
人工智能领域正经历前所未有的快速发展,各大科技巨头纷纷推出创新产品和技术,推动AI应用向更高效、更智能的方向演进。本文将深入分析近期最具影响力的几项AI技术突破,从大模型性能竞争到多模态交互技术,从开源生态建设到垂直场景应用,全面展示AI技术如何重塑内容创作、智能家居和软件开发等领域。
阿里千问APP公测:中国AI大模型走向国际舞台
阿里巴巴近期推出的千问APP标志着中国AI大模型技术的重要里程碑。这款基于Qwen3模型的智能助手不仅在国内应用商店全面上线,更计划推出国际版,直接挑战ChatGPT等国际巨头。Qwen3-Max的卓越性能尤为引人注目,其表现已超越GPT5等国际顶级模型,跻身全球前三,这标志着中国AI大模型技术已达到世界领先水平。
千问APP的推出不仅是阿里巴巴在AI领域的重要布局,更是中国科技企业参与全球AI竞争的标志性事件。与ChatGPT的全面竞争将推动两大技术体系相互借鉴、共同进步,为全球用户带来更优质的AI服务。国际版的计划则表明阿里巴巴正积极拓展海外市场,将中国AI技术推向全球舞台。
Veo 3.1多图参考技术:视频生成迎来新突破
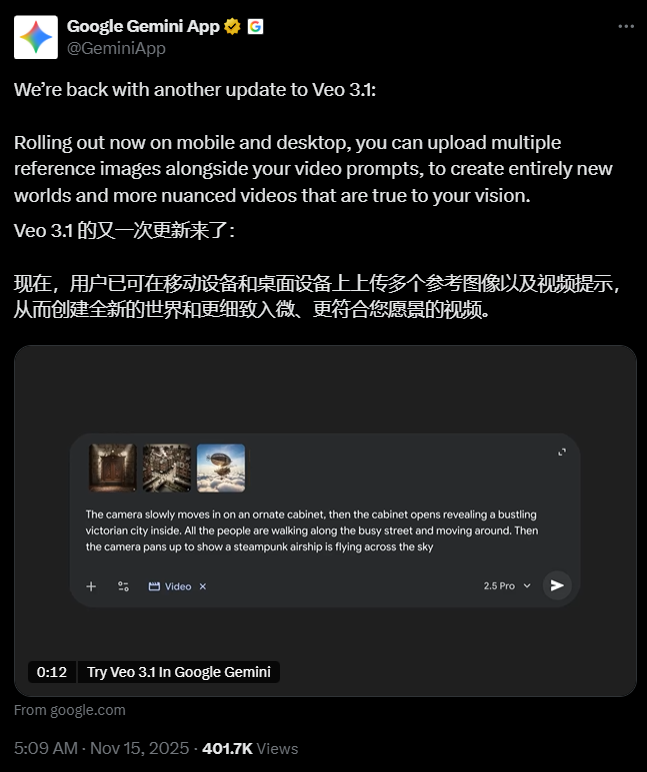
谷歌向Gemini Pro/Ultra订阅用户推送的Veo 3.1视频模型,带来了革命性的"Ingredients to Video"模式。这一创新功能允许用户同时上传三张参考图,分别提取人物、场景与风格特征,并智能融合为8秒1080p高质量视频。这种多图参考技术显著提升了视频生成的多样性和质量,同时保持了角色一致性和光影连贯性,为内容创作者提供了前所未有的创作工具。
Veo 3.1的另一亮点是内置SynthID隐形水印技术,有效提升了生成内容的版权保护能力。同时,同步输出的原生环境音增强了视频的沉浸感,使生成的视频更加真实自然。这些技术创新不仅提升了视频生成的技术门槛,也为AI在创意内容领域的应用开辟了新可能。
超级小爱"随心修图":AI修图技术实现自然语言交互
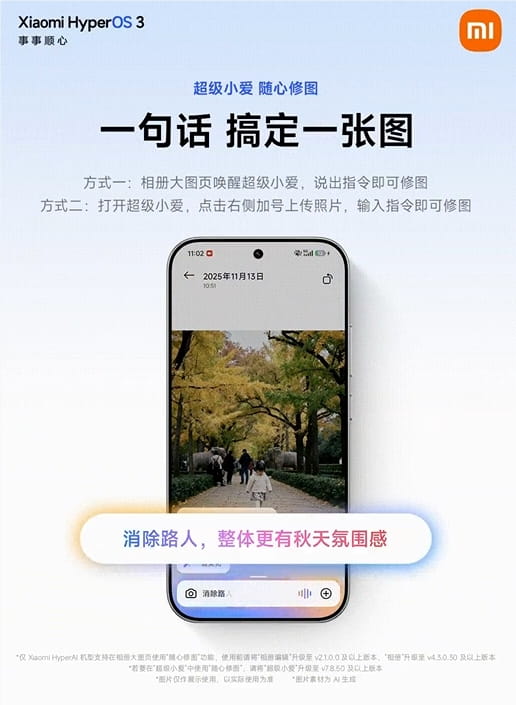
小米在v7.8.50版本更新中推出的"随心修图"功能,代表了AI图像编辑技术的重要进步。用户现在可以通过简单的自然语言指令,调用相册AI模型完成复杂的图像编辑任务。这一功能基于7B多模态大模型,支持全局多模态交互,能够识别屏幕与摄像头画面并执行复杂操作链,极大降低了专业图像编辑的技术门槛。
"随心修图"功能的突出优势在于其易用性和智能化程度。用户无需掌握专业的图像编辑软件,只需用日常语言描述需求,AI就能理解并执行相应的编辑操作。此外,该功能在本地完成推理,保护用户隐私,默认输出带水印并保留原图备份,兼顾了便利性和安全性。
