
在人工智能技术飞速发展的今天,音频处理领域迎来了一项重大突破——阶跃星辰团队推出的全球首个开源原生音频推理模型StepAudio R1。这一创新成果不仅解决了传统音频模型在复杂推理中性能下降的问题,更为音频领域的多模态推理开辟了全新路径,为音频智能处理带来革命性突破。
什么是StepAudio R1
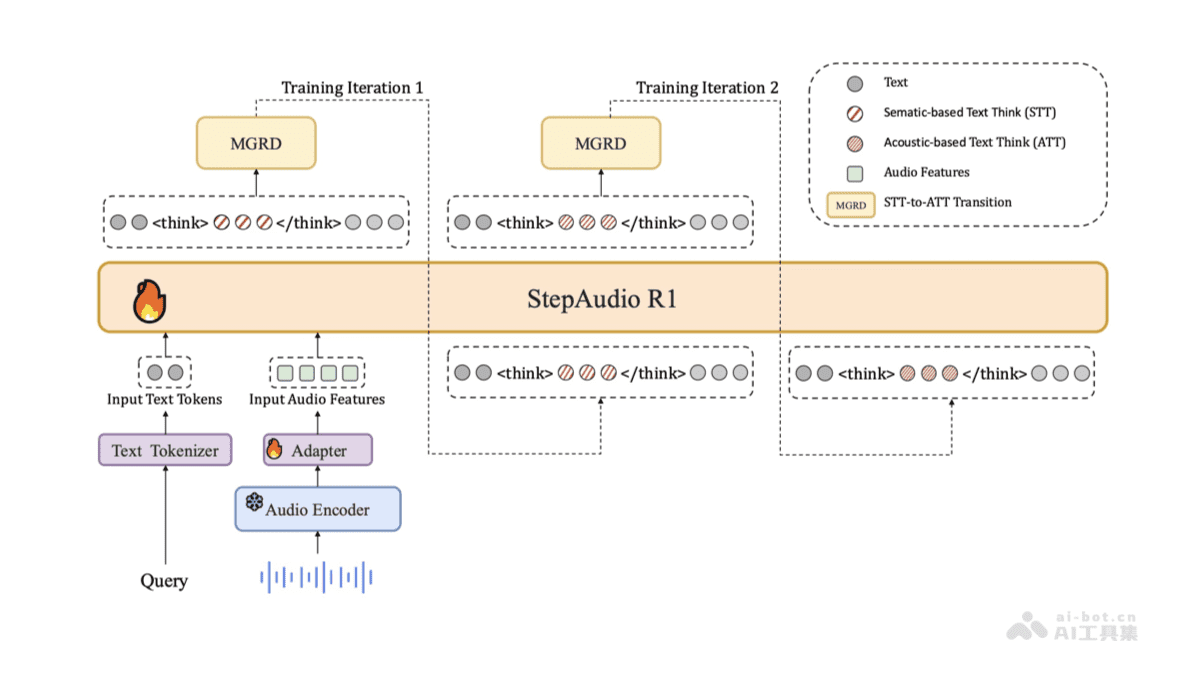
StepAudio R1是阶跃星辰团队精心打造的全球首个开源原生音频推理模型,它通过创新的模态锚定推理蒸馏(MGRD)框架,成功实现了基于声学特征的深度推理能力。在多项权威基准测试中,StepAudio R1的表现令人瞩目,不仅超越了Gemini 2.5 Pro的性能,更是达到了与最新一代Gemini 3相当的水平。
该模型最大的特点在于其极高的实时推理能力,评分高达96%,首包延迟仅为0.92秒,这使得它能够在实时对话和交互场景中保持卓越性能。StepAudio R1的出现,为音频领域的多模态推理开辟了新路径,在歌曲赏析、影视分析、访谈分析等场景中展现出巨大潜力,为音频智能处理带来革命性突破。
StepAudio R1的核心功能
复杂音频推理能力
StepAudio R1最引人注目的功能是其强大的复杂音频推理能力。传统的音频模型往往只能处理表面的声学特征,而StepAudio R1能够深入理解音频中的复杂信息,包括对话中的隐含意义、说话者的情感状态、人物特征推断等。这种深层次的推理能力使得模型能够捕捉到传统方法难以提取的微妙信息。
例如,在分析一段对话时,StepAudio R1不仅能够识别出字面意思,还能推断出说话者的真实意图、情感倾向以及可能的社会背景。这种能力对于需要深度理解音频内容的场景,如客服分析、心理咨询辅助等,具有重要价值。
卓越的实时推理性能
在实时性要求高的应用场景中,StepAudio R1表现出色。模型具备高达96%的实时推理评分,首包延迟仅为0.92秒,这意味着用户几乎可以立即获得模型的推理结果,无需等待。这一特性使得StepAudio R1非常适合实时对话系统、直播内容分析、实时会议记录等应用场景。
传统的音频处理模型往往需要在准确性和实时性之间做出妥协,而StepAudio R1通过创新的架构设计和优化算法,成功实现了两者之间的平衡,为实时音频处理提供了新的可能性。
多模态推理融合
尽管StepAudio R1专注于音频处理,但它并不局限于单一模态。模型保留了强大的文本推理能力,能够将音频与文本信息进行有效融合,成为多模态任务中的通用解决方案。这种多模态融合能力使得StepAudio R1在处理复杂场景时更具优势。
例如,在分析一段包含背景音乐的演讲时,StepAudio R1能够同时理解演讲内容的语义信息(通过文本推理)以及背景音乐的情感色彩(通过音频分析),从而提供更加全面和深入的理解。这种跨模态的推理能力是传统音频模型所不具备的。
情感与社会智能推理
StepAudio R1的另一个突出特点是其在情感与社会智能方面的推理能力。模型能够精确分析音频中的情感色彩、人物特质、社会关系等复杂信息,例如通过对话推断人物的心理状态、性格特征或社会身份。
这种能力对于需要理解人类情感和社会互动的应用场景具有重要价值。例如,在心理健康辅助领域,StepAudio R1可以帮助分析咨询过程中的情感变化,为心理咨询师提供客观参考;在教育领域,它可以分析教师讲课时的情感投入和学生的反应,帮助优化教学效果。
