
在智能手机市场日趋激烈的今天,中国电信与三星电子再度携手,共同推出新一代高端商务智能手机——心系天下三星W26,以16999元的起售价进军顶级商务手机市场。这款产品不仅是双方合作18年来的第18代作品,更代表着折叠屏技术与商务应用的全新高度。
传承与创新的完美结合
自心系天下三星W系列首款产品发布至今,三星电子与中国电信一路同行,携手见证18代辉煌历程。作为行业内合作共赢的典范,18年来,双方共同推出一代又一代的标杆之作,将心系天下三星W系列打造为高端市场历久弥新的经典符号。

心系天下三星W26在传承经典的同时,带来了多项创新突破。仅215克的整机重量较前代产品减轻约40克,折叠状态下机身厚度仅8.9毫米,展开后更薄至4.2毫米,实现了轻薄与坚固的完美平衡。
精工细作:材质与设计的艺术
心系天下三星W26在材质选择上可谓精益求精。外屏盖板和机身背板均采用康宁®大猩猩®玻璃陶瓷2材质,兼具温润手感与耐久特质。这种材质不仅提供了出色的抗刮擦性能,还赋予了手机独特的触感体验。
机身边框以升级版增强型装甲铝材质锻造,覆以立体方格花纹装饰,坚韧稳固而不失精巧。超薄精工装甲铰链以精妙机械结构进一步提升折叠形态的可靠性,同时也能淡化折痕,让屏幕视野更为清朗。

在色彩设计上,心系天下三星W26以"玄曜黑""丹曦红"两款全新配色带来更具东方气质的形象。玄曜黑,恰似夜幕下的浩瀚宇宙,低调深邃,沉静中散发悠然神韵;丹曦红,犹如传统器物的华美漆彩,瑰丽典雅,映照出流光溢彩的雍容气度。这两种色彩不仅体现了东方美学,更彰显了商务人士的品味与格调。
强劲性能:骁龙8至尊版赋能
心系天下三星W26搭载骁龙8至尊版移动平台(for Galaxy),NPU、CPU与GPU全面升级,为智能体验提供充沛动力。这款旗舰级处理器不仅带来了卓越的性能表现,还优化了能效比,确保手机在长时间使用中依然保持流畅。
在全新Samsung One UI 8的加持下,Galaxy AI与折叠形态深度契合,赋予心系天下三星W26崭新的智慧交互。6.5英寸(直角)外屏与8.0英寸(直角)内屏相辅相成,既能快速、高效地处理信息,也能为分屏交互、多任务并行开辟广阔天地。
AI革命:重新定义智能交互
心系天下三星W26最大的亮点之一是其全面的AI功能升级。借助多模态AI技术,Bixby也迎来升级,面对复杂语音指令也可做到使命必达,还能将多份文档凝练成内容摘要,甚至延展为思维导图,成为工作中的可靠智囊。
在创意层面,Bixby可根据指令创作纯音乐。语聊视界模式更将语音与视频交互融会贯通,赋予Bixby视觉洞察与信息联动的能力,使信息获取直观明晰。
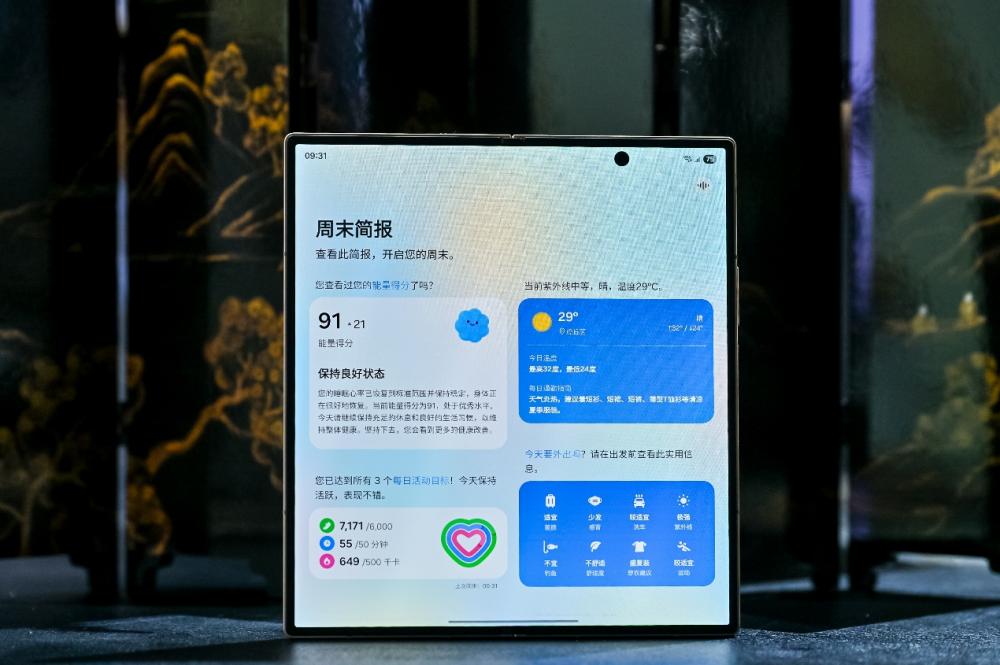
在日常使用与商务场景中,心系天下三星W26也能依托AI之力洞察需求,提升效率:
- 即时简报:整合天气、日程与健康等重要数据
- 即圈即搜:支持AI解题,囊括多学科领域,只需圈选题目,便可获得条理分明的解题思路
- 会议助手:通过字幕助手与翻译屏幕两项功能,使会议记录与外文资料的阅读更加高效
- 智能拖放与智能收藏:让跨应用协作行云流水
影像系统:2亿像素专业级拍摄
影像方面,心系天下三星W26搭载由2亿像素广角摄像头领衔的后置三摄系统,内、外屏均配备了前置摄像头,5颗镜头将日常拍摄场景全面覆盖,协助用户随时捕捉精彩瞬间。
2亿像素高分辨率传感器的细腻笔触配合增强型超视觉引擎,让每一次按下快门,皆能呈现生动的细节、丰润的色彩、通透的肌理和自然的光影。全新升级的1000万像素内屏前置镜头,以宽广视野纳入更多笑颜,让合影不再局促,更以高性能传感器与智能算法合力呈现真实肤色与光感,令人像照片更具神采。
在高规格影像系统的加持之外:
- 照片助手:能够洞察画面元素,实现移动、擦除与角度调整,缺失之处亦能自然延展
- AI头像:为人像与宠物照片赋予多样风采,使影像作品在写实之外更具个性
- 音频橡皮擦:可精细分辨不同音源,无论环境噪声还是人声对白,皆可随心掌控,赋予视频作品更为专业的声音质感
卫星通信:突破地域限制
值得一提的是,心系天下三星W26还支持天通卫星通信,兼容卫星通话与短信服务,借助增强的硬件性能与优化算法,即便身处户外无地面网络覆盖的环境,亦能通过卫星系统与外界保持畅联。这一功能对于经常出差或前往偏远地区的商务人士来说,无疑是一项重要的安全保障。