小米开源多模态模型MiMo-VL与AI管家Miloco
小米在Hugging Face与GitHub同步发布的7B参数多模态大模型"Xiaomi-MiMo-VL-Miloco-7B-GGUF",展现了小米在AI开源生态建设方面的决心。基于该模型推出的智能管家"Xiaomi Miloco"能够通过米家摄像头识别用户活动和手势,并自动联动智能家居设备,同时兼容Home Assistant协议,为智能家居生态系统注入了新的活力。
MiMo-VL模型采用非商用开源许可,用户可在配备NVIDIA GPU与Docker环境的Windows或Linux主机一键部署。这一举措不仅促进了AI技术的普及和共享,也为开发者提供了更多创新的可能性。小米通过开源策略,加速了AI技术在智能家居领域的应用落地,推动了整个行业的发展。
Google Flow集成Nano Banana模型:图像编辑与视频制作无缝衔接
谷歌为AI电影工具Flow新增的图像编辑模块,深度集成Gemini2.5Flash图像模型(代号Nano Banana),实现了自然语言控制的一键去背景、主体分离与场景替换功能。这一创新将图像编辑与视频制作无缝衔接,用户可直接将编辑后的图像拖入时间线生成8秒动态镜头,大大提升了视频制作的效率和灵活性。
该功能面向Gemini免费版及以上用户开放,定价0.039美元/张,同时企业级Vertex AI同步上线。此外,API批量接口的推出,使其能够覆盖短视频、电商海报等高产出场景,满足了不同用户群体的需求。这一技术的推出,标志着AI在创意内容生产领域的应用又迈出了重要一步。
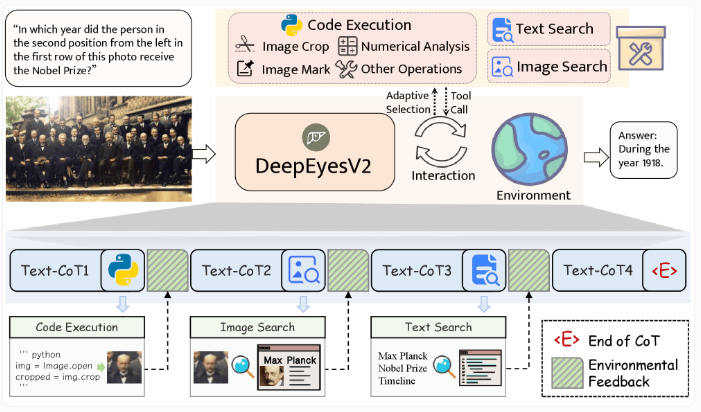
DeepEyesV2:小模型通过智能工具实现大模型级表现
DeepEyesV2作为一款创新的多模态AI模型,展现了小模型通过智能利用外部工具实现大模型级表现的潜力。该模型能够分析图像、执行代码并进行网络搜索,通过智能工具的组合使用,在多个任务中表现出色,甚至在某些情况下超越了更大的模型。
DeepEyesV2采用两阶段训练流程,结合图像理解与工具使用能力,在多个基准测试中表现优异。这一研究结果表明,模型的大小并非决定性能的唯一因素,智能工具的合理运用同样能够显著提升AI系统的能力。这一发现为AI模型的轻量化部署提供了新的思路,有望推动AI技术在资源受限设备上的应用。
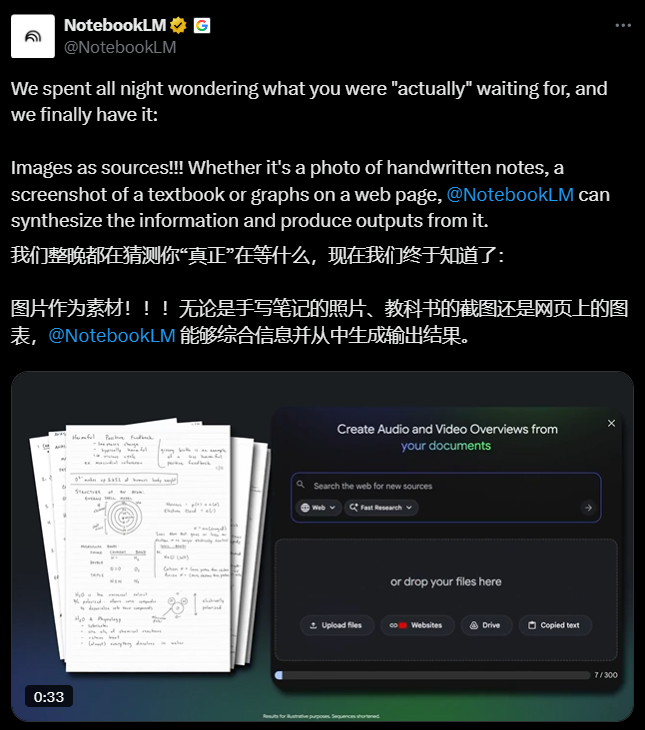
NotebookLM升级:图像导入开启知识管理新篇章