StepAudio R1的技术原理
模态锚定推理蒸馏(MGRD)框架
StepAudio R1的核心技术是模态锚定推理蒸馏(Modality-Grounded Reasoning Distillation,简称MGRD)框架。这一创新框架通过迭代的自蒸馏训练过程,将原本在文本模态中表现优异的推理能力,巧妙地转移到声学属性上。
传统音频模型面临的一个关键挑战是推理链与音频模态对齐不足的问题。文本模型通常能够构建清晰的推理链,但直接将这些能力应用到音频模态上往往效果不佳。MGRD框架通过特殊的训练机制,确保模型能够生成真正基于声学特征的推理链,而不是简单地依赖文本转录或其他模态的替代方案。
音频特征提取与对齐
StepAudio R1首先通过先进的音频特征提取技术,从原始音频中提取关键特征,包括语调、节奏、情感色彩、说话风格等。这些特征不是简单的统计量,而是具有语义含义的高级表示,能够捕捉到音频中的丰富信息。
提取的音频特征随后通过MGRD框架与推理任务进行精确对齐。这一过程确保了模型的推理过程始终基于音频本身的特性,而不是依赖于文本转录或其他模态的间接信息。这种直接基于声学特征的推理方式,使得StepAudio R1在处理纯音频内容时表现尤为出色。
多模态融合技术
尽管StepAudio R1专注于音频处理,但它并不排斥其他模态的信息。相反,模型设计了巧妙的多模态融合机制,使得它能够有效整合音频和文本信息,在保持音频处理优势的同时,不损失文本推理能力。
这种多模态融合能力是通过特殊的注意力机制和特征对齐技术实现的。模型能够在不同模态之间建立有意义的联系,例如将音频中的情感表达与文本中的语义内容进行关联,从而提供更加全面和准确的理解。
StepAudio R1的应用场景
音乐赏析与创作辅助
在音乐领域,StepAudio R1展现出巨大的应用潜力。模型能够深入分析歌曲的旋律结构、和声进行、节奏模式等音乐元素,同时理解歌词的情感色彩和语义内容。这种全面的音乐分析能力可以帮助音乐爱好者更好地理解音乐作品的内涵,也可以为音乐创作提供灵感和技术支持。
例如,音乐教育工作者可以利用StepAudio R1分析不同风格音乐的特点,帮助学生更好地理解音乐理论;音乐制作人可以使用模型分析流行歌曲的成功要素,为自己的创作提供参考;音乐评论家则可以借助模型获得更加专业和深入的音乐分析视角。
影视对话分析与内容理解
影视作品中的对话往往包含丰富的情感信息和角色关系。StepAudio R1能够精确分析这些对话内容,推断角色的情感状态、性格特征和相互关系,帮助观众更深入地理解剧情和角色发展。
在影视制作领域,StepAudio R1可以辅助编剧分析对话的自然度和情感表达;在影视评论领域,它可以为评论家提供更加专业和客观的分析视角;对于观众来说,模型可以帮助他们发现作品中隐藏的细节和深层次含义,提升观赏体验。
访谈内容分析与信息提取
访谈内容通常包含大量有价值的信息,但也往往结构松散,关键信息分散。StepAudio R1能够分析访谈中的关键信息、情感倾向和逻辑结构,自动提取访谈要点,生成结构化的摘要和分析报告。
在新闻媒体领域,记者可以利用StepAudio R1快速整理采访内容,提取关键引言和观点;在学术研究方面,研究人员可以使用模型分析访谈数据,发现研究主题和受访者态度;在企业应用中,HR部门可以利用模型分析面试记录,评估候选人的特质和潜力。
学术演讲分析与知识提取