市场定位与价格策略
心系天下三星W26 16GB+512GB版本建议零售价16999元,16GB+1TB版本建议零售价18999元。这一价格定位使其直接与市场上其他顶级旗舰产品竞争,针对的是追求极致体验的高端商务用户。
销售渠道方面,10月11日17点,三星W26将在抖音心系天下旗舰店、三星商城、三星京东自营官方旗舰店、天猫三星官方旗舰店、三星手机苏宁自营旗舰店、抖音三星官网旗舰店等线上渠道、线下授权三星门店以及其他授权门店正式开启预约。10月17日全渠道正式开售。
行业影响与未来展望
心系天下三星W26的推出,不仅是对三星W系列18年传承的致敬,更是对折叠屏手机技术的一次重要突破。其创新的设计、强大的性能、全面的AI功能以及专业的影像系统,都重新定义了高端商务手机的标准。
随着5G技术的普及和AI技术的不断发展,智能手机正朝着更加智能、更加个性化的方向发展。心系天下三星W26作为这一趋势的代表产品,为用户提供了前所未有的智能体验,也为整个行业树立了新的标杆。
结语
心系天下三星W26的推出,标志着中国电信与三星电子在高端商务手机领域的合作进入了一个新的阶段。这款产品不仅融合了最新的科技与设计理念,更体现了对商务用户需求的深刻理解。在竞争激烈的智能手机市场中,心系天下三星W26凭借其独特的定位和卓越的性能,有望在高端商务手机市场占据一席之地,为三星W系列的辉煌历程再添浓墨重彩的一笔。








