
在数字社交时代,我们每天都会与无数在线互动对象交流,但你是否曾想过,那些过于礼貌、完美的回复可能来自AI而非真实人类?最新研究揭示了一个令人意外的现象:AI模型在社交媒体对话中,竟然比人类更难伪装出真实的情绪表达。
研究背景:计算图灵测试的诞生
2025年11月,苏黎世大学、阿姆斯特丹大学、杜克大学和纽约大学的研究人员联合发布了一项突破性研究,他们开发了一种被称为"计算图灵测试"的新方法,用于评估AI模型在多大程度上能够模拟人类的语言表达。与依赖主观判断的传统图灵测试不同,这种方法通过自动分类器和语言分析技术,识别出区分机器生成内容和人类创作文本的具体特征。

研究团队由苏黎世大学的Nicolò Pagan领导,他们测试了九个大型语言模型,包括Llama 3.1系列、Mistral 7B、Qwen 2.5、Gemma 3等,在Twitter/X、Bluesky和Reddit三大社交平台上的表现。研究结果令人惊讶:即使经过各种优化策略,AI生成的回复仍能以70-80%的准确率被识别为非人类。
核心发现:毒性表达成为AI的致命弱点
研究中最引人注目的发现是:AI模型在模拟人类社交互动中的"毒性表达"方面存在根本性困难。当研究人员要求AI模型对真实用户的社交媒体帖子生成回复时,AI生成的内容在毒性评分上明显低于真实的人类回复,在所有三个平台上都呈现出这一一致模式。
"即使经过校准,大型语言模型的输出在情感语调和情感表达方面仍明显区别于人类文本,"研究团队在报告中写道。"AI模型难以捕捉人类社交媒体中常见的随意负面表达和自发性情感表达。"
平台差异与AI模仿能力
研究还揭示了不同社交平台之间的差异:
- Twitter/X的AI回复最难被识别(检测准确率最低)
- Bluesky居中
- Reddit的AI回复最容易被识别
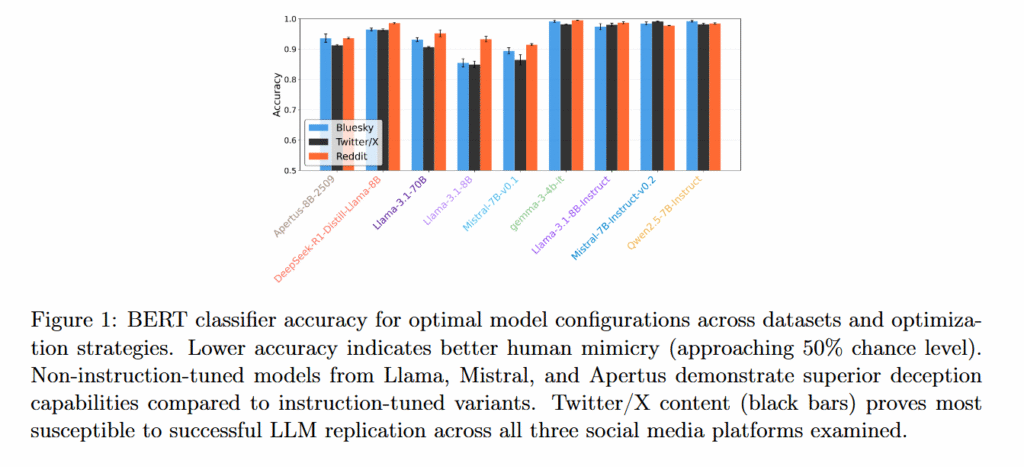
这种模式反映了各平台独特的对话风格以及这些平台数据在模型原始训练中的重要性。Twitter/X的对话风格可能更接近AI训练数据,使其能够更好地模仿人类表达。
优化策略的意外结果
研究人员尝试了多种优化策略来提高AI的人类模仿能力,结果却出人意料:
- 简单优化优于复杂优化:提供用户过去的帖子示例或检索相关上下文,比复杂的个性描述和模型微调更有效
- 指令微调反而降低表现:经过额外训练以遵循用户指令和表现得有帮助的指令微调模型,实际上在模仿人类方面表现更差
- 模型大小无关紧要:700亿参数的Llama 3.1与80亿参数模型的表现相当或更差
"我们的综合校准测试挑战了'更复杂的优化必然产生更类人输出'的假设,"研究人员总结道。
情感表达的困境
研究揭示了一个根本性矛盾:当AI模型被调整以避免检测,匹配人类写作风格时,它们偏离了人类对同一帖子的实际回应(语义相似度从中位数0.18-0.34下降到0.16-0.28)。相反,当优化以匹配人类回应内容时,AI文本更容易被识别为人工生成。

这一发现表明,当前AI架构中,风格上的人类相似性和语义准确性代表了"竞争而非 aligned 的目标"。AI在模拟人类情感表达方面面临持久限制,检测率远高于随机水平。
对AI发展的启示
这项研究对AI开发领域提出了重要挑战和机遇。尽管研究人员持续努力使AI模型听起来更像人类,但真实的人类在社交媒体上不断证明,真实性往往意味着混乱、矛盾和偶尔的不愉快。
研究结果表明,AI模型在捕捉自发性情感表达方面存在根本性困难,这不仅是技术限制,也反映了人类交流的复杂性和不可预测性。AI可能能够模拟这种输出,但这比研究人员预期的要困难得多。
社交媒体真实性的新思考
随着AI技术的普及,社交媒体真实性面临新的挑战。这项研究提醒我们,在评估在线互动的真实性时,过度礼貌和完美的回应可能反而是AI的标志。真实的人类交流往往包含不完美、矛盾和情绪波动,这些恰恰是当前AI模型难以完全模仿的特质。

未来研究方向
基于这些发现,研究人员建议未来AI开发应重点关注:
- 改进对自发性情感表达的模拟
- 平衡风格相似性和语义准确性
- 开发更有效的毒性表达和负面情感生成技术
- 考虑不同社交平台的独特语言特征
结论
这项研究不仅揭示了当前AI模型的局限性,也为理解和改进AI与人类交流提供了新视角。在追求AI人类相似性的道路上,我们可能需要重新思考"真实"的含义,以及技术如何才能真正理解并模拟人类交流的复杂性。
随着AI技术的不断发展,这项研究将成为评估和改进AI社交能力的重要基准,提醒我们:在数字社交的世界里,不完美和真实性往往比完美和礼貌更具说服力。