学术演讲往往包含复杂的逻辑结构和专业知识。StepAudio R1能够帮助研究人员分析学术报告中的逻辑结构、论证过程和关键信息,提升学术表达和知识管理效率。
在学术研究领域,学者可以利用模型分析学术会议中的演讲内容,快速把握研究前沿和热点;在教育领域,教师可以使用模型分析自己的讲课效果,找出改进空间;对于学生来说,模型可以帮助他们更好地理解课堂内容,提取关键知识点。
情感分析与心理辅助
通过分析音频中的语调、节奏和词汇选择,StepAudio R1能够准确判断说话者的情绪状态(如高兴、悲伤、愤怒等),甚至能够识别出说话者可能没有明确表达的情感倾向。
在心理健康领域,心理咨询师可以利用模型分析咨询过程中的情感变化,为诊断和治疗提供客观参考;在客户服务领域,企业可以使用模型分析客户来电的情感状态,及时调整服务策略;在人际交往中,模型可以帮助人们更好地理解他人的情感需求,改善沟通效果。
StepAudio R1的技术优势与未来展望
相比传统音频模型的突破
StepAudio R1相比传统音频模型实现了多项技术突破。首先,它解决了传统音频模型在复杂推理任务中性能下降的问题,实现了基于声学特征的深度推理。其次,模型通过MGRD框架实现了推理能力从文本模态到音频模态的有效迁移,突破了传统方法的局限性。此外,StepAudio R1在保持高推理准确性的同时,实现了极低的延迟,满足了实时应用的需求。
开源生态的推动作用
作为全球首个开源的原生音频推理模型,StepAudio R1的发布对整个AI音频领域具有里程碑式的意义。开源模式不仅降低了研究门槛,促进了技术交流,还能够吸引全球开发者的共同参与,加速技术迭代和创新。
通过开源,阶跃星辰团队希望构建一个活跃的音频AI社区,鼓励研究者基于StepAudio R1进行二次开发和应用探索,共同推动音频AI技术的发展。这种开放合作的理念,有望催生出更多创新应用和解决方案。
未来发展方向
尽管StepAudio R1已经取得了令人瞩目的成果,但音频AI领域仍有巨大的发展空间。未来,StepAudio R1可能会在以下几个方面进一步发展:
多语言支持扩展:目前模型可能主要针对特定语言或语言家族进行了优化,未来可以扩展对更多语言的支持,特别是低资源语言。
跨模态能力增强:进一步探索音频与其他模态(如视频、图像)的深度融合,开发更加全面的多模态理解系统。
领域专业化:针对特定应用领域(如医疗音频分析、法律语音处理等)进行专业化优化,提升在垂直领域的应用效果。
边缘部署优化:进一步优化模型大小和计算效率,使其能够在边缘设备上高效运行,拓展应用场景。
个性化适应能力:开发模型对特定用户或场景的适应能力,通过少量样本学习实现个性化音频理解。
结语
StepAudio R1的推出标志着音频AI技术进入了一个新的发展阶段。作为全球首个开源的原生音频推理模型,它不仅实现了技术上的重大突破,更为整个领域的发展注入了新的活力。通过创新的MGRD框架和卓越的性能表现,StepAudio R1为音频智能处理开辟了全新路径,在音乐、影视、访谈、学术分析等多个领域展现出巨大应用潜力。
随着开源生态的不断完善和应用场景的持续拓展,StepAudio R1有望推动音频AI技术走向更加成熟和普及的阶段,为人类与音频信息的交互方式带来革命性变化。对于开发者和研究者而言,StepAudio R1不仅是一个强大的工具,更是一个创新平台,将激发更多关于音频智能的思考和探索。