谷歌推出的NotebookLM新功能支持用户上传黑板板书、教科书扫描页或街拍表格,通过OCR与语义解析实现自然语言检索。这一创新将传统的静态笔记转变为可交互的知识库,大大提升了信息获取和管理的效率。
该功能面向全平台免费开放,未来还将增加本地处理选项以保护敏感数据。这一技术的推出,标志着AI在知识管理和教育领域的应用正在不断深化,为用户提供了更加智能和高效的信息处理工具。随着技术的不断进步,NotebookLM有望成为学习和工作中不可或缺的智能助手。
JetBrains DPAI Arena:AI编码智能体评估新标准
JetBrains推出的DPAI Arena作为首个开放式、多语言、多框架和多工作流的AI编码智能体基准测试平台,为AI工具在软件开发中的效率评估提供了统一标准。该平台支持多种编程语言和工作流程,能够公平、可重复地比较AI工具的性能,为开发者和企业选择合适的AI辅助开发工具提供了重要参考。
JetBrains计划将DPAI Arena项目交给Linux Foundation,以促进更广泛的技术指导和未来发展。这一举措有望推动AI编码工具的标准化和规范化,加速AI在软件开发领域的普及和应用。随着AI编程助手的不断涌现,建立统一评估标准对于行业的健康发展至关重要。
AI技术发展趋势与未来展望
综合分析近期AI领域的重大突破,我们可以清晰地看到几个明显的发展趋势:首先,大模型性能竞争日益激烈,国内外科技巨头纷纷推出具有国际竞争力的大模型;其次,多模态交互技术不断成熟,AI系统正从单一模态向多模态融合方向发展;第三,开源生态建设加速推进,AI技术的普及和共享成为行业发展的重要动力;最后,垂直场景应用不断深化,AI技术正从通用领域向专业领域渗透。
未来,AI技术将在以下几个方面继续突破:一是模型轻量化与高效部署,使AI能够在更多设备上运行;二是多模态交互的自然化,使AI系统更接近人类的感知和认知方式;三是垂直场景的专业化,针对特定行业和任务提供更精准的AI解决方案;四是安全与隐私保护的加强,确保AI技术的健康可持续发展。
结语
人工智能技术的快速发展正在深刻改变我们的生活方式和工作方式。从千问APP的国际竞争,到Veo 3.1的多图参考视频生成,再到超级小爱的随心修图功能,每一项创新都展示了AI技术的巨大潜力。随着技术的不断进步和应用场景的持续拓展,AI将在更多领域发挥重要作用,为人类社会带来更多可能性和机遇。
作为开发者和企业用户,我们需要密切关注AI技术的发展趋势,积极探索AI技术的应用场景,同时也要关注AI技术的安全与伦理问题,确保AI技术的健康发展。只有技术创新与人文关怀并重,才能真正实现AI技术的价值,为人类社会创造更美好的未来。








