
人工智能领域正经历前所未有的技术革新,各大科技公司纷纷推出突破性AI模型,推动行业边界不断拓展。本文将深入剖析近期AI领域的重大进展,从百度文心5.0的全模态能力到可灵2.5Turbo的视频生成创新,从微博VibeThinker-1.5B的低成本突破到李飞飞World Labs的3D世界模型,全面解读这些技术如何重塑内容创作、交互体验和AI应用格局。
视频生成技术迎来可控性革命
可灵2.5Turbo模型的推出标志着AI视频生成技术进入新阶段。该模型在动态效果、文本响应精度、风格保持能力以及整体美学效果方面均有显著提升,尤其是其创新的"首尾帧"功能,为创作者提供了前所未有的视频控制能力。

技术突破点解析
可灵2.5Turbo模型的核心优势在于其精准的视频起点和终点控制能力。传统AI视频生成工具往往难以精确控制视频的初始和最终状态,而"首尾帧"功能允许创作者设定视频的起始画面和结束画面,AI则自动生成中间过渡内容。这一功能对于需要特定视觉效果的短视频制作、广告创意和动画设计具有重要价值。
此外,该模型在以下方面实现了突破:
- 动态效果优化:通过改进时序建模技术,使视频动作更加自然流畅
- 文本响应精度提升:更准确地理解文本描述并转化为视觉内容
- 风格保持能力增强:在整个视频生成过程中保持一致的艺术风格
- 美学效果改进:提升画面构图、色彩搭配和光影处理的专业性
行业应用前景
可灵2.5Turbo模型的技术突破将为多个行业带来变革:
- 内容创作:短视频创作者可快速生成高质量视频内容
- 广告营销:品牌方能够精准控制广告视频的关键帧
- 影视制作:辅助预览和制作动画效果
- 教育领域:创建生动的教学视频内容
随着AI视频生成技术的不断成熟,我们可以预见未来视频内容的生产效率将大幅提升,创作门槛也将显著降低,为创意产业带来新的发展机遇。
百度文心5.0:全模态AI的新里程碑
在2025年11月13日的百度世界大会上,百度正式发布了最新原生全模态大模型——文心5.0。这款拥有2.4万亿参数的AI模型,代表了当前AI技术发展的前沿水平,其原生全模态统一建模技术能够同时理解和生成文本、图像、音频和视频等多种信息,展现出强大的多模态能力。

技术架构创新
文心5.0采用了"原生全模态"技术架构,这意味着从模型设计的最初阶段就考虑了多模态信息的处理,而非简单地拼接不同模态的处理模块。这种架构带来了以下优势:
- 信息融合更自然:不同模态信息在模型底层实现深度融合
- 跨模态理解更精准:能够更好地理解文本与图像、音频之间的关联
- 生成能力更全面:可以同时生成多种模态的内容
- 计算效率更高:通过统一架构减少了模型冗余
性能表现分析
根据官方发布的数据,文心5.0在多个权威基准测试中表现出色:
- 语言理解能力:与国际顶尖模型相当
- 多模态理解能力:达到全球领先水平
- 图像生成能力:在细节表现和创意生成方面优势明显
- 视频生成能力:在时序一致性和内容连贯性方面表现优异
特别值得关注的是,文心5.0在处理中文内容方面具有独特优势,这使其在中文市场具有更强的竞争力。百度表示,该模型在中文理解、生成和文化背景把握方面进行了专门优化。
商业应用价值
文心5.0的推出将为多个行业带来变革性影响:
- 内容创作:帮助创作者快速生成高质量的多模态内容
- 智能客服:提供更自然、更智能的交互体验
- 教育培训:创建沉浸式的学习内容
- 医疗健康:辅助医学影像分析和健康咨询
- 工业设计:加速产品设计和原型制作
百度通过文心App向普通用户开放部分功能,同时通过千帆平台向开发者和企业用户提供API服务,形成了完整的应用生态。这种"技术+平台+应用"的三位一体模式,有望加速AI技术在各行业的落地应用。
