
Google如期兑现承诺,于2025年12月推出第二个Android 16版本,率先向Pixel设备推送此次更新。这一版本延续了Google从年度单一发布转向双版本更新的战略调整,带来了多项针对用户体验的改进,特别是AI驱动的通知系统和更灵活的定制选项。
双版本更新战略:Android 16的新常态
自2008年首次推出Android系统以来,Google一直遵循每年发布一个主要版本的策略。然而,Android 16标志着这一重要转变,将单一大型更新拆分为两个部分。今天的更新是Android 16时代的第二部分,但与六月份的第一版相比,变化相对较小。正如预期,六月份的首次更新带来了更多实质性改变,而此次第二版更新主要针对Google的Pixel设备,同时包含一些面向开发者的次要改进。
这一双版本策略反映了Google对移动操作系统开发方法的重新思考。通过将重大功能分散到两个发布周期,Google能够更频繁地向用户推送新特性,同时给予开发团队更灵活的时间窗口来完善和测试功能。这种模式也使Google能够根据用户反馈快速调整后续更新内容,提高整体用户体验。
AI驱动的通知系统:信息过载的解决方案
在此次Android 16第二版更新中,Google的AI功能可能是最重要的变化。系统将利用AI技术处理两项通知任务:总结和组织。具体而言,Android 16将使用AI对长对话内容进行总结,并将这些处理后的通知显示在通知栏中。值得注意的是,所有通知数据处理都在设备本地完成,不会上传到任何服务器,这既保护了用户隐私,又确保了处理速度。
在通知面板中,折叠的通知行将显示整个对话的摘要,而不是单个消息的片段。当用户展开通知时,才会显示完整对话内容。这种设计既节省了屏幕空间,又让用户能够快速了解通知的重要性。
此外,Google还表示AI将帮助减少Android 16中的通知过载问题。这一功能建立在第一个Android 16版本的通知分组基础上,通过收集低优先级通知并将它们静默来减轻用户的信息负担。这些通知将被组织成批次,如新闻和促销信息,用户可以在方便的时候再查看,而不必被持续打扰。
Material 3 Expressive:视觉体验的全面升级
Material 3 Expressive功能今年早些时候已登陆Pixel设备,但并未作为首个Android 16升级的一部分推出——这反映了Google目前与Android版本关系的复杂性。无论如何,此次更新后,Material 3在Pixel设备上的体验将更加统一和连贯。
Google现在将自动为设备上的所有图标应用Material主题,用主题友好的版本替换传统的彩色图标。类似地,深色模式将支持更多应用程序,即使开发者没有明确添加支持。Google还增加了几种新的图标形状选项,让用户能够个性化自己的主屏幕,打造独特的视觉体验。
