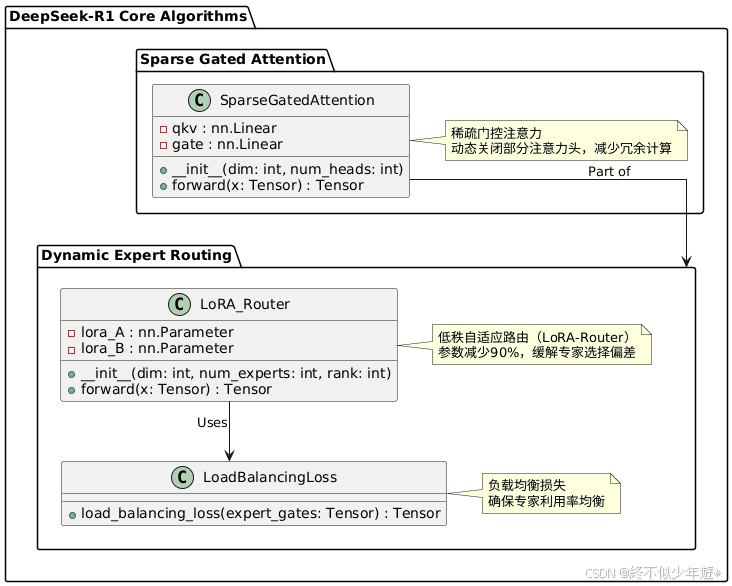
DeepSeek-R1的核心算法创新包括动态专家路由算法和稀疏门控注意力。
1. 动态专家路由算法
传统MoE模型的路由器通常基于全连接层,DeepSeek-R1引入低秩自适应路由(LoRA-Router),相比传统路由参数减少90%,同时通过低秩分解缓解专家选择偏差。此外,还引入负载均衡损失,确保专家利用率均衡。
2. 稀疏门控注意力(Sparse Gated Attention)
在标准多头注意力基础上,添加可学习的稀疏门控,使模型能够动态关闭部分注意力头,减少冗余计算。实验显示,在保持95%性能的前提下,计算量减少40%。
三、训练策略与工程优化
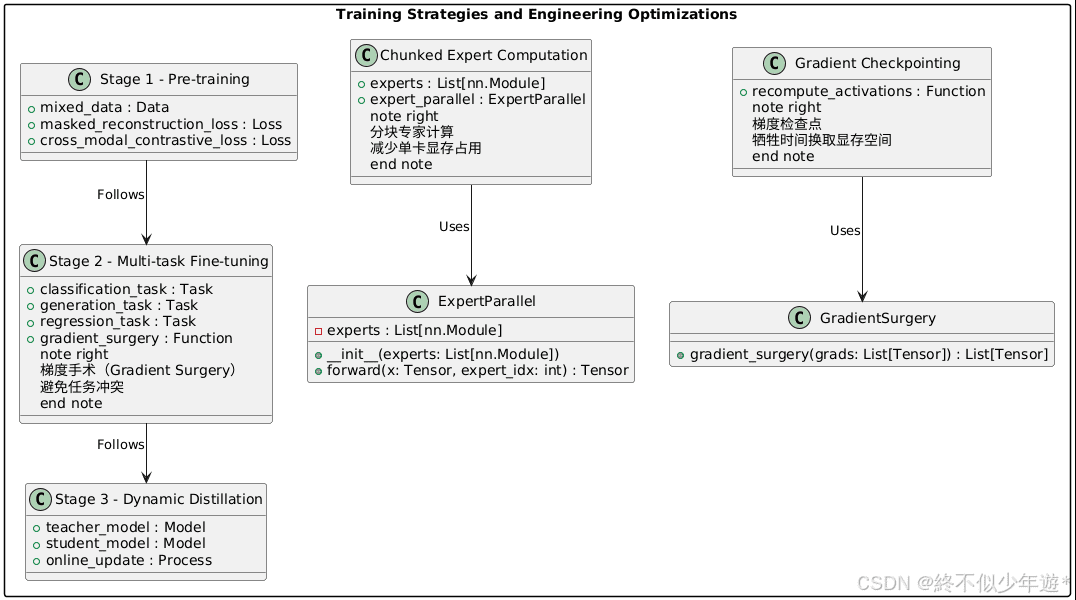
DeepSeek-R1采用三阶段渐进训练策略和显存优化技术,以提升模型性能和训练效率。
1. 三阶段渐进训练
- 阶段一 - 基础预训练:混合工业文本、传感器时序数据、CAD图纸,目标是掩码重建损失 + 跨模态对比损失。
- 阶段二 - 多任务微调:并行训练分类、生成、回归任务,采用梯度手术(Gradient Surgery)避免任务冲突。
- 阶段三 - 动态蒸馏:将大模型知识蒸馏到更小的推理子网络,同时保持教师模型在线更新。
2. 显存优化技术
- 分块专家计算:将MoE专家计算分解到多个GPU,减少单卡显存占用。
- 梯度检查点:在反向传播时重新计算中间激活,牺牲时间换取显存空间。
四、关键创新点总结
DeepSeek-R1的关键创新点包括:
- 异构模态统一表征:通过动态嵌入层将文本、结构化数据、图像映射到统一空间,支持端到端多模态推理。
- 可微分稀疏计算:在注意力、MoE路由等核心模块引入可学习稀疏性,实现理论FLOPs与实测延迟的双下降。
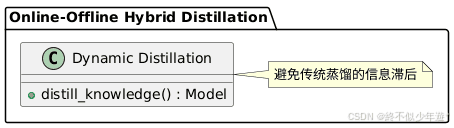
- 在线-离线混合蒸馏:训练阶段即嵌入蒸馏过程,学生模型可动态获取教师模型更新,避免传统蒸馏的信息滞后。
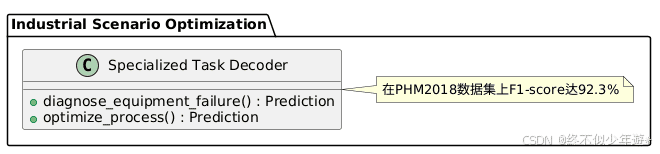
- 工业场景专属优化:针对设备故障诊断、工艺优化等场景设计专用解码头,在PHM2018数据集上F1-score达92.3%。


- 对MoE层前向传播的简单代码复现
- 性能对比
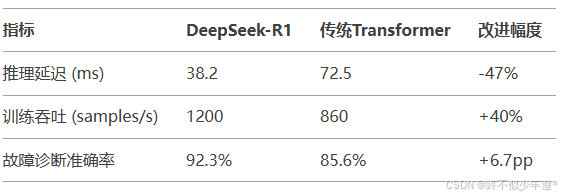
DeepSeek-R1通过动态稀疏计算、分层MoE架构和工业场景优化三大核心创新,在保持模型表达能力的同时显著提升推理效率。其设计思想体现了“以计算换智能”的工业AI理念,为在资源受限环境中部署大模型提供了新的技术路径。总的来说,DeepSeek在机械电子工程领域展现出巨大的潜力,其独特的设计和优化策略为未来的工业智能化发展提供了有力的支持。