微博VibeThinker-1.5B:小模型的颠覆性突破
在AI模型参数量不断攀升的今天,微博推出的VibeThinker-1.5B模型以其15亿的小参数量实现了令人瞩目的性能表现,挑战了"越大越好"的传统AI发展范式。该模型基于阿里巴巴的Qwen2.5-Math-1.5B进行了精细调整,并在多个开源平台免费提供,为AI技术的民主化进程做出了重要贡献。
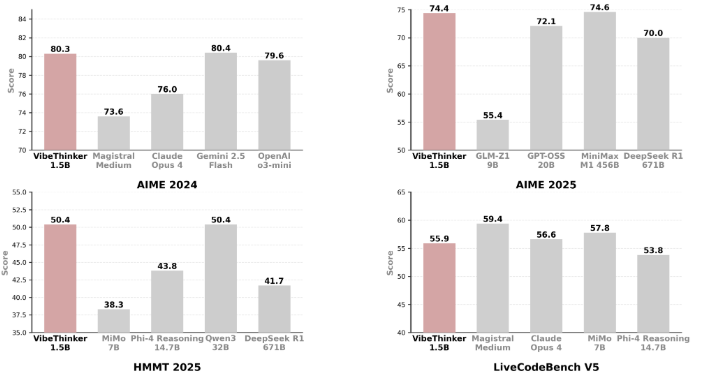
性能突破点
尽管参数量仅为15亿,VibeThinker-1.5B在多个测试中表现出色,甚至在某些任务上超越了拥有6710亿参数的DeepSeek的R1模型。这一现象颠覆了人们对AI模型规模的固有认知,证明模型效率和质量并不完全取决于参数数量。
特别值得注意的是,该模型在数学和代码任务上的表现尤为突出,这表明其训练方法可能更专注于特定领域的深度优化,而非追求通用能力的全面提升。
成本效益分析
VibeThinker-1.5B的后期训练成本仅为7800美元,远低于同类模型数十万美元的训练费用。这种极高的成本效益比,使得更多研究机构和中小企业能够参与到AI模型的研发和应用中,有助于打破AI技术被少数科技巨头垄断的局面。
训练框架创新
VibeThinker-1.5B采用了名为"谱-信号原则"的训练框架,这一创新方法通过优化信号处理和频谱分析技术,使小模型也能实现高效的推理能力。具体来说:
- 信号压缩:保留关键信息的同时减少冗余数据
- 频谱优化:在频域上进行更高效的参数训练
- 注意力机制改进:提升模型对重要信息的捕捉能力
- 知识蒸馏:从大模型中提取知识并应用到小模型
开源生态影响
微博将VibeThinker-1.5B在Hugging Face、GitHub和ModelScope等多个开源平台免费提供,这一举措对AI开源生态系统产生了深远影响:
- 降低研究门槛:使更多研究者能够接触和使用先进AI模型
- 促进创新协作:加速AI技术的迭代和优化
- 培养人才生态:为AI领域培养更多专业人才
- 推动应用落地:促进AI技术在各行业的实际应用
VibeThinker-1.5B的成功表明,未来AI模型的发展可能会呈现"大小结合"的多元化趋势,大模型负责通用能力,小模型专注于特定领域,形成互补共生的AI模型生态。
OpenAI GPT-5.1:个性化AI交互的新高度
OpenAI推出的GPT-5.1模型在语言表达、对话风格适应性和情绪感知方面实现了显著改进,为AI助手带来了更自然、更个性化的交互体验。该模型引入的自适应推理功能,能够根据问题复杂度动态调整处理时间和资源分配,进一步提升了AI助手的实用性和效率。
核心技术升级
GPT-5.1在以下几个方面实现了重要突破:
- 语言表达优化:更自然、更流畅的语言生成能力
- 对话风格适应性:能够根据用户偏好调整沟通方式
- 情绪感知能力:更好地理解用户情绪并作出适当回应
- 自适应推理:根据任务复杂度调整处理策略
这些技术升级使得GPT-5.1能够提供更加个性化和智能的交互体验,满足不同用户在不同场景下的需求。
用户体验提升
GPT-5.1在用户体验方面带来了显著改善:
- 响应速度提升:通过优化推理算法,减少了响应时间
- 对话自然度增强:使AI助手更像人类对话伙伴
- 个性化程度提高:能够记住用户偏好并据此调整交互方式
- 多场景适应性:在不同应用场景中都能提供合适的交互体验
竞争格局影响