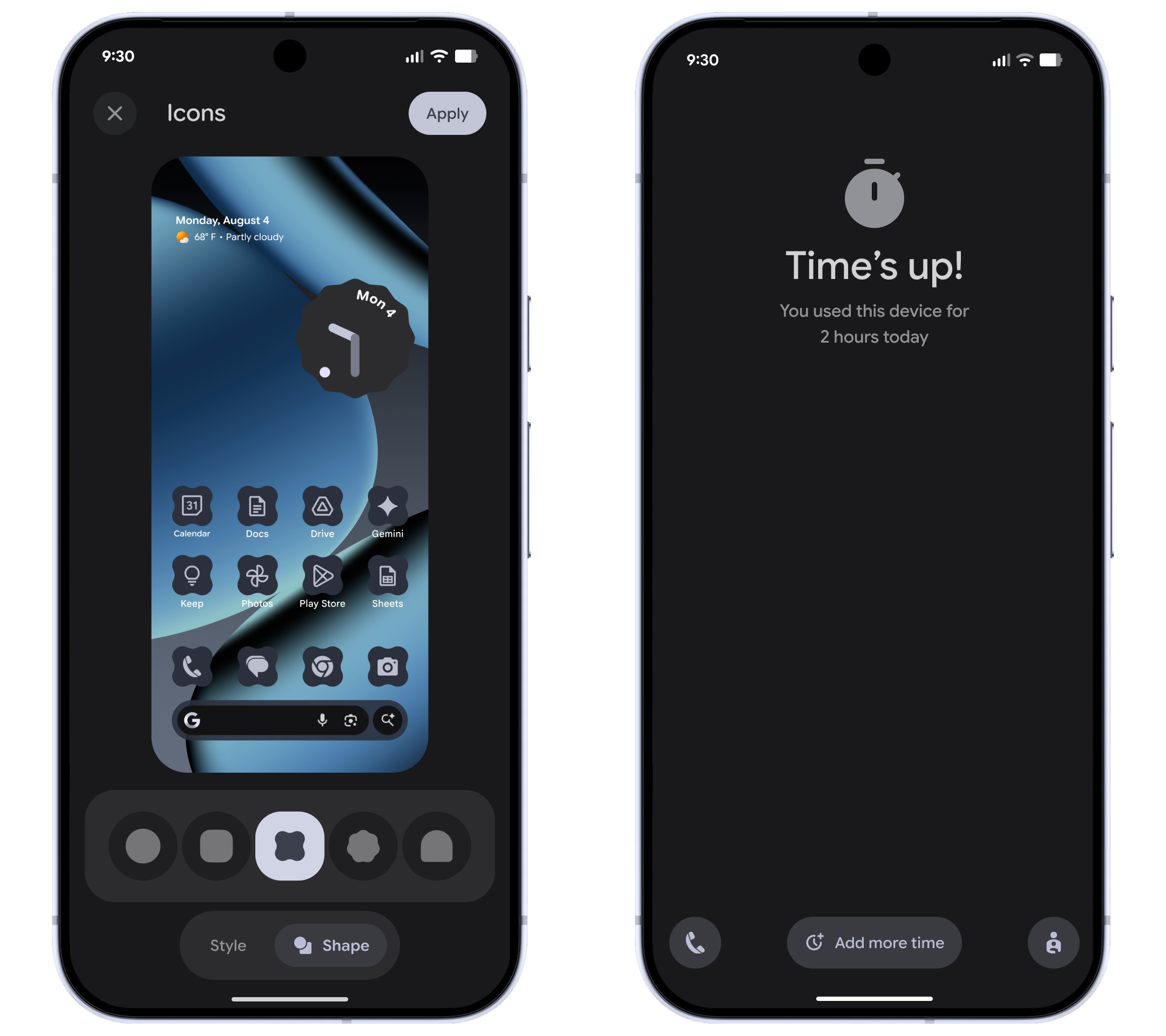
这种视觉上的改进不仅提升了美观度,还增强了用户界面的一致性和可识别性。通过统一图标风格和扩展深色模式支持,Google正在努力为用户提供更加舒适和一致的视觉体验,无论他们使用何种应用程序。
简化的家长控制:更便捷的家庭管理
在功能变化方面,Google添加了一种更直观的家长控制管理方式——用户可以直接在受管理设备上进行设置。父母现在可以为访问屏幕时间、应用程序使用等功能设置PIN码,而无需切换到其他设备。如果需要更多选项或控制,新的设备内设置也将帮助用户配置Google Family Link。
这一改进显著简化了家长控制流程,使父母能够更轻松地管理子女的设备使用。通过在设备上直接进行设置,Google消除了以往需要在多个设备间切换的不便,提高了家长控制的实用性和可访问性。
Android生态系统的通用改进
即使您不是Pixel用户,Google也为所有支持的Android设备捆绑了一系列应用和系统更新,这些更新将从今天开始陆续推出。
Chrome for Android的标签固定功能
Chrome for Android获得了更新,增加了标签固定功能,这一功能在桌面版本中早已存在。用户现在可以将常用标签固定在浏览器界面中,方便快速访问,提高浏览效率。
Google Messages的防骚扰功能
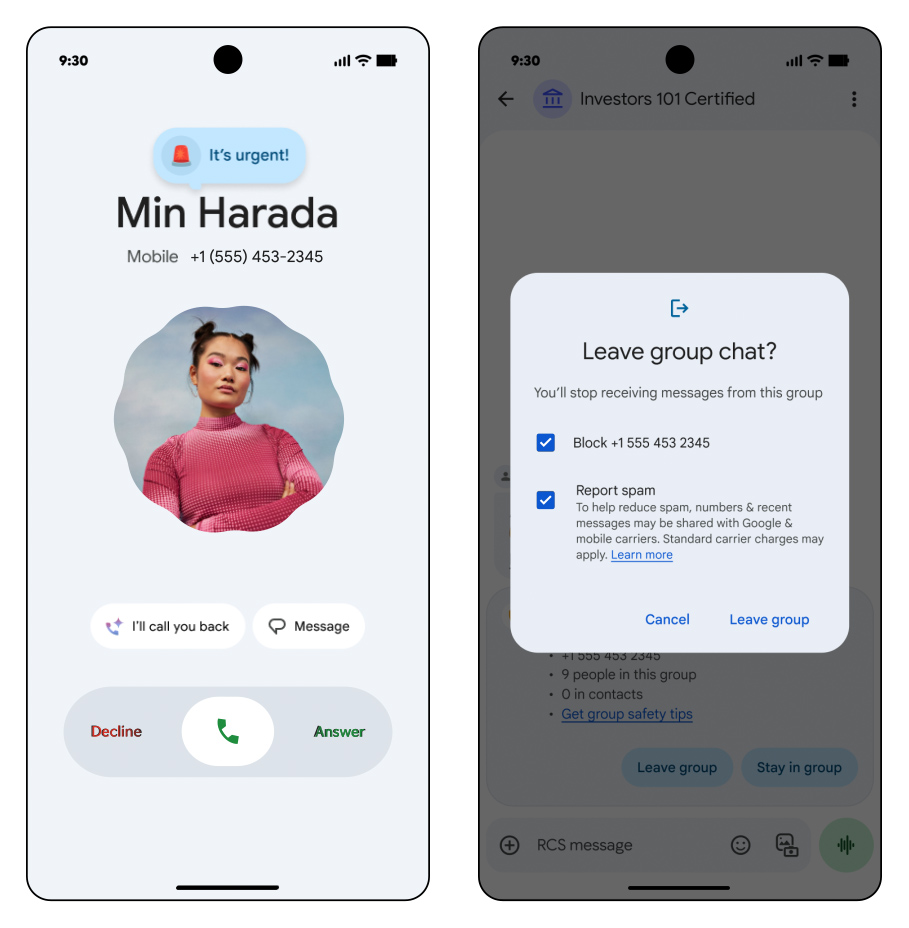
Google Messages应用也解决了一些明显的问题。当用户被新号码邀请加入群聊时,应用将显示群组信息并提供一键选项来离开群聊并将其标记为垃圾信息。这一功能有效帮助用户避免不必要的骚扰和垃圾信息。
Google拨号器的通话原因标记
虽然Google的官方拨号器应用预装在Pixel设备上,但它也可以通过Play Store供任何人下载。如果用户和联系人使用Google拨器,他们将很快能够使用"原因"进行通话。用户可以将通话标记为"紧急",以提醒收件人不应将其转至语音信箱。如果错过了紧急通话,紧急标签也会保留在通话历史记录中。
Circle to Search:AI驱动的防诈骗功能
Google还表示正在添加另一个AI驱动的功能来阻止诈骗。Circle to Search在大多数现代Android手机上可用,允许用户突出显示任何遇到的内容以检查是否存在诈骗风险。不过,其准确性仍有待观察。此功能连接到AI概览,以评估风险并提供建议。
无障碍功能的增强
Android设备还获得了一系列新的无障碍选项。使用带AutoClick鼠标的用户现在可以设置自定义悬停时间。用户还将能够通过双指点击在Gboard中启动TalkBack语音控制。通过语音控制手机UI的Voice Access也变得更加易于使用。用户不再需要点击来启动它,而是可以通过语音告诉手机的Gemini助手"启动Voice Access"。