GPT-5.1的推出进一步加剧了AI助手领域的竞争,迫使其他厂商加速技术迭代。同时,它也推动了AI助手向更加专业化、个性化的方向发展,为用户提供了更多选择。
李飞飞World Labs的Marble:3D世界模型的商用突破
李飞飞领导的World Labs发布了首款商用3D世界模型Marble,这一创新产品支持多种输入方式生成可编辑的3D环境,并具备AI编辑功能,兼容主流VR设备,为游戏开发、影视特效等多个领域带来了新的可能性。
技术特点解析
Marble模型的核心技术特点包括:
- 多输入支持:支持文本、图像、视频等多种输入方式生成3D内容
- AI编辑功能:内置智能编辑工具,简化3D场景设计流程
- VR兼容性:与主流VR设备无缝集成,提供沉浸式体验
- 实时渲染:支持实时预览和编辑,提高工作效率
应用场景拓展
Marble模型的应用场景广泛,包括:
- 游戏开发:快速创建游戏场景和角色
- 影视特效:生成和编辑3D场景,降低制作成本
- 建筑设计:可视化建筑设计和空间规划
- 教育领域:创建沉浸式学习环境
- 虚拟社交:构建虚拟社交空间
Marble的推出标志着3D内容创作进入AI辅助的新阶段,有望大幅降低3D内容创作的门槛,加速元宇宙和虚拟现实技术的发展。
东北大学NiuTrans.LMT:多语言翻译的重大突破
东北大学开源的NiuTrans.LMT大模型在多语言翻译领域取得重大突破,支持60种语言、234个翻译方向,尤其在低资源语言上实现显著进展。其创新的"双中心架构"打破了英语在翻译领域的主导地位,为跨文化交流提供了更公平、更高效的解决方案。
技术架构创新
NiuTrans.LMT采用的双中心架构具有以下特点:
- 中英双核心:以中文和英语作为翻译中心,避免二次失真
- 三层语言覆盖:核心语言、支持语言和低资源语言三层结构
- 低资源优化:专门针对低资源语言翻译进行优化
- 跨文化交互:更好地处理不同文化背景下的语言表达
性能优势分析
NiuTrans.LMT在多个翻译基准测试中表现出色:
- 翻译质量:在FLORES-200等权威测试中达到顶尖水平
- 低资源语言:显著提升低资源语言的翻译质量
- 文化适应性:更好地处理文化特定表达和习语
- 效率优化:通过两阶段训练提升翻译效率
开源生态贡献
东北大学将NiuTrans.LMT开源,为多语言翻译领域做出了重要贡献:
- 促进研究:为研究者提供高质量的多语言翻译模型
- 降低应用门槛:使更多应用能够集成高质量翻译功能
- 促进语言平等:提升低资源语言的数字化水平
- 推动标准制定:为多语言翻译技术提供参考标准
NiuTrans.LMT的成功表明,AI技术在促进语言平权和跨文化交流方面具有巨大潜力,有助于构建更加包容和多元的数字世界。
谷歌Gemini Live:语音交互的革命性升级
谷歌Gemini Live语音功能的升级通过五大核心能力将AI对话推向新高度,为用户带来更自然、个性化的交互体验。这一升级标志着语音AI技术进入了一个新阶段,为语音助手和语音交互应用带来了新的可能性。

核心能力升级
Gemini Live的五大核心能力包括:
- 语速控制:支持用户通过口令实时调整AI语速
- 个性化训练:支持个性化语言训练,适应不同用户需求
- 情绪感知:能够识别用户情绪并调整回应方式
- 口音适应:支持多种口音和方言,提升交互自然度
- 上下文理解:更好地理解对话上下文,提供连贯回应
用户体验革新
Gemini Live的升级为用户带来以下体验改善:
- 交互自然度:使语音交互更加接近人类对话
- 个性化程度:能够根据用户偏好调整交互方式
- 包容性增强:支持更多语言和方言,服务更广泛用户群体
- 效率提升:减少重复指令,提高交互效率
竞争格局影响
Gemini Live的升级对语音AI领域产生了深远影响:
- 技术标准提升:提高了语音AI的技术门槛
- 应用场景拓展:推动语音AI在更多场景的应用
- 用户体验重视:促使厂商更加注重用户体验
- 差异化竞争:为厂商提供了新的竞争维度
Gemini Live的升级表明,语音AI技术正从简单的语音识别向更自然的语音交互演进,未来语音将成为人机交互的重要方式之一。
阿里"千问"项目:C端AI的战略布局
阿里巴巴启动代号为"千问"的重大项目,旨在打造同名个人AI助手,全面对标ChatGPT。这一举措标志着阿里正式加入全球AI应用的顶级竞赛,并将C端AI应用推向战略核心,反映了大型科技公司在AI领域的战略布局。
项目战略意义
"千问"项目的启动具有以下战略意义:
- 市场布局:抢占个人AI助手市场先机
- 技术整合:整合阿里在云计算、电商、支付等领域的优势
- 生态构建:打造围绕AI助手的生态系统
- 品牌提升:通过AI创新提升品牌形象
技术基础优势
"千问"项目基于Qwen模型,具有以下技术优势:
- 中文优化:针对中文场景进行专门优化
- 多模态能力:支持文本、图像等多种模态
- 生态整合:与阿里云、阿里电商等生态深度融合
- 服务经验:基于阿里丰富的服务经验优化AI助手
商业模式创新
"千问"项目可能采用以下商业模式:
- 订阅服务:提供高级功能的订阅服务
- 生态增值:通过AI助手促进阿里生态内服务
- 广告变现:基于用户画像提供精准广告
- 企业服务:为企业提供定制化AI解决方案
"千问"项目的启动表明,阿里正将AI技术视为未来发展的核心驱动力,通过C端AI应用构建新的增长点。这一战略布局将影响整个AI产业的发展方向,推动AI技术与商业应用的深度融合。
AI技术发展的未来趋势
综合分析近期AI领域的重大突破,我们可以总结出以下几个关键趋势:
1. 多模态统一成为主流
从百度的文心5.0到各家的多模态模型,可以看出AI正从单一模态向多模态统一方向发展。这种趋势将使AI能够更好地理解和处理复杂信息,提供更全面的服务。
2. 模型效率与规模并重
微博VibeThinker-1.5B的成功表明,模型效率与规模同样重要。未来AI模型发展将呈现"大小结合"的多元化趋势,大模型负责通用能力,小模型专注于特定领域。
3. 开源生态日益重要
越来越多的AI模型选择开源,如VibeThinker-1.5B和NiuTrans.LMT。开源生态将促进AI技术的民主化,加速创新和普及。
4. 垂直领域应用深化
AI技术在垂直领域的应用将不断深化,如视频生成、3D建模、多语言翻译等。这些领域的突破将带来实际商业价值和社会价值。
5. 个性化与交互体验提升
从GPT-5.1到Gemini Live,可以看出AI交互正朝着更自然、更个性化的方向发展。未来AI助手将更好地理解用户需求,提供更贴心的服务。
结语
AI领域的快速发展正在重塑我们的生活方式和工作方式。从视频生成到多模态统一,从低成本模型到个性化交互,这些技术创新不仅展示了AI技术的巨大潜力,也为各行业带来了新的发展机遇。未来,随着AI技术的不断进步,我们将看到更多令人惊叹的应用和体验,AI将成为推动社会进步的重要力量。
面对AI技术的快速发展,我们需要保持开放和包容的态度,积极拥抱变革,同时也要关注AI技术的伦理和安全问题,确保AI技术能够造福人类社会。在这个充满可能性的AI时代,每个人都是参与者,也是见证者,共同开创AI与人类和谐共存的美好未来。