Gemini在Guided Frame中的应用
Gemini也出现在Google的Guided Frame相机功能中,但这一功能仅限于Pixel设备。Guided Frame通过提供对框架内内容的语音描述,帮助视力低下或无视力的人拍照。借助新更新,Guided Frame将使用Gemini来总结拍摄内容的描述。这应该能够提供更详细的描述,并且希望不会出现太多幻觉。
更新时间表与设备兼容性
广泛可用的Android功能更新将在未来几周内推出。Pixel用户应该会在类似的时间框架内开始收到新Android 16构建的更新通知。Google的开发者网站上也将提供手动更新文件。非Pixel手机将在原始设备制造商(OEM)准备好时获得新的Android 16,但可能与Google为Pixel宣布的功能重叠不多。
这种分阶段的更新策略反映了Google在功能推广上的务实态度。通过先向Pixel设备推送更新,Google能够确保核心功能在自家硬件上完美运行,然后再将这些功能扩展到更广泛的Android生态系统。这种方法既保证了用户体验的质量,又为OEM厂商提供了足够的时间来适配和优化这些功能。
Google移动操作系统战略的转变
Android 16的双版本更新策略代表了Google移动操作系统战略的重大转变。从年度单一发布到双版本更新,这一变化反映了Google对移动操作系统开发方法的重新思考。通过更频繁的更新周期,Google能够更快地将新功能带给用户,同时给予开发团队更灵活的时间窗口来完善和测试功能。
这一战略调整也与整个科技行业的发展趋势相呼应。随着移动技术日益成熟,用户对操作系统的期望也在不断提高。更频繁的更新不仅能够满足用户对新功能的需求,还能够帮助Google保持其在移动操作系统领域的竞争优势。
结论:Android 16第二版的意义
Android 16第二版的发布不仅是Google对双版本更新承诺的兑现,更是其移动操作系统战略调整的重要一步。通过引入AI驱动的通知系统、增强Material 3 Expressive和简化家长控制等功能,Google正在努力提升用户体验,同时为未来的移动操作系统发展奠定基础。
对于普通用户而言,此次更新带来了更智能的通知管理、更个性化的视觉体验和更便捷的家庭控制功能。对于开发者而言,这些新功能提供了更多创新的可能性,同时也要求他们不断优化应用以适应新的操作系统环境。
随着Android 16第二版的推出,Google正在向市场展示其对移动操作系统未来的愿景:更智能、更个性化、更用户友好。这一愿景不仅将影响Pixel设备,还将逐渐渗透到整个Android生态系统,最终改变数十亿用户使用智能手机的方式。

